Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights
neural thickets
For larger scale models, if you literally just add noise to the weights after pre-training, You have a high chance of landing on a specialist set of weights that are good at one particular downstream task (Figure 2 below)
- Sort of implies that the post-training algorithm use is not that important.
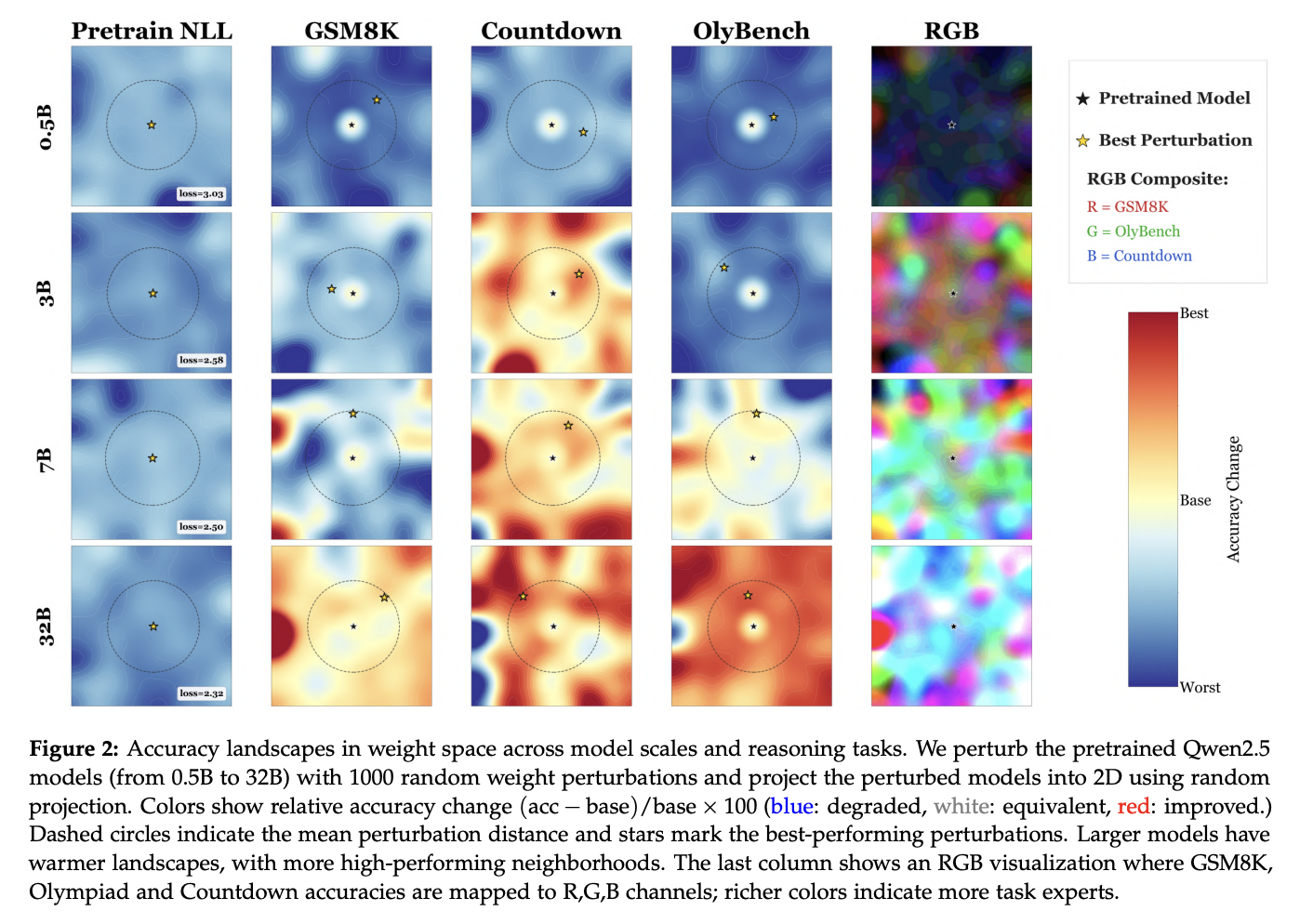
- Figure 2: very specific to larger scale
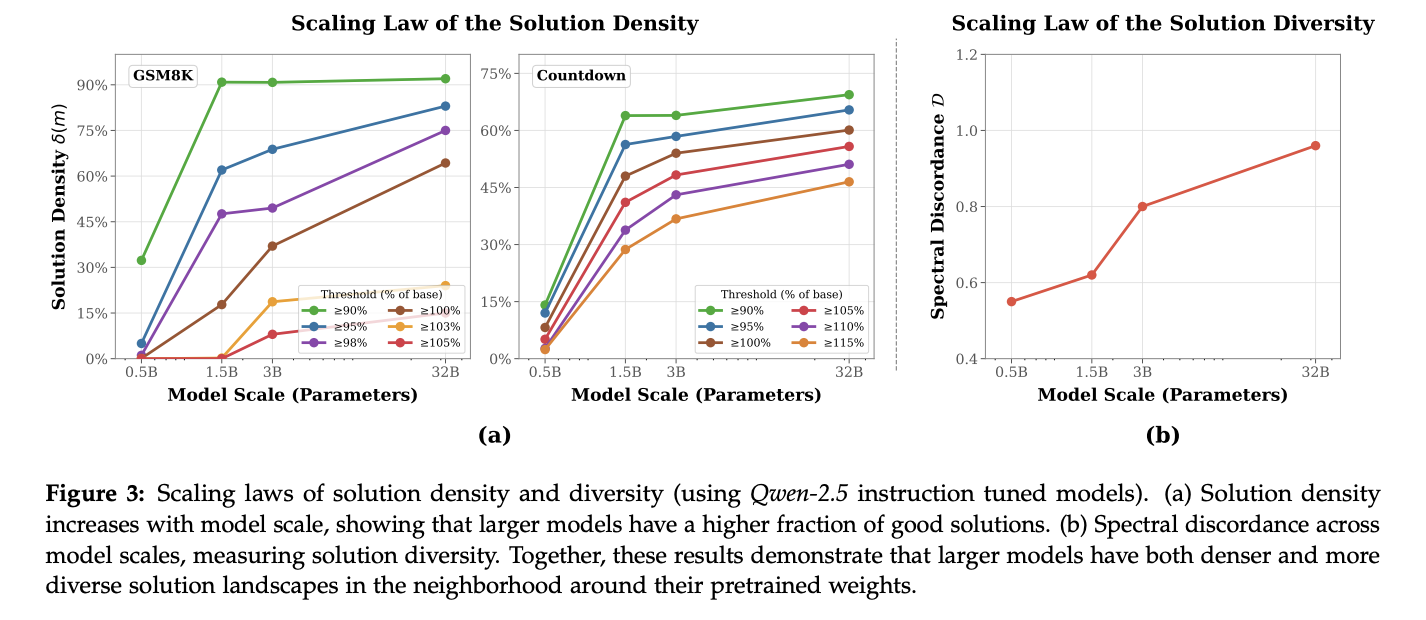
- Figure 3: Further evidence that for smaller scale models, you get much less diverse and interesting/good models by perturbing your weights.
