End-to-End Test-Time Training for Long Context
TTT-E2E
Goal: O(1) inference latency per token (Standard attention is O(T), Where T is the length of the sequence), while not dropping performance compared to standard attention like Mamba does 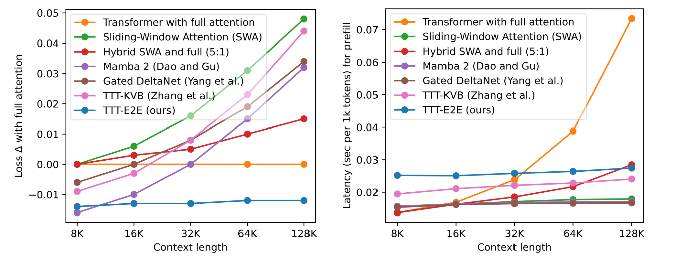 Figure 1: They achieve this goal.
Figure 1: They achieve this goal.
Methods
Main idea: Test time training can be used to store information about previous context in the weights. 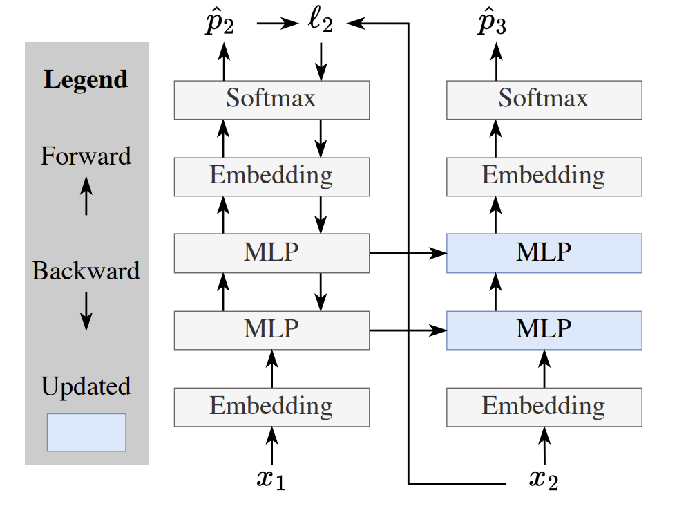
- Toy example with no attention layers, only MLPs. So, without doing TTT, it’s a bigram model since it can only use the current token to help predict the next token.
- At test time, you’re given a sequence of length T, And you’re trying to predict token T+1. You train on the tokens 1…T one at a time using standard cross entropy loss, and update the weights as you progress through the sequence.
-
- That’s what this figure is showing. You do actually get information from the first token in your prediction for the second token because you are using the updated MLP weights, which were updated with the first token’s loss.
- And then your final output is just your prediction for the T+1’th token.
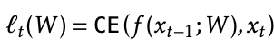
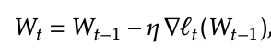
End-to-end training
- Previously, during training time for models that have been used for TTT, people still use the normal loss function of just next token prediction.
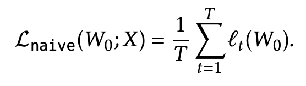
- But this causes a disconnect between the training loss and how we use our model during test time.
- Instead, during training time, we should take entire sequences, and then use the TTT method to get predictions for each token in the sequence, and use next token prediction loss on these predictions instead.
-
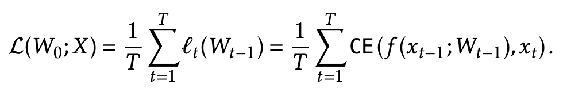
-
Funny note: the loss has gradients of gradients, since gradient update steps are used in the prediction
-
mini batching and sliding window attention
- Updating weights per token sequentially is really slow during inference time.
- We can use the same weights for a batch size b of tokens in a row, and then update for those tokens all at once.
- Problem: Now, none of the tokens within the batch have the context of the tokens before them.
