Fast KV Compaction via Attention Matching
Zweiger KV compaction
goal
Compact the KV cache for T tokens Into a KV cache of effectively like t tokens Want to avoid gradient-based optimization like what cartridges does, for speed
You’re hoping that the attention output for an arbitrary query, and with any new user input tokens that have been added to the KV cache since compaction, Is roughly preserved to be the same as it would have been before compaction: 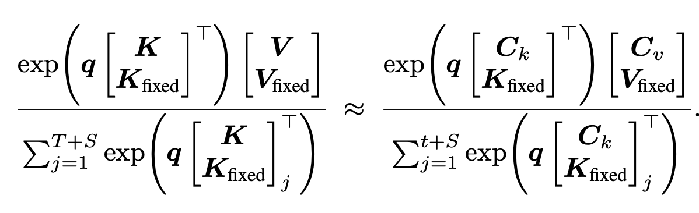
- both numerator and denominator are scalars
- q is 1xd (d is the attention dimension)
- The numerator can be rewritten as sum_{j=1}^(T+S) exp(q_j K_j) V_j
- Hence, you can actually write this as a weighted combination of local attention outputs (the numerator looking thing) and local attention masses (the denominator looking thing)
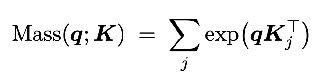
Except you can’t hope to match the local original attention output and attention masses exactly. E.g., if you get a query of zero, you’re screwed. So they add one more bias term: 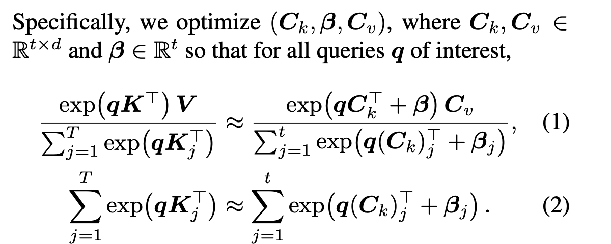
- Without the bias term, you systematically underestimate the compacted blocks’ contribution.
Methods
Reference Queries
Need to construct a “training set” of queries
Repeat-prefill (fast): Basically, process the prompt f”{context} Repeat the previous context. {context}” And take the queries that you get from doing that.
- Somehow the model is paying attention to the context, so this is representative of the type of queries you’re going to get.
Self-study:
- Ask questions about the context.
- Takes longer.
Do compaction and construction of reference queries layer by layer so that your queries stay “on policy”.
Given C_k, finding beta and C_v
beta: Take equation (2) from above, and reparameterize w_j = exp(beta_j), and since you know everything else in the equation, it just becomes a simple linear system which you solve by nonnegative least squares 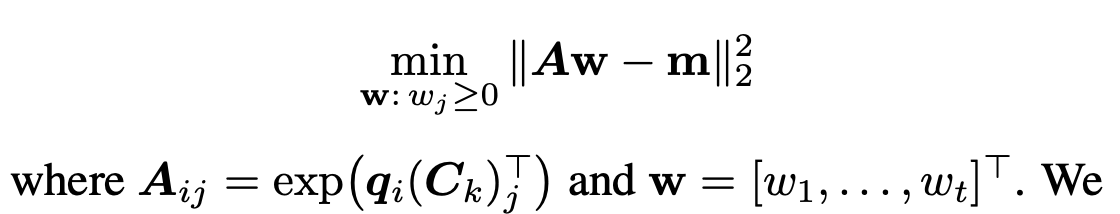 C_v:
C_v:
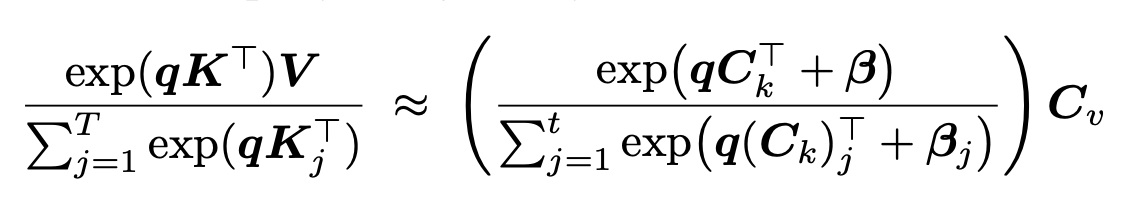
Finding C_k
restrict to taking a subset of the existing keys
- The keys with the highest attention scores (RMS average across the reference queries)
- Use orthogonal matching pursuit to find the subset of keys that minimizes the squared error for equation (2) (This is their algorithm (1))
Non-uniform compaction
- Different layers have different optimal compression ratios.