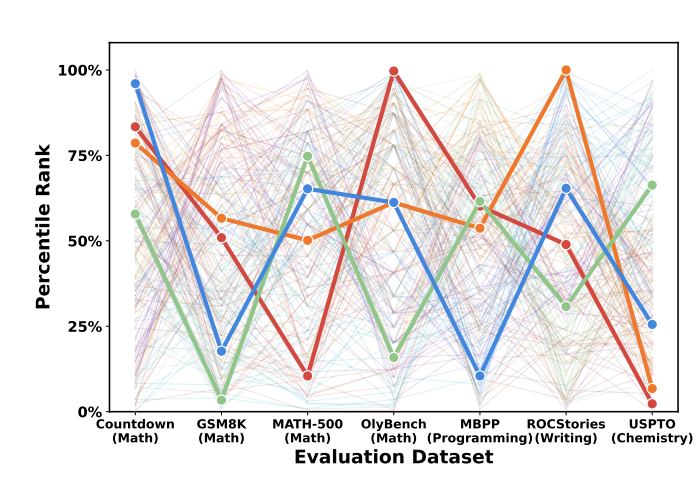
- Figure 4: These models are actually specialists; they’re not generalists
They boost performance by literally just sampling the top fifty, such randomly chosen models, and then taking a majority vote/ensembling from them (RandOpt)
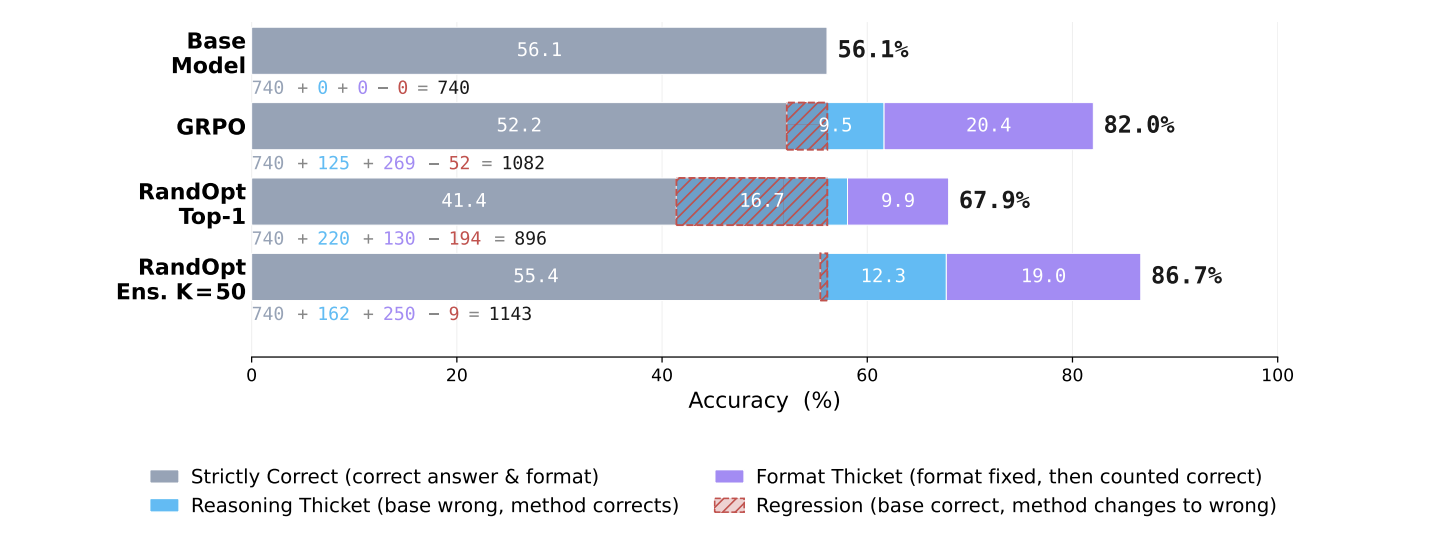
- Figure 9: The weights in the thickets could improve both reasoning performance and just getting the answer output right.
Update (5/12/26) from Yulu Gan’s talk on this:
- You can do differentially-private post-training using randopt, without losing much performance
- This sort of weight space perturbation works on diffusion models too.
- The thicket is denser on larger models not necessarily because they’re larger, but because their pre-training representations are better
- There are several more interesting ideas you can do besides just basic randopt, and they generally work: you could do multi-step randopt, where after you perturb once and get the best perturbation, you repeat it up to 5 times. You can also add noise of different scale for weights at different layers.