Training Agents Inside of Scalable World Models
Dreamer v4
Section 3 Architecture and Training
Their actual models are their tokenizer (video frames –> representation) and Interactive Dynamics Model (actions, timestep/noise level, noised representations –> clean representations
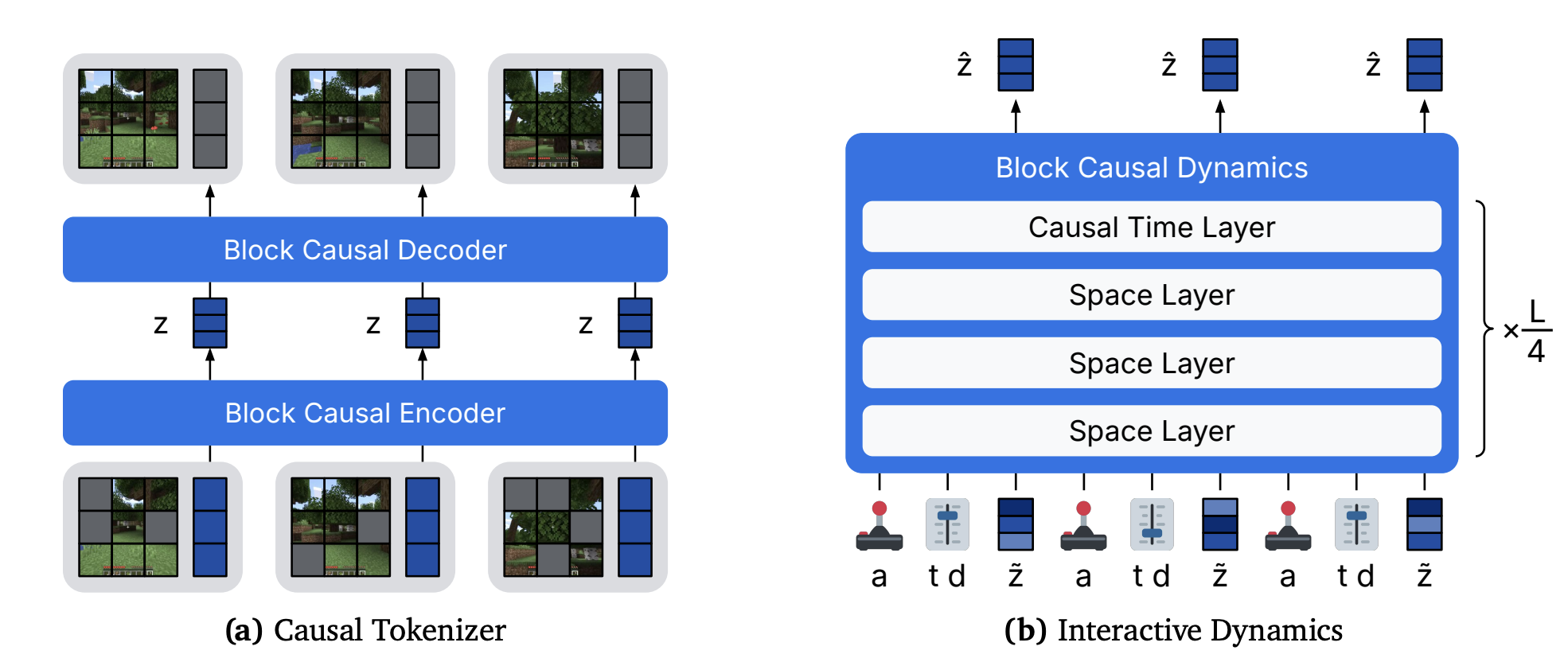
- Inputs are sequences: A bunch of frames (time step t) that each consist of a bunch of token types (image, action, noise level). Block causal means that it’s only causal for the frame-by-frame token blocks.
- Tokenizer and dynamics models share the same architecture but different weights
Tokenizer
- takes in image tokens + learned latent tokens
- encoder, discard patch tokens, compress dimension of latent tokens —> representation
- decoder: project back up,!get new (learned) embeddings for patch tokens, decode, only keep patch tokens.
- Reconstruction loss and LPIPS
Dynamics model
- Inputs are patch tokens, action tokens, timestep/noise level token, and register tokens.
- Trained with shortcut forcing (shortcut learning + diffusion forcing)
- Shortcut learning is just for larger step sizes than the minimum step size: the model takes in the step size d as an input, so it’s trained to do larger steps. Don’t use the flow matching objective. Use a distillation loss. This allows them to do only four-step generation later.
- Diffusion forcing is when you train for different noise levels for different frames. That way during inference time you can denoise autoregressively with the last frame fully noised but previous frames only lightly noised.
