Learning to Discover at Test Time
TTT-Discover
setting:
- continuous optimization discovery (i.e. exhibit some example with highest/lowest number)
- RL’ing on a single problem, except with the goal of producing a single state, rather than a policy
Why can you hope to improve here beyond just PPO / GPRO on the reward itself?
- Basically, you don’t need to worry about being consistent, since you just need to get one good state. This will later allow us to do things like
- Optimize maximal reward rather than expected reward. This helps find extreme examples for obvious reasons
- not initialize from a fixed initial distribution (Imagine a Roomba. It has to initialize from its home charging port), which lets us extend our effective horizon.
In line with this motivation, they change two things about their RL process: their objective function, and how they choose what state to initialize from
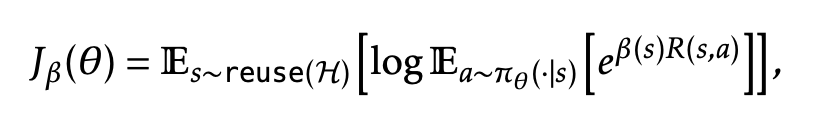
- Just the expected soft maximum reward over actions (instead of the expected reward over actions)
- it’s an interpolation between the max function (which is an upper bound, trivially) , and the expectation (lower bound by jensen)
- Why “entropic”? It doesn’t seem to be literally maximizing an entropy term. idk answer to this, gemini’s answer seems suspect
But I think the more interesting interpretation comes from the gradient of this objective 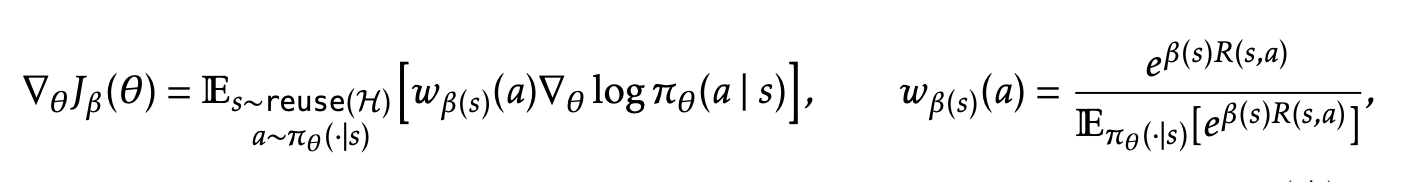
- Same as in PPO and GRPO, TTT-Discovery is a policy-gradient RL method: the update steps look like
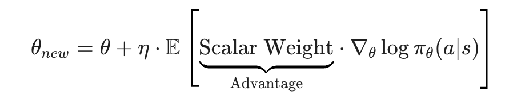
- only difference is that in GRPO, the advantage is linear ish
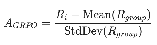
- while here, it’s exponential (w is exponential normalized)
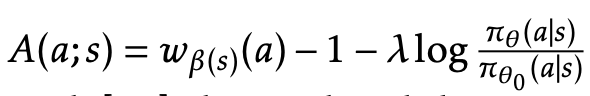 . This moves us much more towards the extreme examples (recall point b from earlier), and helps keep rewards alive once they’ve started saturating. I think this is key idea #1 in the paper. Literally just do your RL updates exponentially proportional to reward to bias more towards extreme examples. Disturbingly simple.
. This moves us much more towards the extreme examples (recall point b from earlier), and helps keep rewards alive once they’ve started saturating. I think this is key idea #1 in the paper. Literally just do your RL updates exponentially proportional to reward to bias more towards extreme examples. Disturbingly simple. - -1 is analogous to subtracting the mean in GRPO, just want to downweight actions that are below the mean performance, upweight ones that are above the mean
- the other term is the standard KL anchor in policy gradient methods to keep the policy from drifting too far
- Apparently setting the temperature beta is finicky, because in the beginning when the differences are big, you don’t want to update too far in one direction, while near the end the rewards are all the same so you don’t want your advantage to go to 0. Apparently they dynamically set beta to make the KL divergence between the old and new policies exactly 2
PUCT state initialization: some bs heuristic for which state to start from. You want to start from states that
- Led to states that have maximal reward (Not highest expected reward)
- Are themselves high reward (rank wise in the buffer)
- Have not been started from (or from a child of theirs) as often.
