Interpreting Physics in Video World Models
physics in video models \+ V-JEPA background
V-JEPA 2 background https://arxiv.org/pdf/2506.09985 :
- Two training stages: Pre-training on Internet-scale video data to get useful video representations, Then freeze the video encoder and fine-tuning an action-conditioned predictor on a small amount of interaction data for zero shot robot planning
- demonstrated capabilities of V-JEPA 2:
- Understanding the physical world: Attention probes are very good at motion understanding tasks
- Understanding — Video Question Answering: Can train an MLP to take the output of V-JEPA 2 and transform it into the input to a LLM. This is surprising because V-JEPA 2 is trained without language supervision.
- Predicting future states
- Planning
-
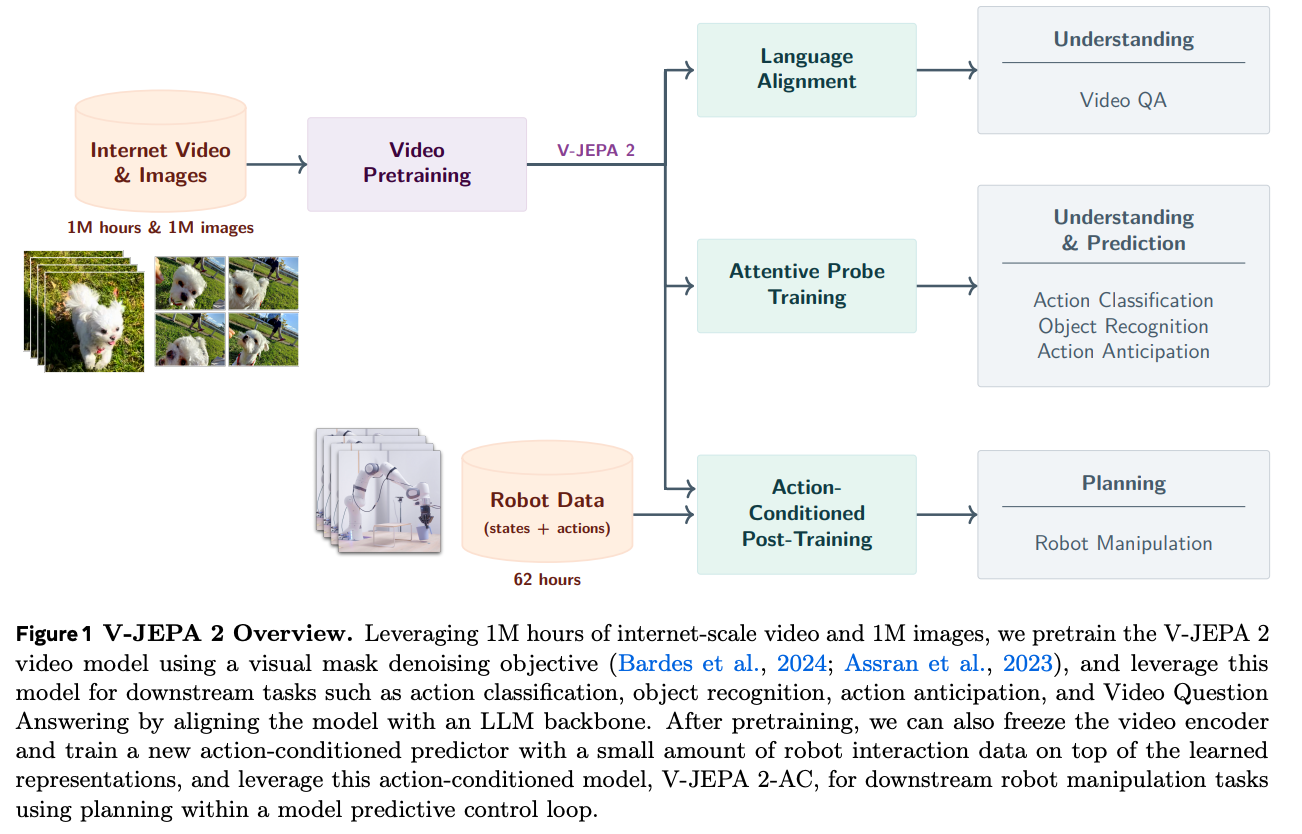
- Figure 1 is basically just what I mentioned above.
