Measuring AI Ability to Complete Long Software Tasks
METR Long Tasks AI
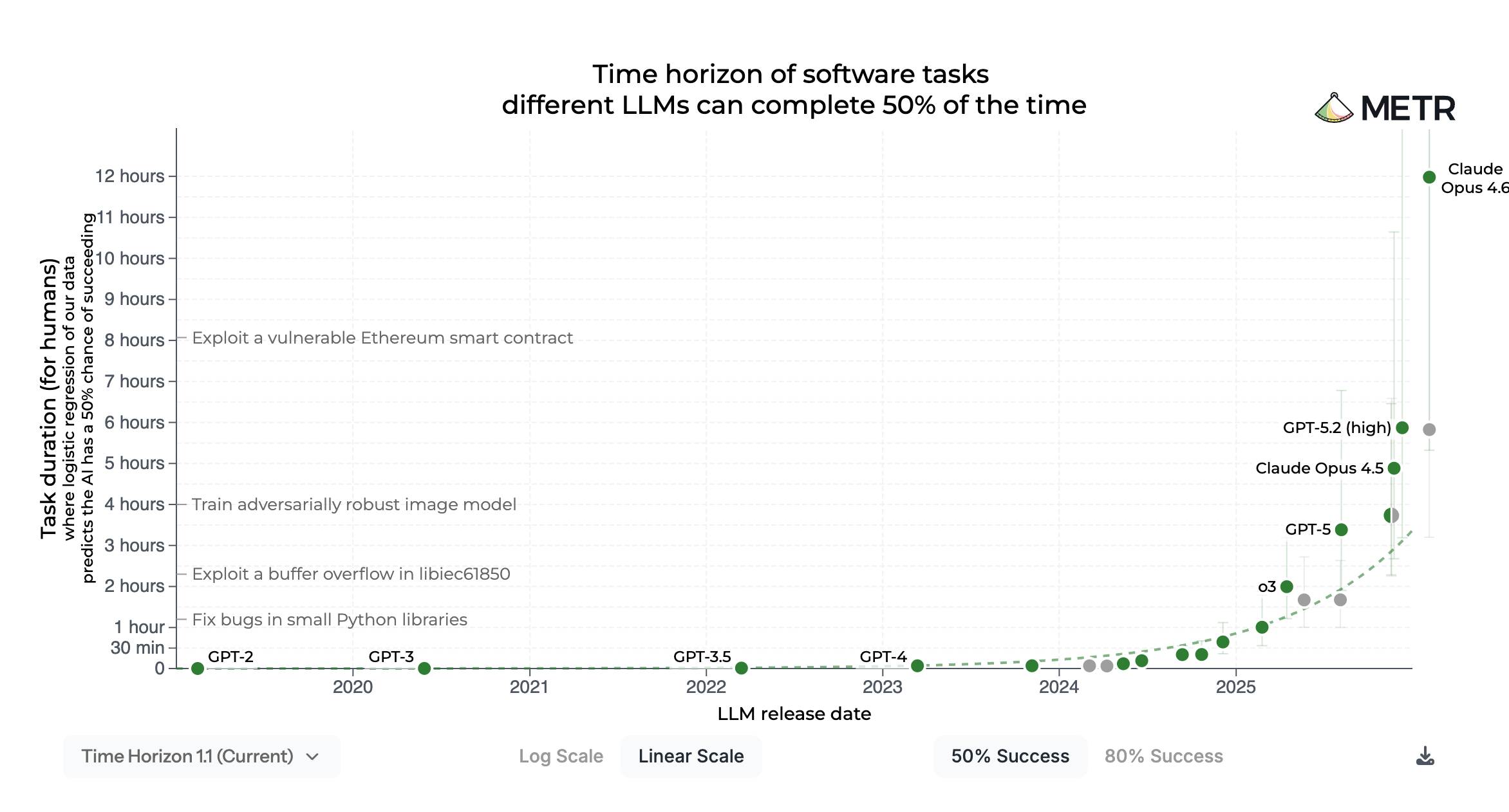 Problem/motivation: because AI has been saturating benchmarks, which we’ve lowkey been artificially creating to test things that AI is bad at compared to humans in the first place, it’s difficult to evaluate the growth of AI over time (i.e. how do you compare GPT2 to GPT 5).
Problem/motivation: because AI has been saturating benchmarks, which we’ve lowkey been artificially creating to test things that AI is bad at compared to humans in the first place, it’s difficult to evaluate the growth of AI over time (i.e. how do you compare GPT2 to GPT 5).
The solution: human time  Created their own new benchmark SWAA to be able to get time data for really old dumb models.
Created their own new benchmark SWAA to be able to get time data for really old dumb models.
Concerned that these results don’t generalize to agent performance on real-life tasks.
- Stratified data sets by Messiness Index, found that similar doubling trends held on messy vs. un-messy data.
- Used swe bench verified.
- Compared to contractor performance on their internal PRs.
- External contractors spent 5-18 times as much time per task as internal maintainers.
Section 2.1 Just literally gives an overview of the commonplace agentic benchmarks
Section 2.2 Forecasting related works (from METR):
- https://arxiv.org/pdf/2401.04757 epoch Forecasting question answer benchmark scores using pre-training compute (really old models)
- https://arxiv.org/pdf/2502.15850 The Apollo research paper that I sent earlier. They use the word backtesting. Also only forecasting aggregate score on benchmarks (though wow, they had a good forecast for Swe Bench Verified). Fit a linear curve of ELO vs. time and a sigmoid curve of benchmark score vs. ELO.
then some cross-benchmark comparison. Section 3.1 Mostly just describing their data, what tasks of different time horizons look like?
Section 3.2 Human baselining
- HCast and ReBench got a bunch of industry people from externally to do it, filtered out failures and cheating, and used estimates for some problems.
- Importantly, for each task, they need two things: 1. The time horizon of the task 2. The model’s success rate.
- For H-CAST, the human baseline is used to calculate one, the time horizon.
- For re-bench, The time horizon is fixed to 8 hours, and the human baseline is used to set the threshold for success on the task.
- For SWAA, They just did it all internally.