What’s in the Image? A Deep-Dive into the Vision of Vision Language Models
VLM QA mech interp
Overview: give a VLM an image and query “describe the image” and have it generate text. Discover that query tokens contain high level image information that’s used to generate the answer (experiments via attention knockout)
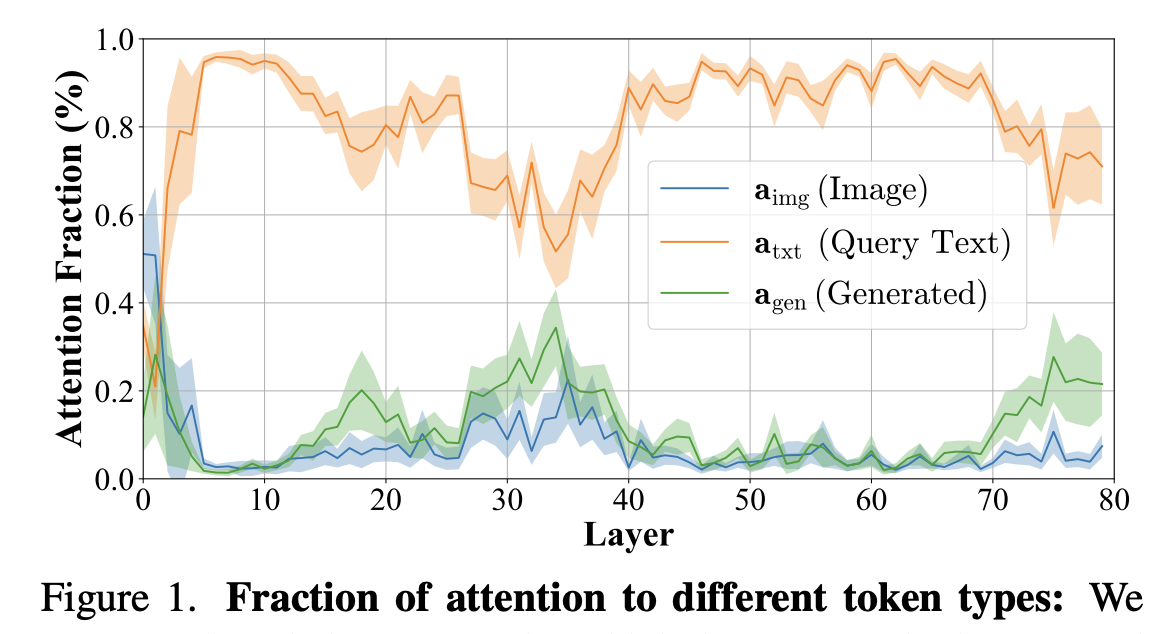
- Figure 1: strangely, the generated text pays a lot of attention to the query tokens and not the actual image tokens where the information about the answer should be
Attention Knockout Experiments
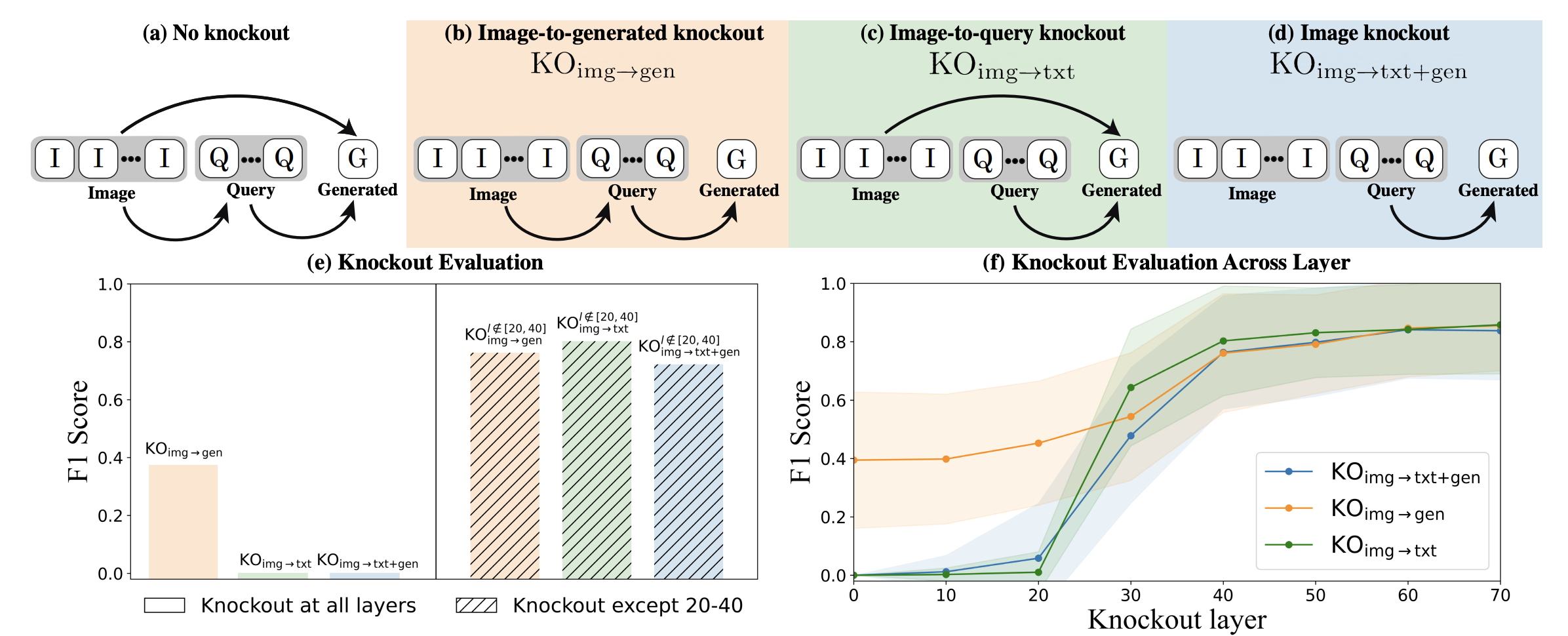
- Figure 2. Top row: Attention knockout is literally just masking out the attention paid by certain tokens to other tokens (i.e. masking pre-softmax).
- (e): attention from img -> generation isn’t consequential, while attention from img -> query is. Especially the middle layers (they do an experiment knocking out all but those layers)
