Position-aware Automatic Circuit Discovery
position aware circuits
Automatically discover circuits Containing token position-specific nodes for prompts of variable length.
Background: three types of circuit discovery:
- activation patching (arithmetic heuristics style, I think this doesn’t find the edges in the circuit)
- path patching (nikhil fine tune style, builds an entire path during the discovery process iteratively)
- edge patching (this paper; edge ablation is the same idea from Nikhil’s path hatching, where you ablate just the contribution from the output of a previous head to either the query, key, or value of the current head (possibly in a different token position).
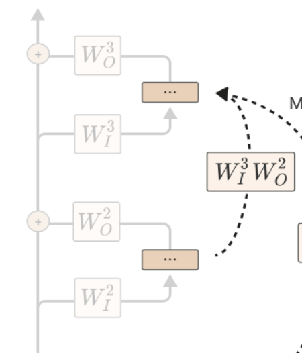
- Relevant diagram from Anthropic Mathematical Transformer Circuits
- Except in this paper, it seems that the output projection and the input projection are included as part of the node, so the output of node U feeds directly into the input of node V.
The problem: Existing automated approaches aren’t able to find granular edges that only hold for certain token positions, because of varying input lengths. Manual circuit discovery (e.g. IOI) could do this because they could find semantically similar tokens.
- Existing automated circuit discovery does an aggregation over all token positions.
- Figure 2: This leads to missing important edges due to cancellation and due to summing many less important edges

Section 3.1 Horizontal and Vertical edges
In their circuits, they have vertical edges relating nodes in the same token position but different layers, and horizontal edges relating nodes in the same layer but different token positions
- Vertical edges are calculated using the known IE method approximation below, between a node u and a node v (nodes can be MLP layers, attention heads, etc)
The Indirect Effect (IE) of an edge is how much it affects the target metric when the edge is patched (i.e. directly by activation patching) 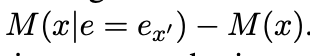
- This is computationally expensive to do for every edge.
- People use a first-order approximation instead to be faster: EAP (Edge Attribution Patching)
-
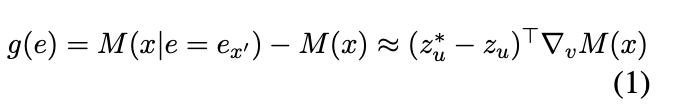
- people possibly now use attribution patching with integrated gradients instead of just the first order condition? See modality specific circuits
horizontal edges:
Another inherent limitation of the automated methods is that their edges can only be within the same token position, I.e., not cross positions (Look at the anthropic mathematical transformer circuits image again)
- Again, the manual circuit discovery didn’t have this problem; for instance, the Nikhil fine-tuning paper had edges between heads in different layers and different token positions.
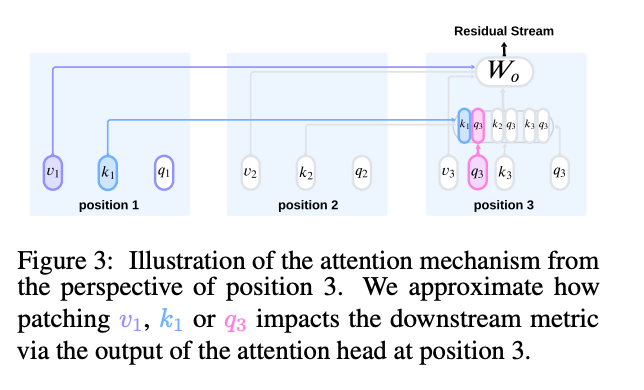
Can introduce cross-token (horizontal) edges between nodes in the same layer (token position t and token position t’), as a result of attention heads operating across tokens in a layer.
Figure 3: To approximate the impact of patching these edges, we calculate the modified output of the head (based on the three different methods — query, key, and value — that the two token positions could be related), and then use the linear approximation to get the output on the desired metric.

