MaxRL: Maximum Likelihood via Reinforcement Learning
Maximum likelihood RL
Credit to Zhening Li from AI@MIT reading group for leading the discussion really well on this one.
The objective function
 Normal RL mean objective vs. Maximum likelihood objective
Normal RL mean objective vs. Maximum likelihood objective
RL review: the reward isn’t a function of the parameters; the sampling of the policy is. How do we get around that in normal RL updates? 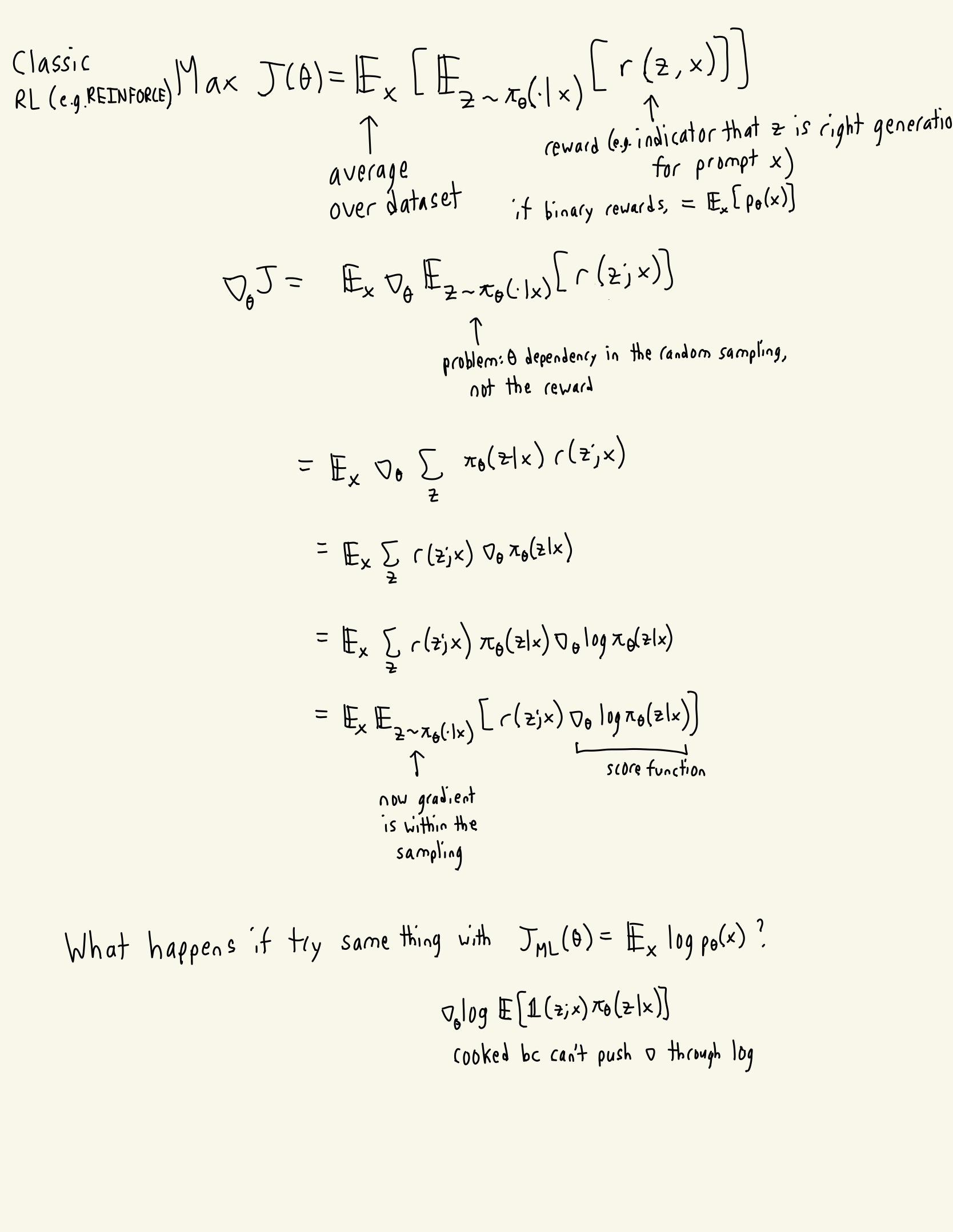
- We are inconsistent with whether or not we include the expectation over the dataset when using the term J. When J is a function of x, it’s for a specific prompt x.
So then how do we do a gradient update with this ML loss? By using a Maclaurin expansion of log.
