Language Models use Lookbacks to Track Beliefs
lookback mechanisms
Goal: Understand how LLMs represent theory of mind (What does each character know?)
As you progress through the layers of computation, what is the residual stream of each token actually storing?
pervasive mechanism: the lookback mechanism. Some tokens act as source references, meaning that the question at the end of the day asks about these tokens, so these source references create IDs, and then these IDs (in later layers) get copied into both
- the residual streams of both the tokens that contain the actual answer
- the tokens in the question in the prompt.
This way, the question (as a query) knows to “look back” and pay attention to the token that contains the answer (as a key). See Figure 3
How did they test this hypothesis? They basically came up with a bunch of interventions, and checked that their hypothesis’s predictions matched the actual output. See the section on causal abstraction
Made their own CausalToM dataset
- Simple enough for LLMs to be able to solve
- Have counterfactual pairs so we can do more causal mediation

First, they had a motivating causal intervention (at the bottom after lookback mechanism bc I think it’s less important)
Desiderata-based patching via causal abstraction: causal abstraction: You have a causal model (pseudocode) for how you think the LM is implementing during the problem. You also map your causal model’s variables to specific layers of the model. Then, you do an intervention on a variable in your model and an intervention on the actual layer in the model, and you see whether the two interventions had the same results in your hypothetical model and in real life.
Desiderata-based patching (old technique, appendices D and F): Only intervene on specific subspaces of the residual stream.
- Do SVD on the residuals across many different examples.
- Learn a sparse binary mask over these singular vectors, so that intervening on this mask only maximizes agreement with the abstract causal intervention