Figure 2: The training objective and process
-
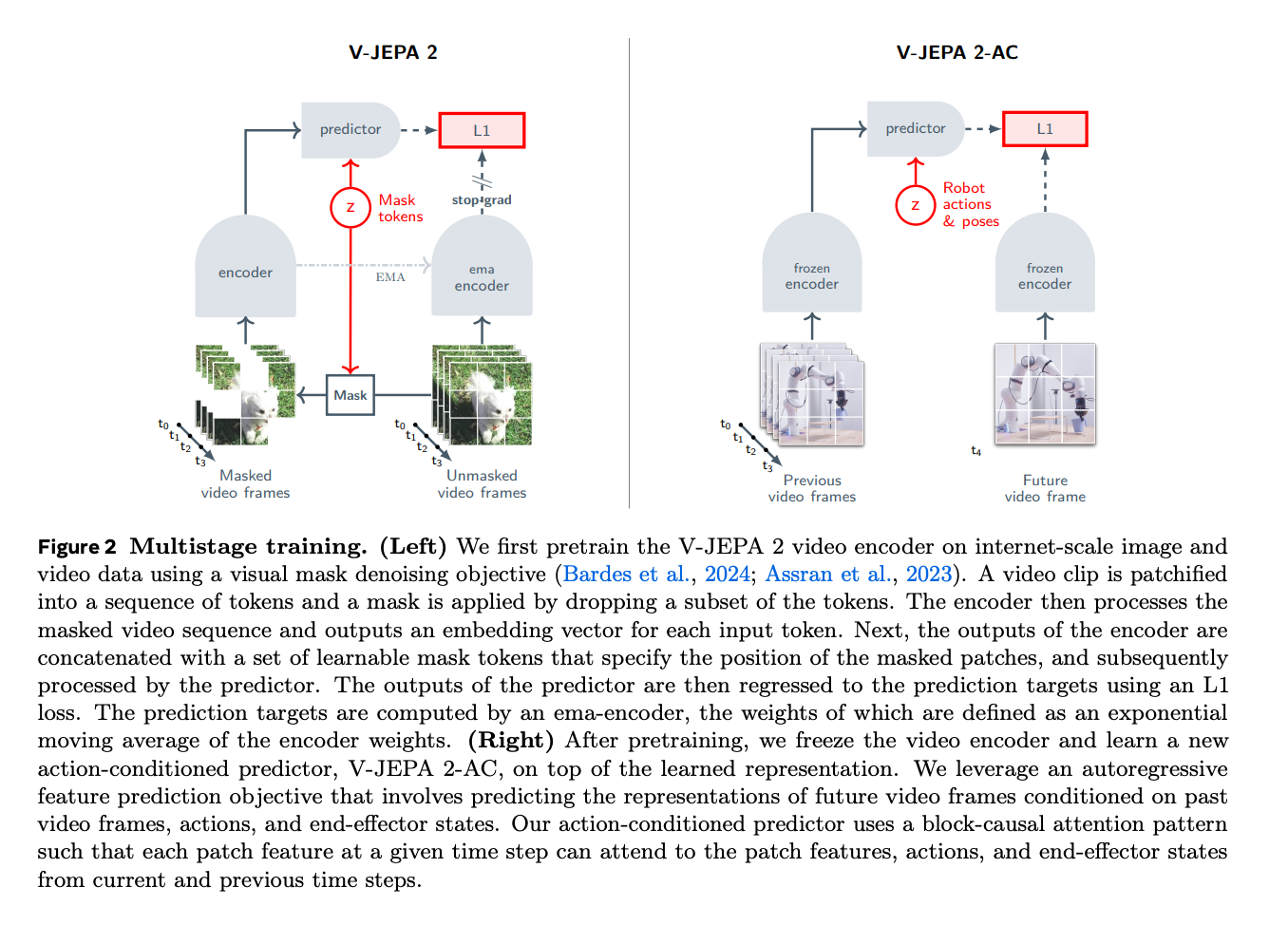
- Left, video pre-training: Use a masked denoising objective, Meaning, the masked image is put through the V JEPA2 encoder, and then, given the positions of the masked tokens and this encoding, the predictor has to predict the masked tokens. On the right side, the ground truth is generated by running the unmasked video frame through an Exponential moving average of the past few encoder weights (Without gradient backprop). The EMA is necessary so that the encoders don’t just agree to represent everything with zero. The predictor is usually discarded later.
- Right: Both the past video frames and the future video frame are passed through the frozen encoder. A new predictor (Which we’ll actually use) It is trained to predict the future frame, given the past frames, and the robot actions and poses.
Architecture:
- Both the encoder and the predictors are conv layer + ViTs (though the encoder is much bigger).
- Patchify the video into 2x16x16 tubelets first (time, height, width)
- Uses a 3D RoPE (time, height, and width)