- Solution: Add back sliding window attention layers, with context length 8b
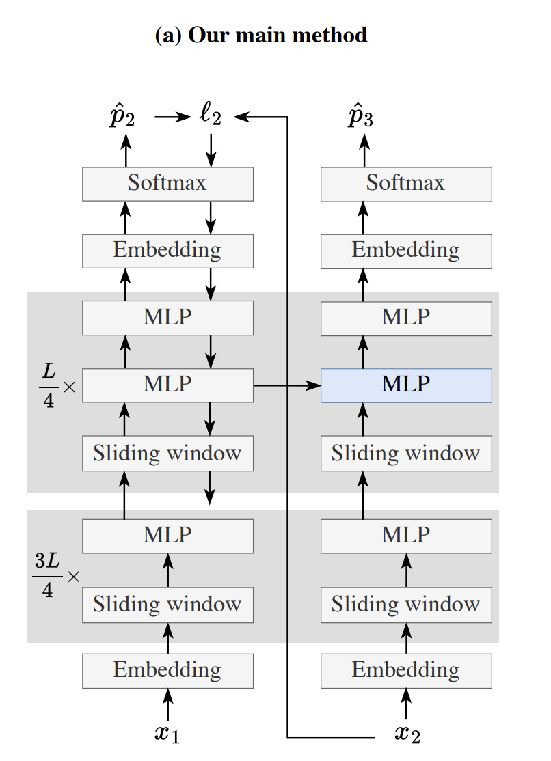
- Figure 3. Implementation details.
- Blue is the MLP layer that gets updated during test time. Only happens in a quarter of the blocks, and they also duplicate an MLP layer that they keep static to prevent catastrophic forgetting.
- The Fast weights interpretation of this: (during training time) blue is the fast weights that get updated more often, and gray is the slow weights that only get updated in the outer loop
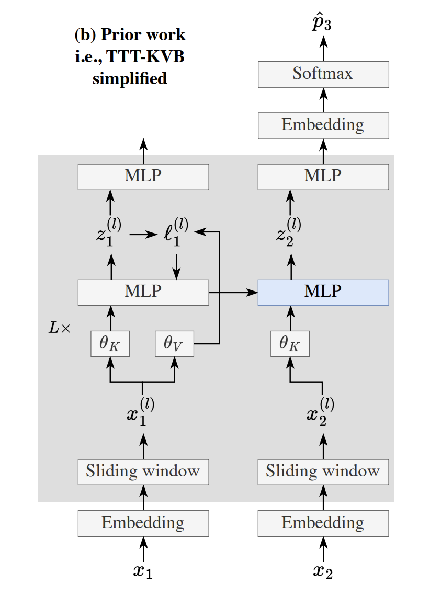
- The other side of this figure is for their Section 2.4 alternate derivation of their architecture from the TTT-KVB works, like nested learning and delta net
I like this sentence a lot. E2E means that the objective function is the same as the objective function that you’re actually going to be using it for
“Our primary derivation starts from TTT via next-token prediction, which is E2E at test time, and focused on making it E2E at training time via meta-learning in Subsection 2.2. Our alternative derivation, on the other hand, starts from TTT-KVB, which is E2E at training time, and focused on making it E2E at test time via next-token prediction.”
- Making things E2E seems like their novelty.
Results and Experimental Setup
DCLM (filtered Common Crawl) As is standard, they pre-train on 8k sequence length stuff, and then do a fine-tune on 128k sequence length from the Books data set.
Hyperparameter ablations don’t really seem that special. Scaling experiments (figure 5) 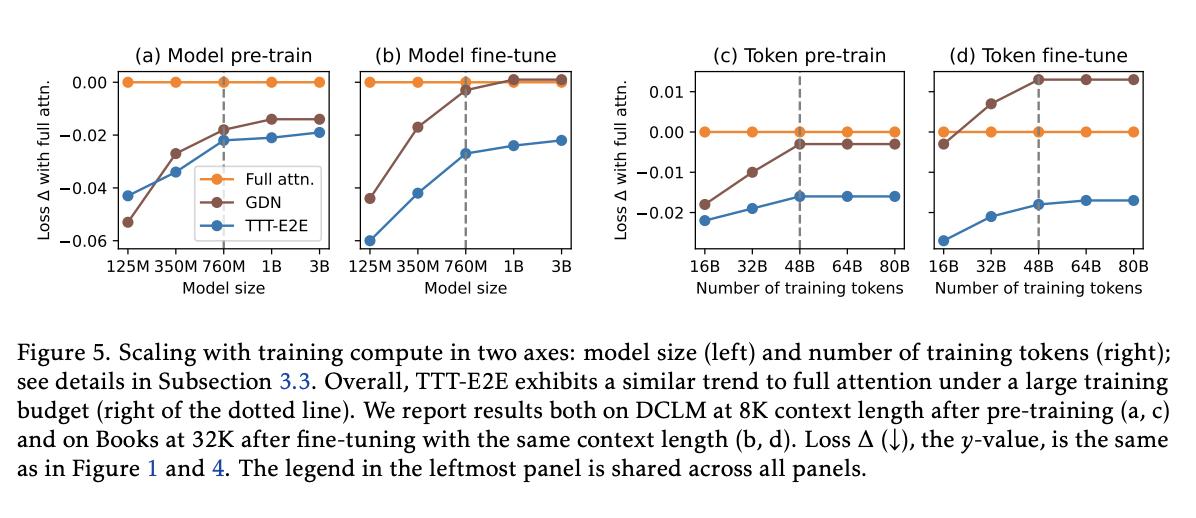
- Scale both model size and number of training tokens, like in the normal scaling laws
- Instead of just pre-training loss, they also use fine-tuning loss on Books, since on their 8K sequence length pre-training data set, sliding window attention is the same as full attention.