Lookback mechanism
Figure 3. This is the key diagram. Keep referring back to this. 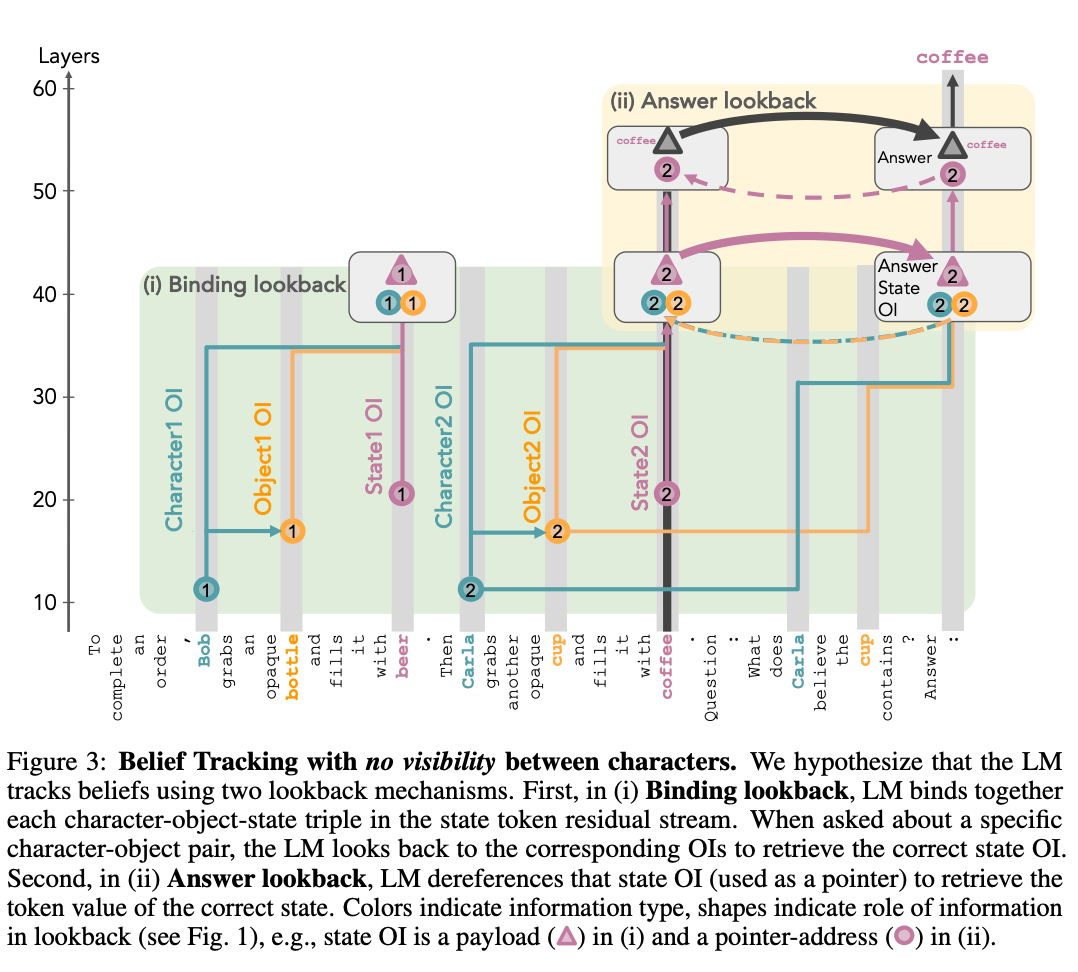
This is the abstract causal model of what’s going on.
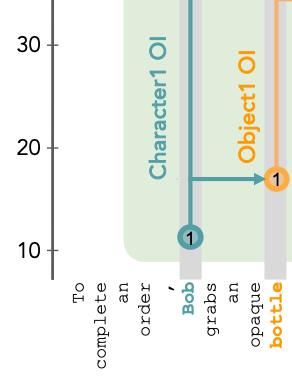
Binding lookback:
- When it gets to a character, or object, or state, it assigns a ordering ID (OI) based on which one it is. So for instance, Bob is character one, and Carla is character two.
- When it gets to the state, it brings over the OIs from the character and object, so that the character object state triple is co-located in the state token residual stream.
- Then, in the final sentence:
- The token for Carla and the tokens for Cup are quickly able to find their OI from the earlier occurrences of Carla and Cup, and bring that into their residual streams.
- The last token brings these two OIs from Carla and Cup into its residual stream.
- Now these two OIs act as a pointer that, when dereferenced, finds the coffee residual stream. And the OI for coffee is the payload that we retrieve.
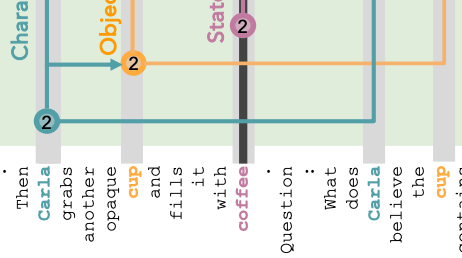
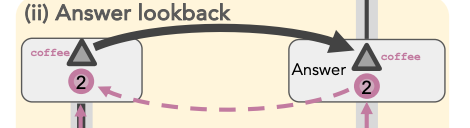
Answer lookback:
- Now the OI for coffee serves as a pointer instead of the payload. It points to where the OI for coffee is actually co-located with the state for coffee, and retrieves the answer of coffee as the payload.
Evidence for answer lookback: Method: Patching the last token. 
- From the original to the counterfactual, the order of Bob and Carla’s names are swapped, and the beverages also change.
- Observing what happens when you patch over the residual stream of the last token from counterfactual to original in different layers.
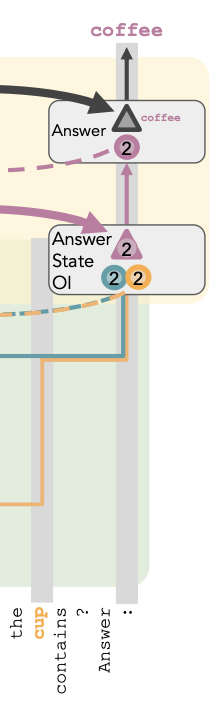
- In the causal abstraction, If you do the patching after the answer lookback, you should expect the answer from the counterfactual to already have been loaded. So the answer should be tea. On the right side of Figure 4, we see that this happens around past layer 56.
