Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking
circuits in fine-tunes
Trying to understand, mechanistically interpretability wise, why models fine tuned on structured tasks (like arithmetic) do better on entity tracking
Data / task: entity tracking “The apple is in box F, the computer is in Box Q, the document is in Box X… Box F contains the”, it should predict the next token as “apple”
- change the original kim & schuster dataset to “The apple is in box F” in the first sentence instead of “Box F contains the apple” because otherwise you can’t be sure that it’s not just trying to match the longest matching string as the query
models used for circuit analysis were base Llama-7B and 3 fine tunes (Vicuna-7B, Float-7B, Goat-7B)
Section 4. Circuit discovery/evaluation through path patching
What was the circuit that they discovered in Llama-7B: (Figure 1): 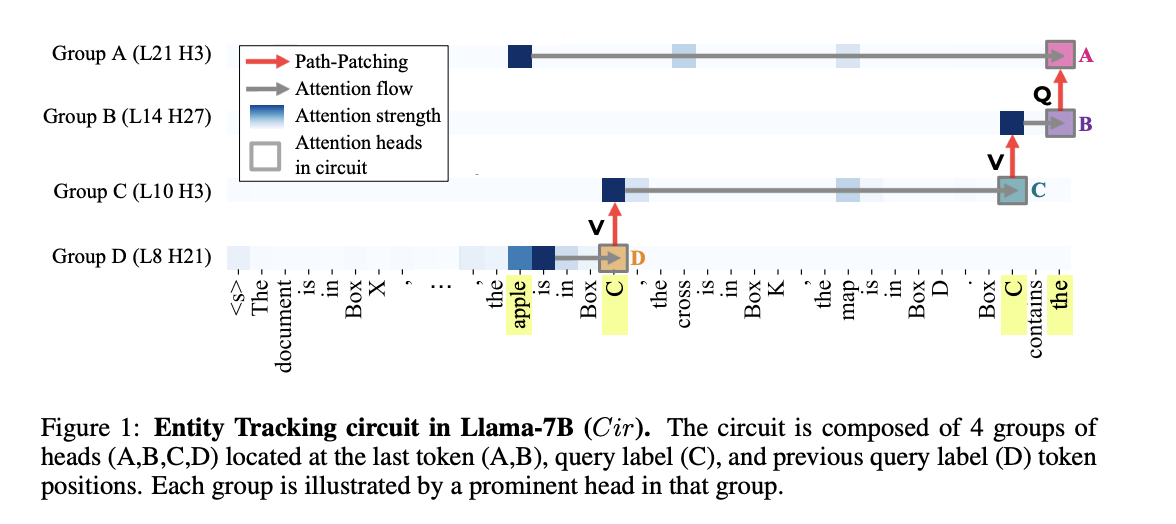
- in the first token occurrence of the box label “C”, it pays attention to “apple” (the answer, dark blue box), and gets that into its residual stream.
- The other occurrence of “C” in the query pays attention to this earlier “C”, and the attention values come from this earlier “C” token, hence “V-composition,” which gets this information into the residual stream of the query “C”
- then the output of those heads are copied over into the residual stream of the last token, again via V-composition.
- Then, in the same token, used to construct the query for that last token (Q-composition). Helps the last head find the answer token “apple,” from which it reads the answer directly.
Discovery + Evaluation process for circuits
Discovery (Path Patching, Wang et al 2022, Goldowsky-Dill et al 2023): for each of the 300 box tracking questions, construct a coresponding noise task with random query, box labels, and objects, and see for which “paths between nodes” patching over from the noisy run to the original run has the largest detrimental “effect”. - the path between heads refers to the following:
The residual feeding into a head has contributions from each of the previous layer’s attention heads. 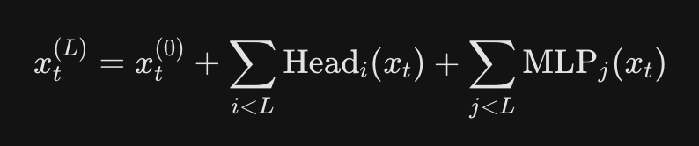 And then when you calculate the query for that head, there is a term corresponding to the contribution from the previous node. In path patching, you merely patch that contribution. This is also how you tell if it’s Q composition or K composition or V composition.
