Causal Abstractions of Neural Networks
Causal abstractions
Basically, what the lookback paper did Associate a higher-level causal abstraction with lower-level parts of the network and run interventions to prove that they actually correspond.
- Allows finding sparser causal models than the underlying Neural Network.
Why not other approaches: Probes are not causal (so that even if you fully understand what’s being represented by a neuron, there is no guarantee that Neuron is actually being used for the output computation, unlike in causal abstraction), Attribution methods don’t really tell you at a high level what the neuron is doing.
Toy model
problem: network to do a+b+c (a, b, c are single digits) 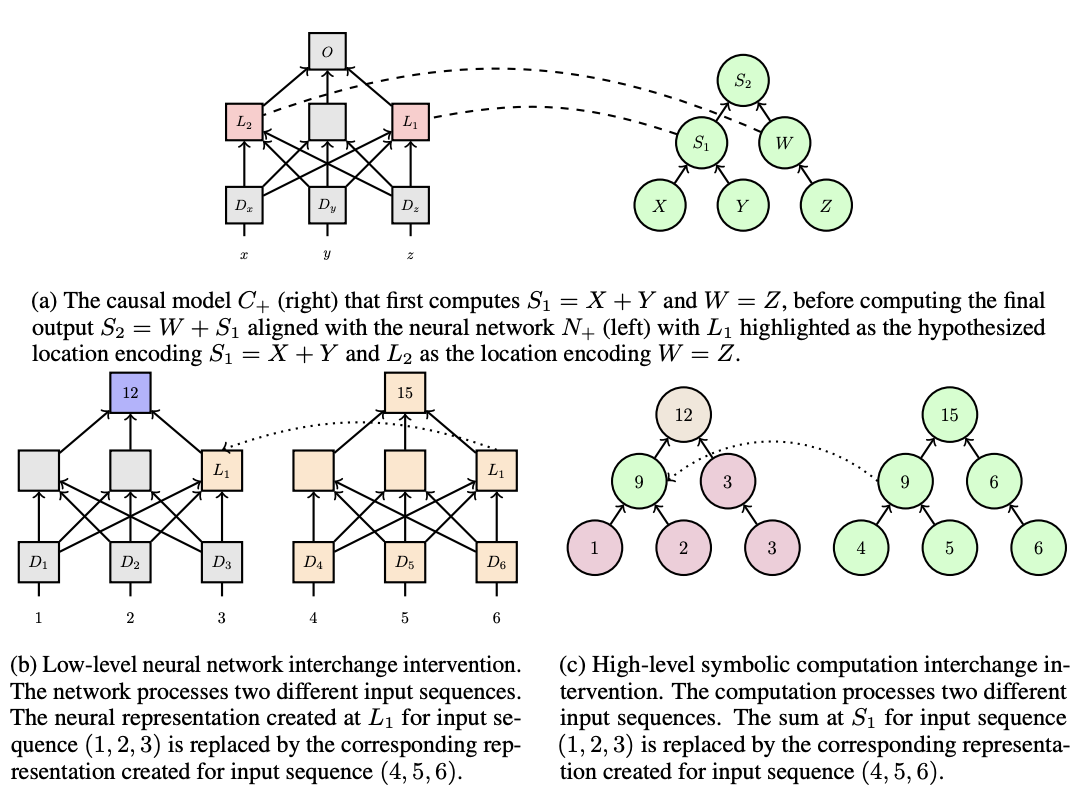
- Top: On the right is your hypothesized causal abstraction for how the addition is being represented. You think that first it’s adding x and y, and then adding on z. On the left, it’s mapping the intermediate computation to specific neurons in the neural network.
- Bottom: Now we do an intervention where for the neural network, we replace the activations of the neuron representing x + y for one input with the activations from another input. The causal abstraction tells us what answer should we expect to get
- If for every choice of “baseline” input and “source” input, we get a matching result between the neural network and the causal abstraction. We can conclude that x + y is actually being causally represented there
- Note that it’s totally possible that L1 could even be correlated with z, so this method has the strength that it identifies the causally impactful stored information.
MQNLI case study
Given two sentences, have to determine if the second one is a contradiction, entailment, or neutral to the first
- Only BERT does this well
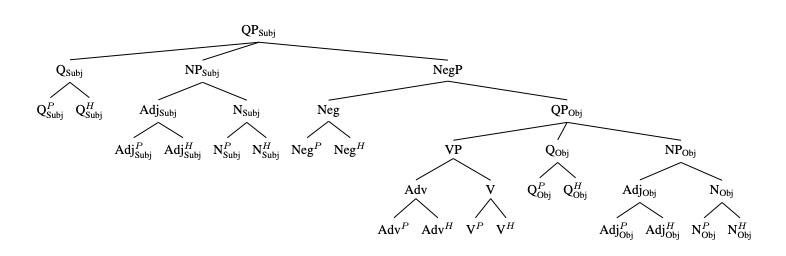
- There exists a ground truth causal model for this task
- They’ll try to use submodels of this as causal abstractions
“successful” means that the result of the intervention matches the causal model. “impactful” means that without doing an intervention, the two inputs would have different results
They didn’t do an exhaustive search through the network of all the places they could map intermediate nodes in the causal model to, mainly just the residual streams on each token after a transformer block.
Then, for each of these mappings, they ran a causal intervention on each pair of inputs. They don’t expect a 100% success rate, so they make a graph between all pairs of inputs that work and find the size of the largest clique that has one impactful edge at least.
- Table 1a is their main results of this
- Table 1b: Some auxiliary evidence that they have the right causal model: You do not get stronger evidence (i.e., a larger clique) with surrounding causal models that have one node edited.
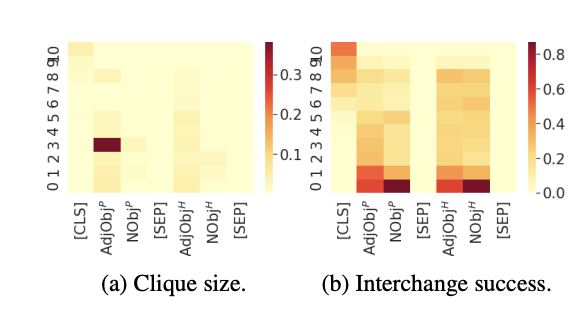
- Figure 4: It seems like if you just use interchange success rate, you get much noisier data than using clique size. I feel like the lookbacks paper used interchange success rate though
probes found too many “false positives” where the information was encoded but didn’t actually affect the output.
integrated gradients did causally help determine how changing a single input token affects the output, but say nothing about the intermediate computations and how they are composed.