Section 4 Schemas
The subject of a sentence might be two tokens “Black Plague” instead of “war”. Schemas treat them as just the “Subject” in the effective circuit
Figure 4: They have an LLM automatically generate schemas for the dataset 
Figure 5: Translating between circuits on the schema and circuits on the original prompt is simply just expanding the schema into its constituent tokens and either summing up / including all of the edges 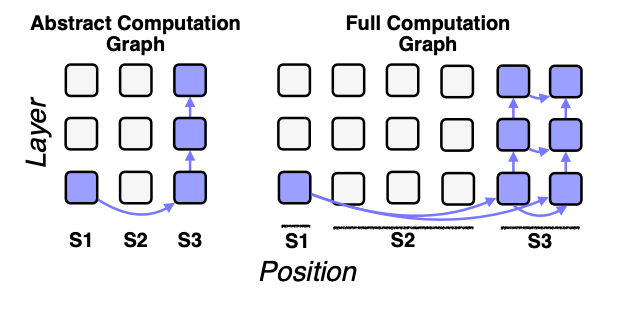
- e.g. to find the circuit on the schema, they first find the edge strengths on the full graph, and then the edges corresponding to a single edge in the schema graph, and once they have the effective edge strengths for the schema graph, then they go back and do the greedy circuit selection
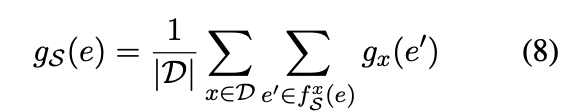
- For the faithfulness of the full circuit, they expand the schema circuit as in Figure 5 and apply everything not in the expanded version.
Schemas are generated by LLMs and applied by LLMs
- They compute a saliency score for each token (inputXgradient Shrikumar et al 2017) and give a discretized version of that to the LLM so that it knows which tokens are important and must belong in their own spans.
Schema evaluation
- valid: Span labels are in the right order, and every token is assigned to a span. Can manually check for this and filter out invalid schema applications
- Correct: Matches a human application of the schema
Section 5 Experiments
Datasets
- IOI: “When Mary and John went to the store, John gave a drink to”
- Greater-Than (hanna et al 2024)
- Winobias “The doctor offered apples to the nurse because she had too many of them” (gender bias)
Measure faithfulness and average circuit size across examples
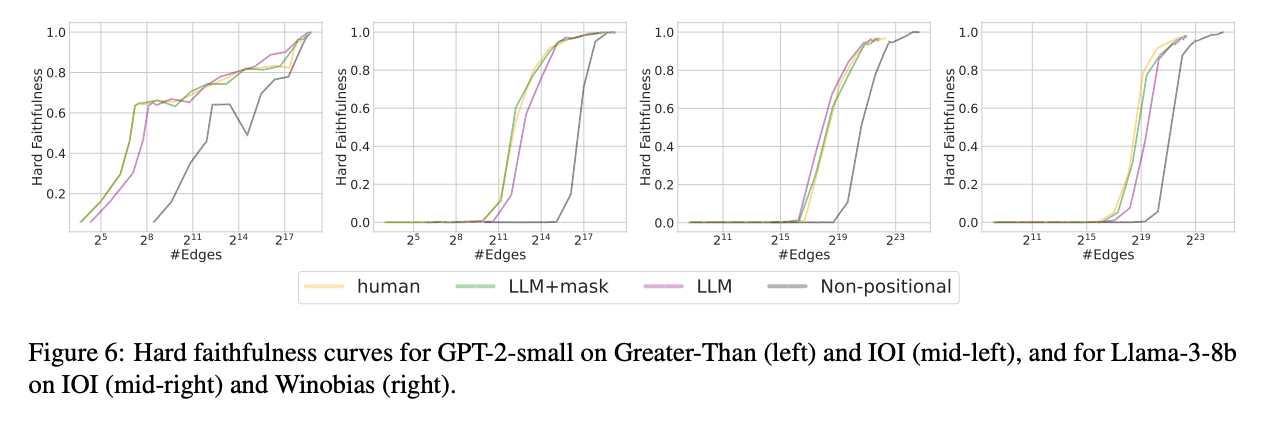 Figure 6: results
Figure 6: results
- Much higher faithfulness with smaller circuit size than the non-positional versions.
- approaches manual human-designed circuits
- Adding the saliency mask does boost performance.