- If you do the patching before the answer payload is in, but after the answer pointer is already in, you should expect to see the beverage at the position of t, which is now beer. We see this for layers between 34 and 56.
- What is this proving? The last token contains location information earlier, and it contains the actual value information later, so it really does contain a pointer.
Evidence for/Localizing characters, objects, and states being linked in the state residual stream. Method: Patching the state token. 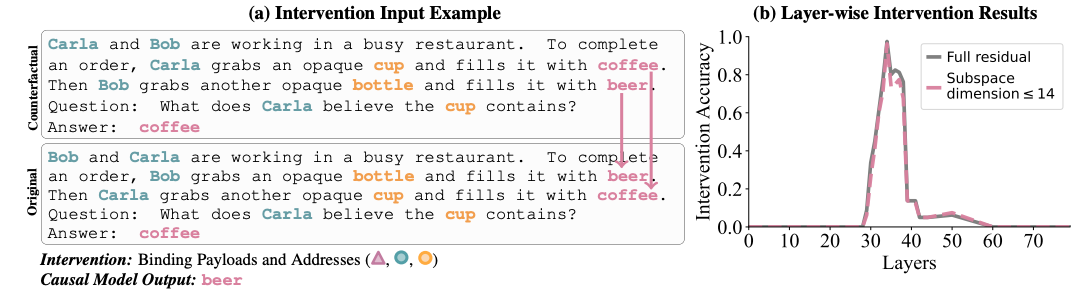
- Two prompts just have the sentence order swapped.
- Then they patch over the first state token in the counterfactual run to the second state token in the original run (I.e. both coffees), as well as both beers
- key part: According to their causal model, this patches over the address and payload values for each state token. So now in the original prompt, the beer token actually contains OI2 for character, object and state, and still has the state value “beer”
- The pointer for the last token still looks for OI 2 for character and object, so it uses the binding lookback and finds in the beer token residual stream that it should be looking for the state OI 2. And then when it dereferences that, it gets back “beer”
- The mistake was already mostly done by the time the last token paid attention to the beer token instead of to the coffee token.
- What is this proving? Somehow the patching made it so that instead of Carla and Cup getting you to the coffee token, it gets you to the beer token instead. So
- the state (beer) token contains information about the character and object.
- Furthermore, this information is generic, e.g. about order ID, instead of specific to Carla and Cup, since otherwise, it should have contained Bob and Bottle.
- layers 33-38 of the state token encode this
localizing Character and Object OI information source + Evidence that In the question, it actually uses character and object OI as a pointer. Method: Patching the character and object tokens. 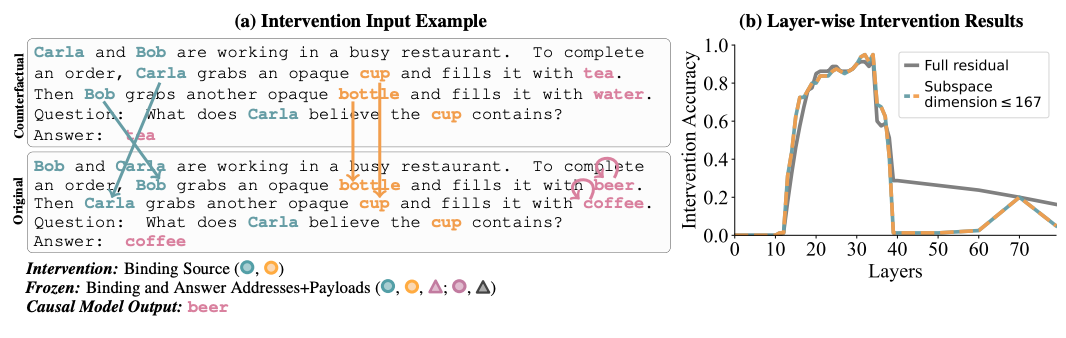
- Sentences swapped as before, but now beveridge is completely changed as well
- Beverage changing is subtle. We’ll come back to this later.