And then when you calculate the query for that head, there is a term corresponding to the contribution from the previous node. In path patching, you merely patch that contribution. This is also how you tell if it’s Q composition or K composition or V composition. 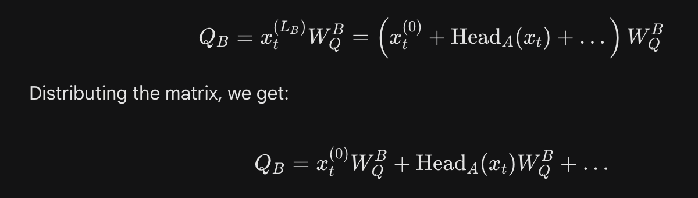
- also Q composition has to come from a node in the same token (since you’re affecting the current node’s query), while K and V composition come from other nodes (since you’re affecting their keys/values)
- (unsure) “effect” at first means probability of selecting the correct answer token, in order to find the set of heads in the last token. Then iteratively find groups of heads that have high direct effects on the previous group
Evaluation: minimality, faithfulness, and completeness
- minimality: variant of Wang et al 2022, for each head v, find a subset K of heads (they do this greedily, Wang et al 2022 just choose the full head category that v is part of), and then ablate K and v vs ablate just K, and see if v actually has an effect on restoring performance. If it doesn’t, prune it from the circuit
- faithfulness: how good is Accuracy(circuit) / Accuracy(full model) ? Where Accuracy(circuit) means for all non circuit heads, replace them by their mean activation across the evaluation data. Closer to 100% is good. They got 100%.
- completeness: is the circuit actually complete, like is every head involved in the task part of the circuit? To do this, we can see how Accuracy(circuit \ K) compares to Accuracy(full model \ K) for each subset of heads K in the circuit. If this is high, then there may be some heads contributing to accuracy in the full model that we’re not capturing in the circuit. The paper actually finds that this is the case, and their circuit might not be complete.
- they independently also verify the circuit using some kind of attention knockout technique from Geva et al (2023)
When they checked the same circuit on the fine tunes, they found high faithfulness of 0.97, 0.89, and 0.88. For the 0.89 and 0.88, they re-did the circuit discovery procedure and found much a much larger superset circuit of the original circuit.
Section 5. Understanding what the different heads in the circuit do (in original and fine-tuned)
They use DCM (Davies et al 2023) which looks like just a worse version of the causal abstraction method.
Hypothesized three different possible roles for the heads: encoding object information (like the final value), encoding label information, encoding position in the sentence.
Do the standard causal abstraction thing of construct original prompt and the counterexample (many different copies of this to reduce noise, measure the overall success rate)
 Figure 2: the setups that they used to measure each role
Figure 2: the setups that they used to measure each role
- Object: counterfactual prompt has a new box with a new object in it. If that object becomes the target answer, then must have brought over information about that new object’s value, since it never appeared in the original prompt. Had to change the box label for this, or else you just duplicate Label’s prompt (though tbf, if in retrospect you do get “cup”, that still does tell you that you surely got an object desiderata. It’s just that your prompt can’t be successful for both object and label at the same time)
- Label: change the box that you’re querying for in the counterfactual. Has to be a box that doesn’t exist in the counterfactual’s context, since otherwise it’s hard to tell the difference from the Position role.
- Position: Ask for a different box within the existing counterfactual prompt. If you get the object from the same position in the original, then it’s likely encoding position, since you didn’t bring over the query label (since Box C doesn’t exist in the original), and you also didn’t bring over the object from the counterfactual since it didn’t end up as the target answer).
They find that for the circuit described above, the higher level functioning is:
- the first set of heads (which they couldn’t match to a role) collects information from the surrounding segment, from which the next set of heads detects the position of the correct object. This correct position is transmitted by the next set of heads to the last set of heads, who use it to locate the correct object location and fetch its value.