gpt-oss-120b on Tinker is such an interesting choice. Can’t help but feel like they’re limiting themselves by doing this instead of implementing it manually themselves with like a better open source model
Results
- math optimization results don’t seem that impressive. Does worse than alphaevolve on one, matches on circle packing, slightly improves on others
- I’m most impressed by the kernel gpu engineering result. The qualitative analysis that it takes the same high level approach but is better at fusing together complex kernels is interesting. And the fact that it generalizes to MI300’s without being trained on them is nice
- The algorithm development optimization thing is ok. I feel like as a human, I too would struggle to find a bunch of random heuristic optimizations combined together that do best. This does feel pretty bitter lesson pilled.
- for the bio result, I talked to my friend, and apparently people just haven’t tried very hard in these problems because there’s no commercial incentive
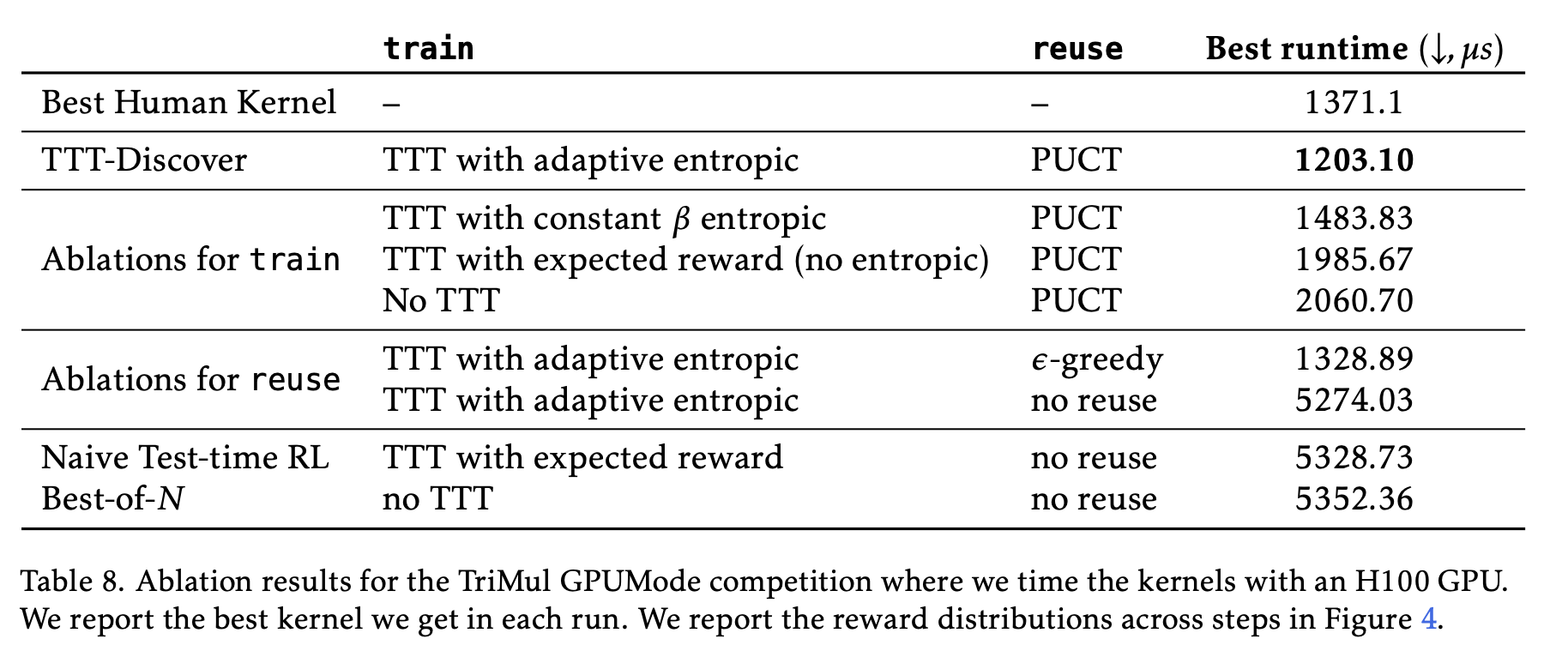
section 4.5 they have some nice ablations