- They patch over the activations from the character and object, while freezing the activations for the state.
- If they didn’t freeze the activations for the state, the state “beer” would simply contain information about the new patched OIs for the character and object “Bob” and “bottle,” so it would just be as if we renumbered OI’s, and we’d get a normal answer
- So now, the last token sees that Carla and Cup now have patched OI 1 (this is the change from OI 2), so it looks at the beer token, and gets beer instead.
- Why do they have to swap the beverages out completely?
- Suppose that they kept tea instead of beer. The answer would have been tea. But now it’s not totally clear if by patching in Bob and Bottle, they somehow brought in information about tea.
- With beer, It must be the case that “Carla” and “Cup” in the last sentence read from the patched Carla and Cup in the second-to-last sentence, and that this patched Carla and Cup provided the location information about how to find the beer token
- What is this proving? The character and object tokens are the source of the OI that’s later found in the state token.
- layers 20-34 do this
“In summary, belief tracking begins in
- layers 20–34: where character and object OIs are encoded in their respective token representations.
- We know it’s happening because figure 6: patching these activations over (from the same word, so the main difference should be due to position) simply changes which state token the last token pays attention to
- Patching after layer 40 has no use because the OI has already been sent to the state token
- layers 33–38: These OIs are transferred to the corresponding state tokens.
- When a question is asked, pointer copies of the relevant character and object OIs are moved to the final token by layer 34, where they are dereferenced to retrieve the correct state OI. At the final token, this state OI is represented across layers 34–52

- and between layers 52–56, it is dereferenced to fetch the answer from the correct state token, producing the final output.”
Their (slightly more sketchy) causal model for when some characters can observe others’ actions.
Figure 7 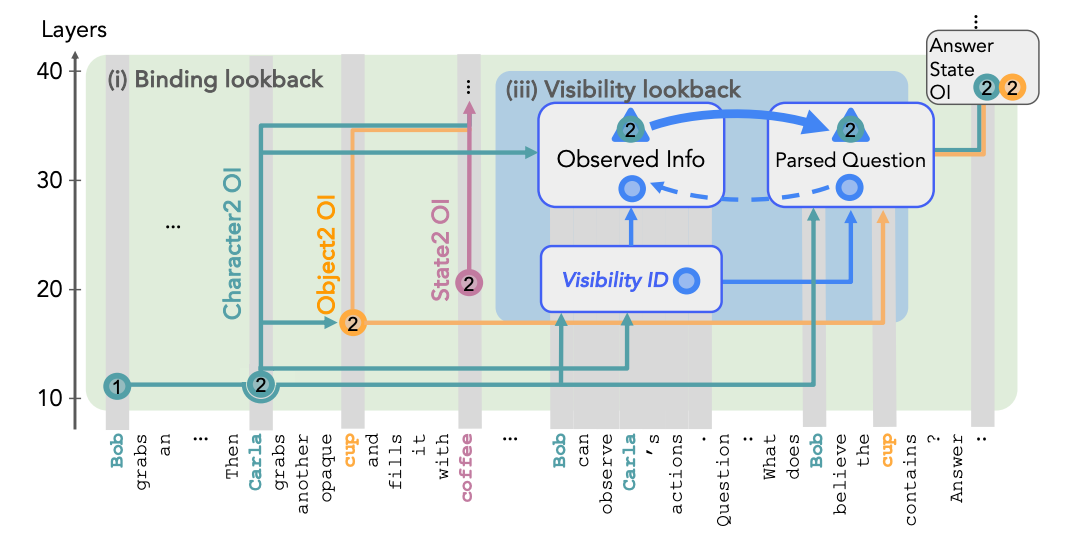
- Basically, there is a visibility ID in the tokens that gives the visibility information, which then gets copied into a pointer that goes to the actual lookback tokens in the question of the prompt; as well as an address that stays in those tokens
- They’re not as sure about the payload. They suspect that it’s the observed character’s OI.