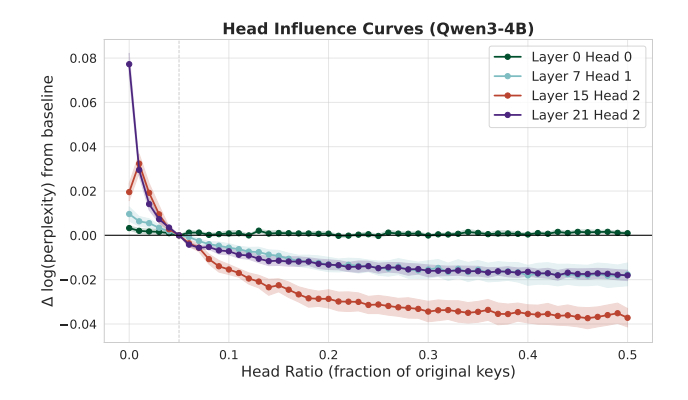
- They allocate a fixed KV budget across the layers by greedily swapping key value allocation between layers in a way that improves performance.
- Only have to calculate this allocation this once and can then use it for all data sets. It doesn’t change very much.
chunked compaction
two methods:
- Pre-fill everything (I.e., calculate all the keys and values) and then compact different chunks independently and concatenate them. This is slower but more accurate.
- Pre-fill and compact the chunks separately. Misses Cross-Chunk Interactions
Experiments
Vary using OMP vs highest attention value and NNLS to select C_k and beta Vary speedups to OMP Vary reference queries used
- GQA gives you multiple reference queries per kv
Compared to cartridges and summarization and a few others Data: QUALITY and LongHealth
Compact once, then answer all the questions using that compaction 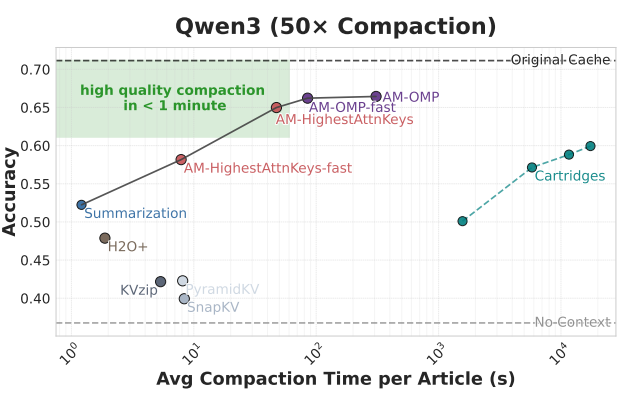 The different methods define the Pareto Frontier.
The different methods define the Pareto Frontier.
sliding window attention: only compacting the global attention layers on Gemma-3-12B, which you would expect to be more costly because these should encode dense attention patterns doesn’t do that much worse.
ablations: Wow, the head budget matters a lot, and the on-policy layers thing doesn’t really matter.
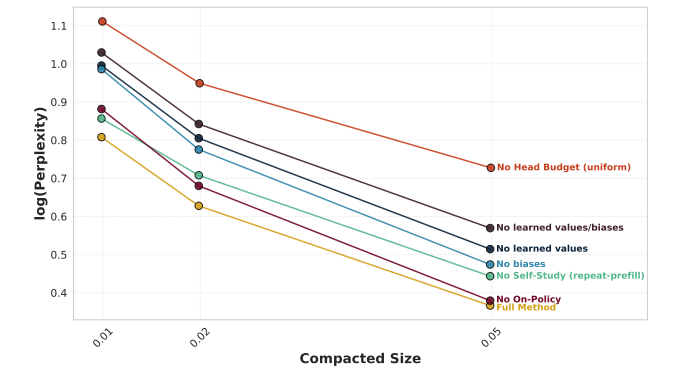 what a conclusion LMAO
what a conclusion LMAO 