Figure 3: the same heads have the same roles in the fine-tuned versions. Except the value fetcher heads actually do a better job (i.e. they succeed on the counterfactual patching more often) 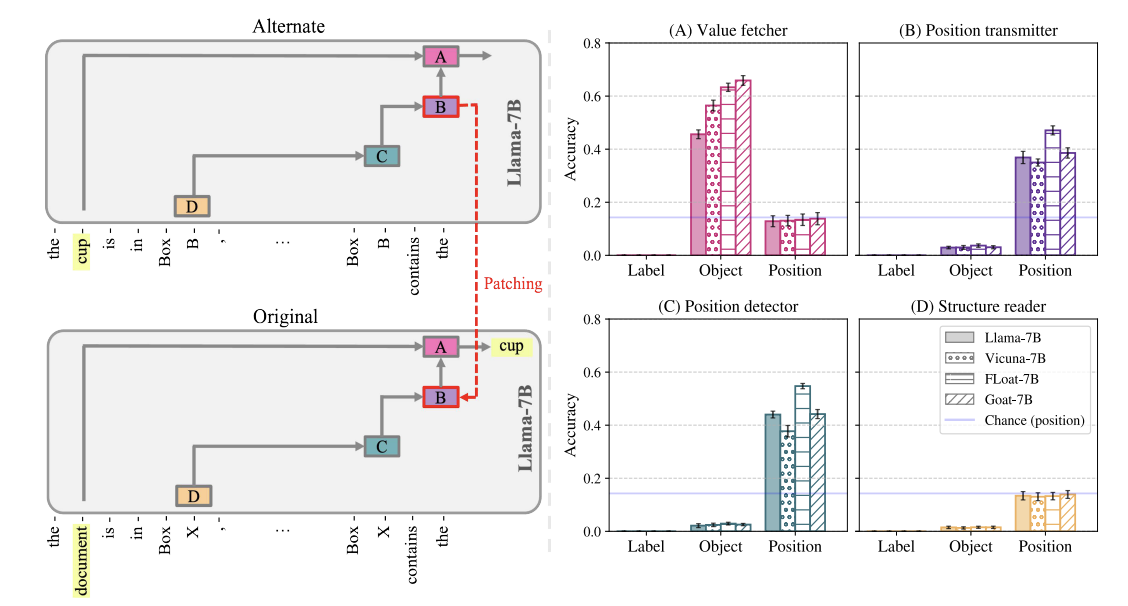
Figure 4: which step in this mechanism is actually improved by the fine tuning? Instead of using same model, different inputs, they used different model, same input, and patched over heads. They find that you get back the fine tuned performance from patching over the position information heads (implying that they’re storing augmented positional information) or the value fetcher heads 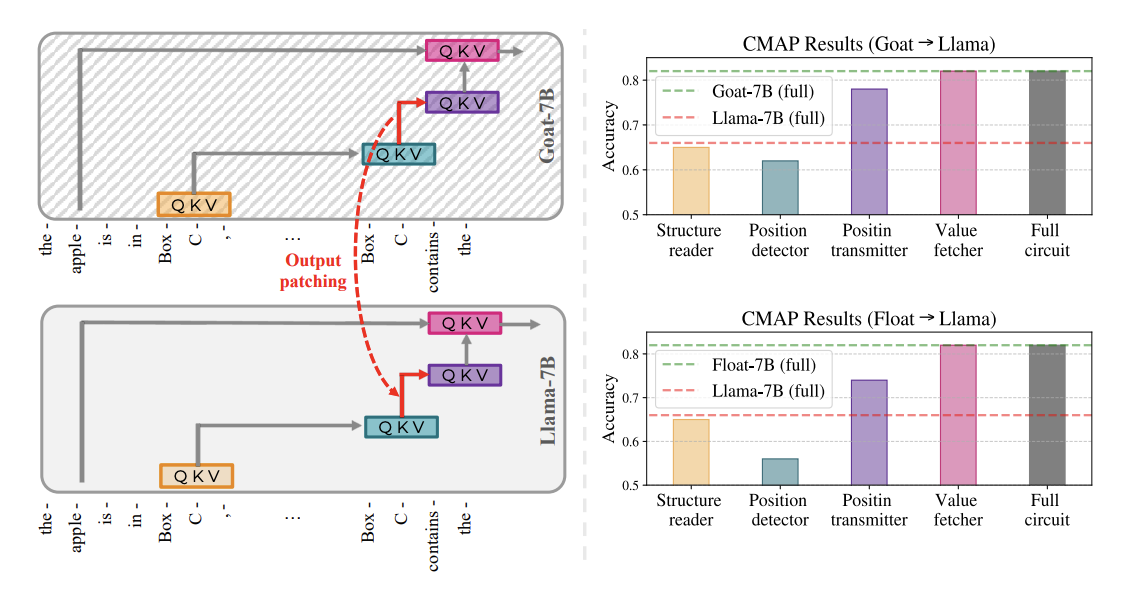
- it’s interesting that they can do this at all, i.e. that the activations from the circuit in the fine-tuned version just fits with the original.
- isn’t it obvious that patching over the value fetcher heads will result in improved performance? Since these value fetcher heads contain information from all the parts of the circuit up to that point.