Figure 8 
- Two of the same prompt, basically, with only visibility information changed
- I think it’s pretty important that the answer changes at least between water and coffee. Otherwise, you’re unsure if you’re just copping over water, instead of some lookback ID
- intervention 1 (blue): Patch the visibility sentence directly. They find that this only has an effect around layers 10 to 23, which is where they hypothesize the visibility ID to be formed in Figure 7. After that, a copy has already been sent off to the Lookback tokens.
- intervention 2 (red): patch the question and answer lookback tokens. This indicates that the payload about visibility information is already in the lookback tokens after layer 31.
- Based on those two interventions, you’d expect that between layers 23 and 30, the pointer has been sent off to the lookback token, so intervening on the address only causes a mismatch, but the pointer hasn’t been dereferenced yet, so intervening on the lookback token just causes a mismatched pointer
- so if we intervene on both the visibility tokens and the look-back tokens, we should replace both the pointer and the address, so they should be aligned again, and we should get proper pointer dereferencing (Intervention 3).
their original motivation causal intervention (out of chronological order) 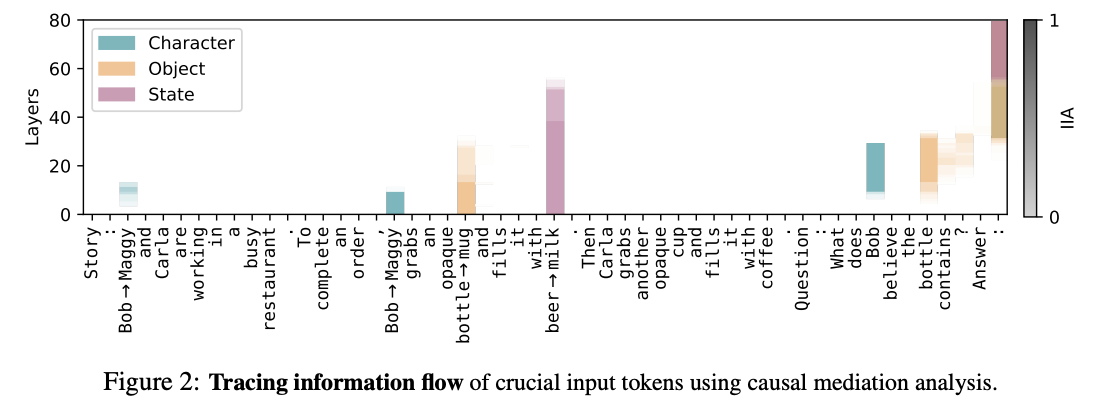
- it took me so long to figure out what’s happening in this figure

- They have three counterfactual prompts. Essentially, they should not be able to answer the question correctly with the original prompt but with a counterfactual prompt which either has the correct character, object, or state substituted in, they should be able to. What they do is:
- 1. Do a forward pass through the counterfactual prompt.
- 2. During the forward pass through the original prompt: for one token of the original prompt, for one layer, patch over the residual activation from the counterfactual prompt for that token at that layer.
- 3. See if the output changes
- The color Is which counterfactual prompt they used (This is a combination of Figures 10, 11, and 12). The shading is how effective patching at that given layer was in changing the output.
- So for instance, blank on the “coffee” column means that patching over the residuals in the coffee’s residual stream did nothing.
Takeaways from the figure:
- If you look at the pink state values, it looks like intervening before about layer 50 for the state, you would have to intervene in the original beer token, while intervening for later layers, you should intervene at the last token. This implies that the information about state stays at its original token until it gets transferred over directly to the last token.
- For the last token’s column, earlier layers are more about the object and the character (orange and teal), but we eventually forget about them and just focus on the state (purple).