- Find that their architecture is compared advantageously to full attention mostly exists at a smaller scale. “Transformers are widely known to under-perform with insufficient training compute compared to RNNs”
Scaling with context length
Surprise (Figure 6 / section 3.4.1): TTT E2E actually gets most of its performance improvement over full attention in the first 1K tokens, before it has done any update step and while sliding window attention is still full attention. Why? They conjecture this is because TTT E2E can be more specialized for the present instead of trying to be somewhat good at any possible scenario.
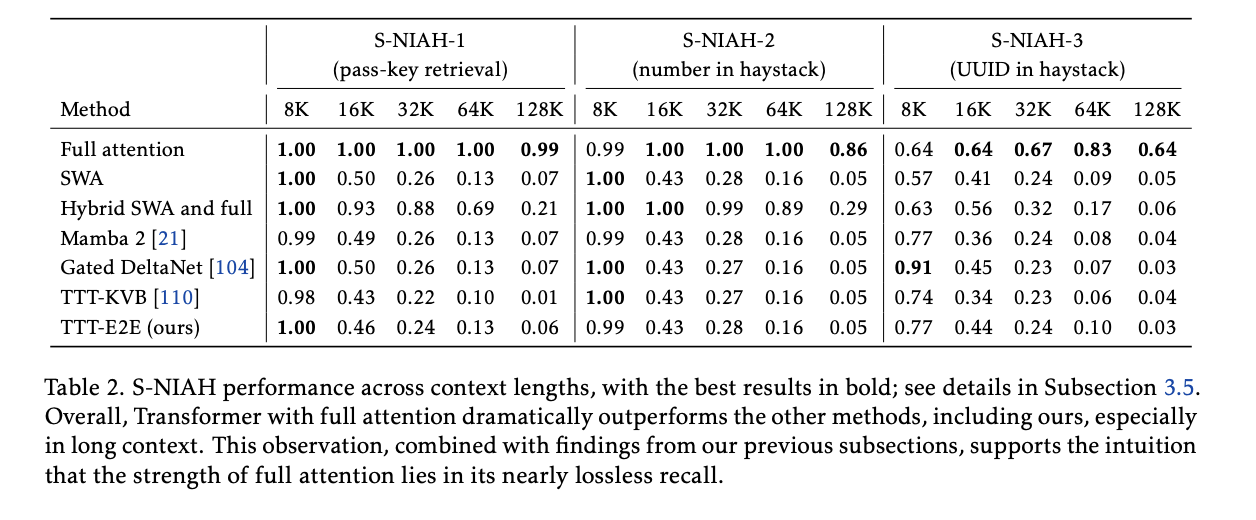
- They can’t do Needle in a haystack like full attention can
- Further evidence that their method is doing good by compressing information
Decoding long sequences
- Was actually discussing this with Kevin. They continue doing TTT on the decoded generated tokens. You might be concerned that there’s a distribution shift from TTT on pre-filled tokens to TTT on generated tokens. In a sense though, TTT on generated tokens is sort of like increasing the temperature: you’re pushing more towards generations that were selected.
