Recursive Language Models
RLMs
Motivation: Context rot sucks, and compaction does not solve the problem.
The main idea is to use a REPL environment to keep state. Make the prompt a variable in that state, and make the output a variable in that state (so that your input and output are not limited by context length). Have the base LLM output code that runs in the REPL, including code that can call the LLM. This way, it can break down the prompt, and make as many subcalls as it would like.
- The only thing that gets put into the context of the base LLM is just a little bit of metadata about the state, like the length so far or something.
- It also needs to be able to look at parts of the prompt, and context about what it’s trying to do, in order to understand how to slice up the prompt.
 Algorithm 2 shows how Algorithm 1 improves on prior approaches
Algorithm 2 shows how Algorithm 1 improves on prior approaches
- Putting the entire prompt into the context (instead of storing it as a variable) is bad because it limits you to your context length for the length of the prompt (Flaw 1)
- Returning the output of the LLM call directly (instead of storing it as a variable) limits the length of your output.
-
Limiting your LLM to only generating the action (tool call, sub call, etc) and input to the action instead of letting it generate entire code that includes calling the subcalls is bad because what if you want to do O( P ) subcalls that process different parts of the prompt
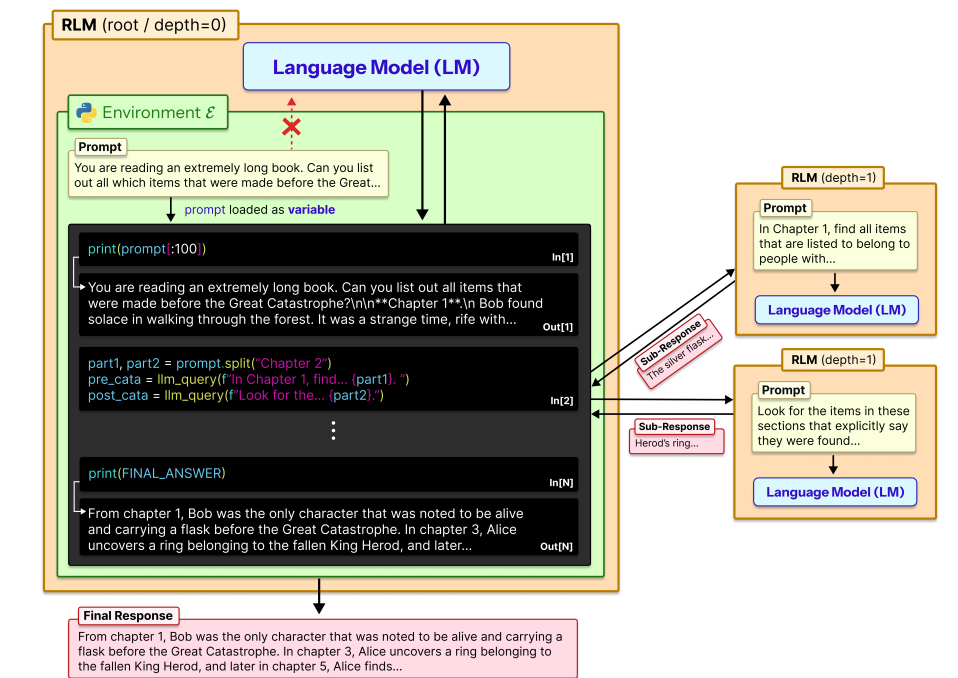 More illustration of the RLM process
More illustration of the RLM process
- I think the base LLM itself generates the In[X] code
- In[2] includes recursive calls to the RLM each with their own starting prompt.
- the final answer is stored in the variable FINAL_ANSWER
Finetuning: they used RLM(Qwen3-Coder-480B-A35B) on unrelated long context tasks in LongBenchPro, collected a bunch of root level trajectories, filtered them, and then used SFT on Qwen3-8B. The idea is that through the fine-tune, they want to encourage the base model to do a better job of recursively sub-calling the base LLM.
- Also, they found that you need a good coding model to use RLM in general.
Experiments
Benchmarks: used CodeQA, BrowseComp+, OOLONG, and OOLONG-Pairs. More importantly, for the last two, they are interested in tasks where the complexity of the task itself scales with prompt length
- OOLONG requires a semantic transformation of every chunk in the input.
- OOLONG-Pairs requires every pair of chunks in the input.
Results
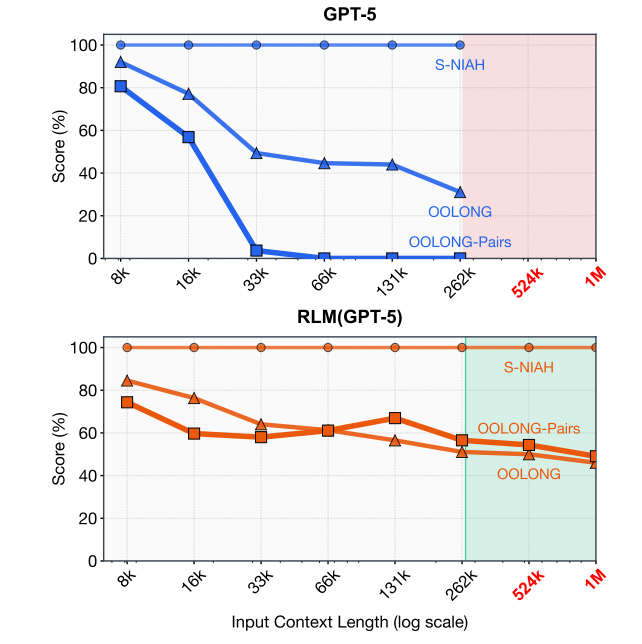
completely blows prior approaches out of the water lol, with comparable inference cost
RLM behavior
- interesting note: different models interacted with the RLM differently. They had to include a line in the prompt with Qwen to tell it not to make too many subcalls.
- The reason that RLM can still be cheaper than the base model inference is that the base LLM carefully selects what part of the prompt to actually read in, using regex and its prior heuristics
- Very similar to Iris Xu’s BOAD, using subagents can be more efficient because you don’t have to give all of the output context from the subagents to the main agent, and you don’t have to give all the contacts in the main agent to the subagents.
- RLM actually used output variables as intended, writing incrementally to them.
Notes from Alex’s talk:
- Interesting perspective on scaffolds; he thinks LLMs are good enough that designing good scaffolds that the models are co trained with is no longer useless. And apparently the big labs have already done this and saturated internal long context benchmarks
- He compared training LLMs with RLM scaffolding to training for reasoning: instead of the LLM learning to output useful tokens to condition on, it’s learning to output useful subcalls and code
- Training LLMs to be native with RLMs is the most critical future work
- RLMs can be combined with KV cache compaction and other systems optimizations