Transformer Architecture
architecture is a 2D transformer with time and space dimensions
Blocks look like [space, space, space, time] × L/4
- Spatial attention (“space layer”): each frame’s tokens attend only within that frame.
- Temporal attention (“causal time layer”): each spatial position attends only across time at that same position
Imagination RL
Need all the RL goodies:
Agent tokens, reward and policy MLPs
adding agent tokens after pretraining is over
[ image tokens z_t ] [ action tokens a_t ] [ register tokens ] [ noise/step tokens ]
–> [ image tokens z_t ] [ action tokens a_t ] [ register tokens ] [ AGENT TOKEN ] [ noise tokens ]
- Agent tokens embedding is just a one-hot encoding of the task like “Mine a tree”
- Don’t let other tokens attend to the agent token, because we don’t want the dynamics model to be predicting state based on the task.
Use the output at the agent token position as the inputs to MLPs that predict the reward and policy (a factorized probability distribution over actions)
- known trick: predict for 8 time steps in advance.
-
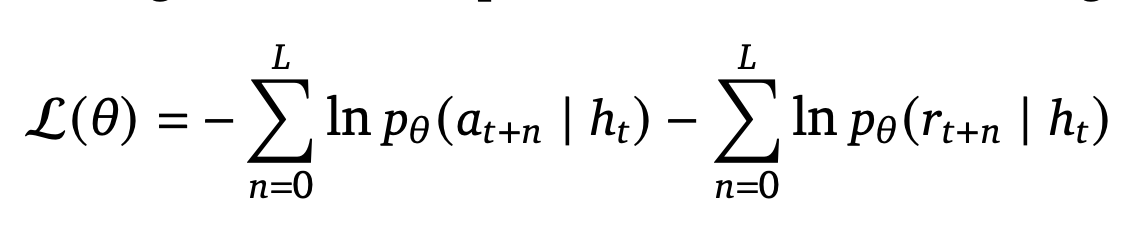 (reward and policy are literally trained via maximum likelihood)
(reward and policy are literally trained via maximum likelihood)

Actual RL Training
We add a third MLP for predicting the value V(s), which we need some kind of ground truth to train upon. How can we get those ground truths?
- We could Monte Carlo sample entire rollouts. This is high variance.
- We could use TD-learning, which says
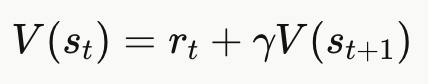 Is true even for our approximate values and only takes one step.
Is true even for our approximate values and only takes one step.
The paper does lambda learning, which interpolates between the two.
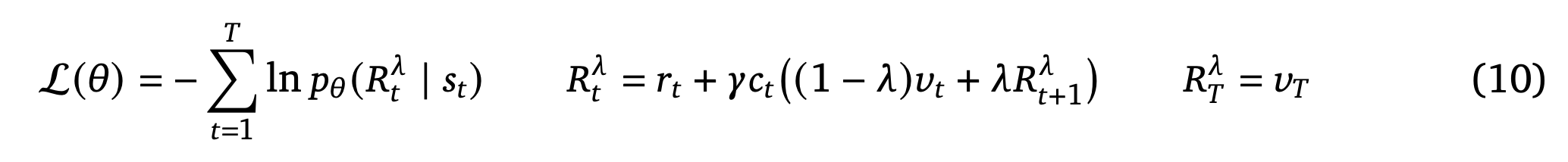
- In the parentheses term, you see the interpolation.
We use PMPO as the actual training algorithm for the policy, which apparently doesn’t use the magnitude of the advantages, only the sign. 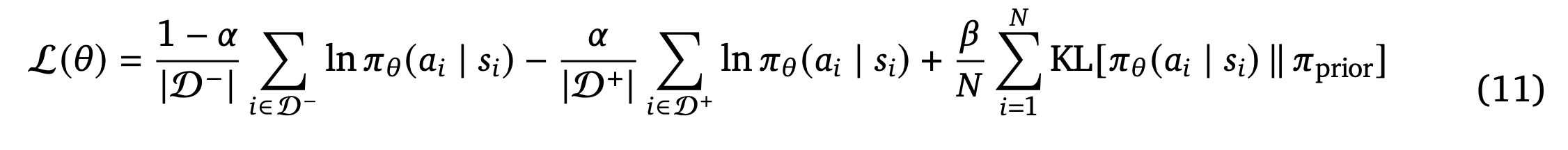
- Interesting note: apparently, the choice of whether to use KL or reverse KL is based on support of the distributions

Experiments
Successfully mines diamonds based on only offline training.
The world model itself is good enough for humans to be able to interact with.
You can actually get away with training mostly on unlabeled data and only need a small fraction to have labeled action conditioning.