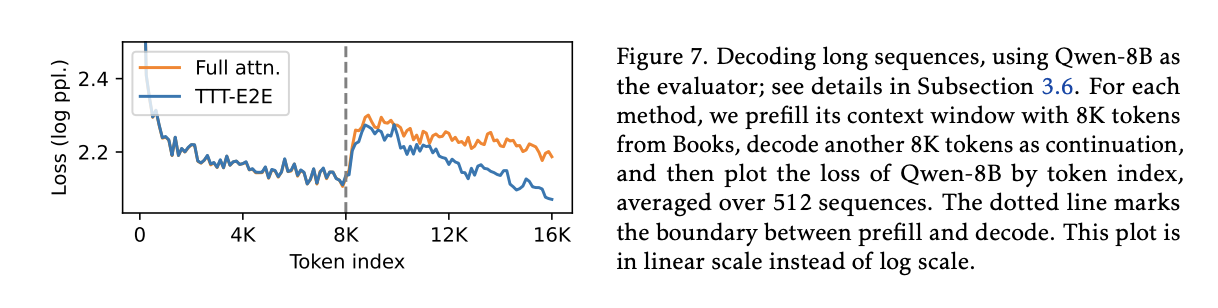
- Nice to see that they do better than full attention. Why the discrete jump from pre-filled tokens to model-generated tokens? It’s a little surprising to see the model generate token style, I suppose, until that makes up more of the context
Training latency is COOKED 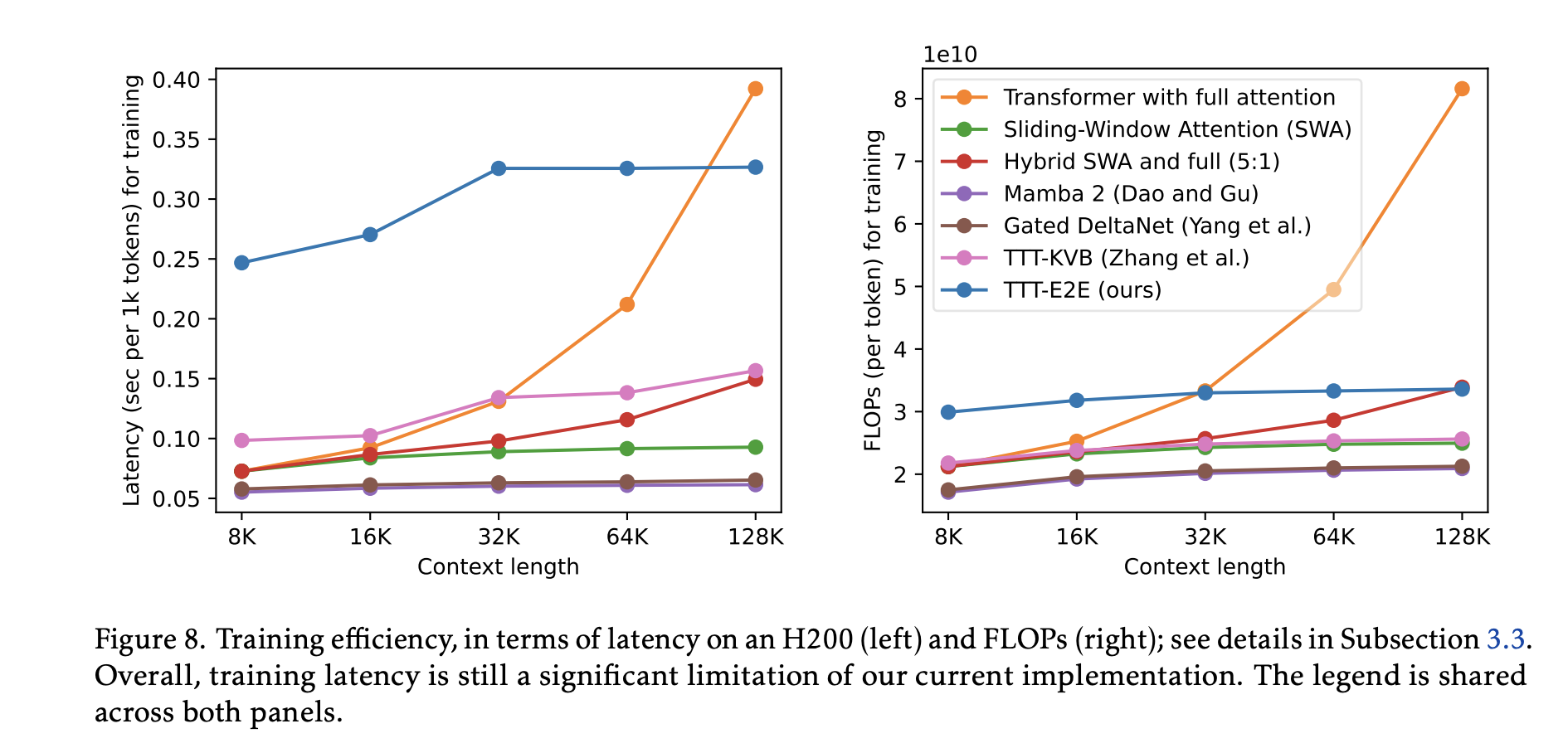 Look at that left figure, wow. This is from lack of full parallelization.
Look at that left figure, wow. This is from lack of full parallelization.
- Mamba 2 is fully parallelizable.