- Figure 3: they evaluate the counterfactual response by using an LLM as a judge to figure out what objects are in the original and counterfactual responses, and then calculating the F1 score for which objects were identified by the counterfactual
Object localization

- Figure 6: For all of the generated tokens that are in the original but disappear under img -> gen knockout, they look at the attention heat maps in the middle layers for the generated token corresponding to that object.
- They compared the maximum attention (I think this is vanilla attention) area to masks generated by SAM2 and found that it’s pretty good.
-
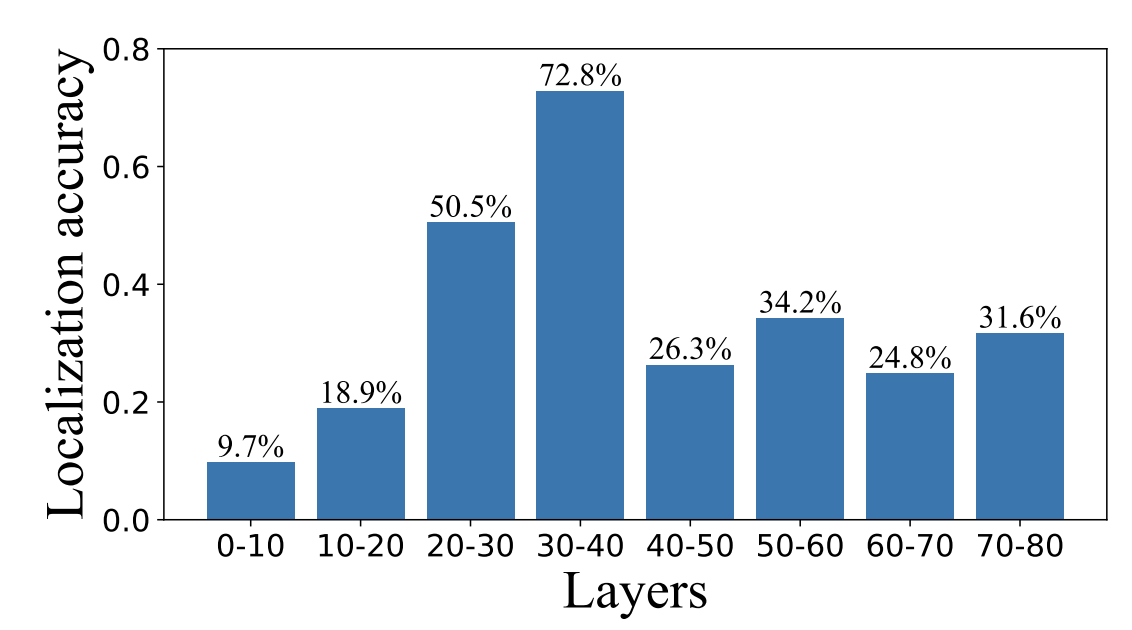
- Figure 7 showing that this does work best in the middle layers, implying object localization happens in the middle layers
Their Efficient Visual Processing application is literally just taking the top K activating image attention tokens and then for future queries, only using those tokens.