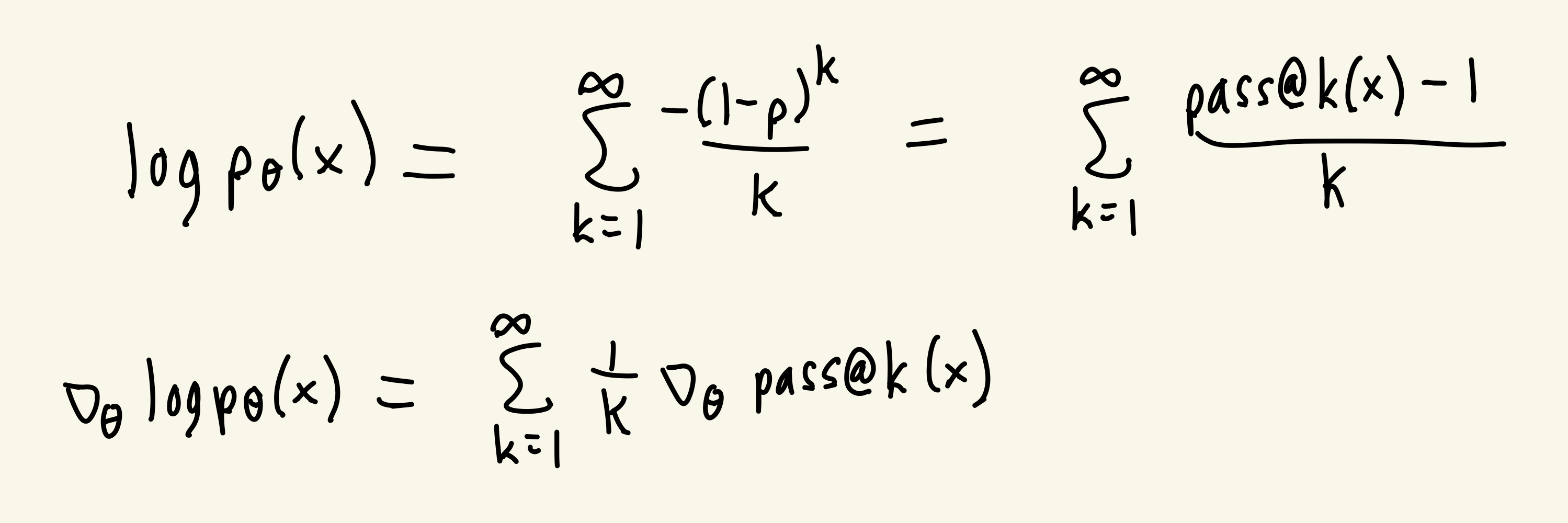
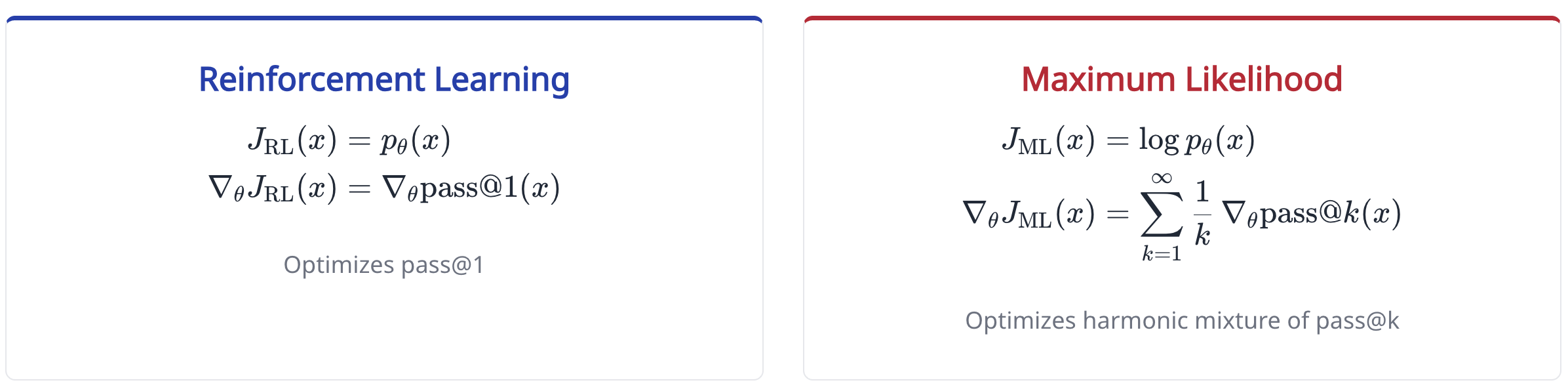
- This has a really cool interpretation: while normal RL maximizes for the pass@1, MaxRL maximizes a weighted sum of the pass@k, including higher values of k. This explains why it does so much better at pass@k for large k in Figure 1
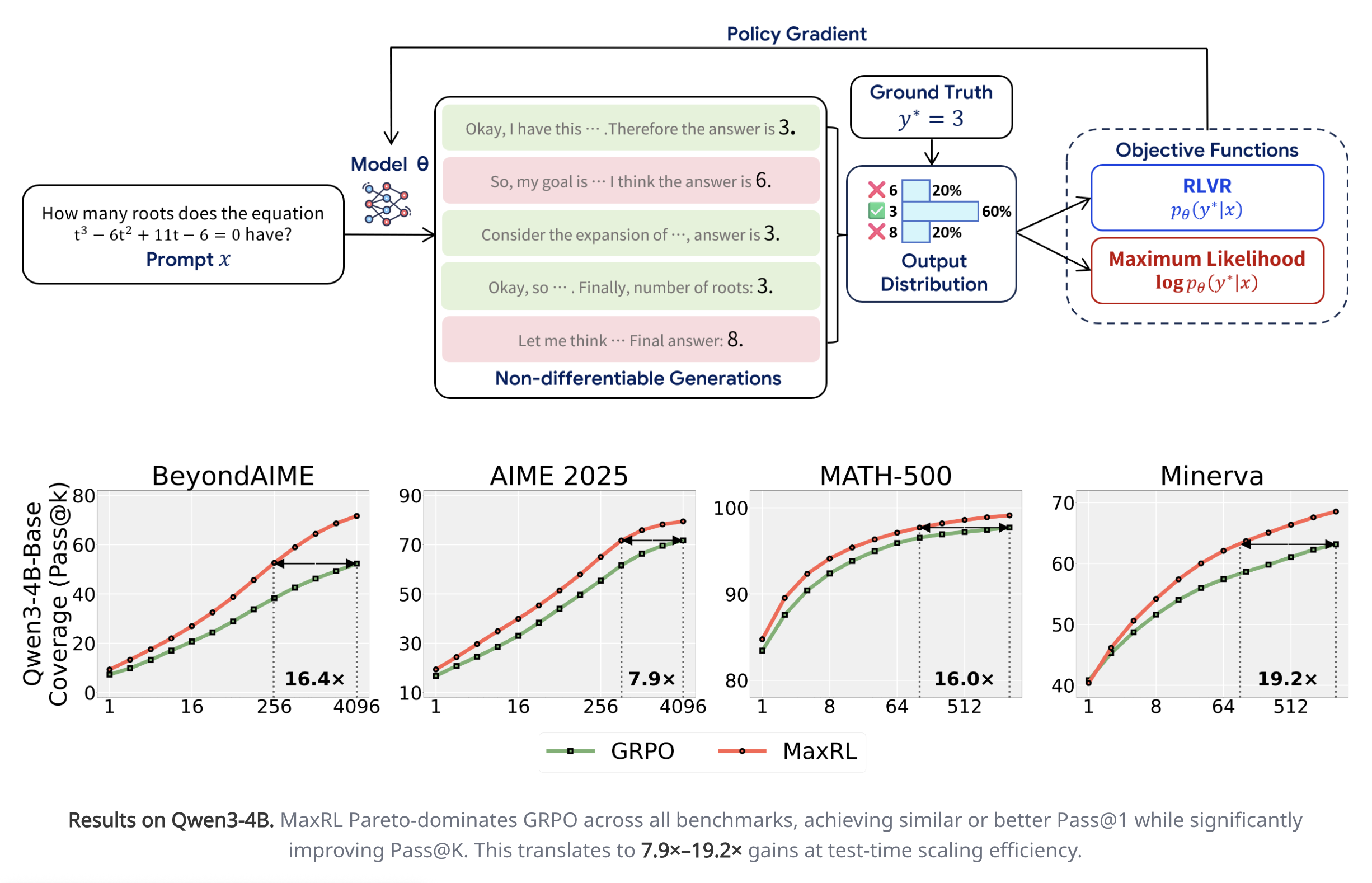
Another perspective on why MaxRL is better at pass@k for a large k:
-
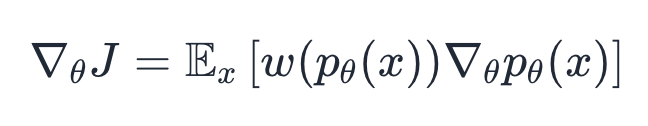
- All of the RL method objectives’ gradients can be viewed as a different choice of the weight to apply during the gridding update.
- Sense for MaxRL, w(p) = 1/p, this means that it weighs hard problems more.
- If you increase performance slightly on a hard problem, you get a much bigger increase for a pass@k on that problem than a pass@1
-
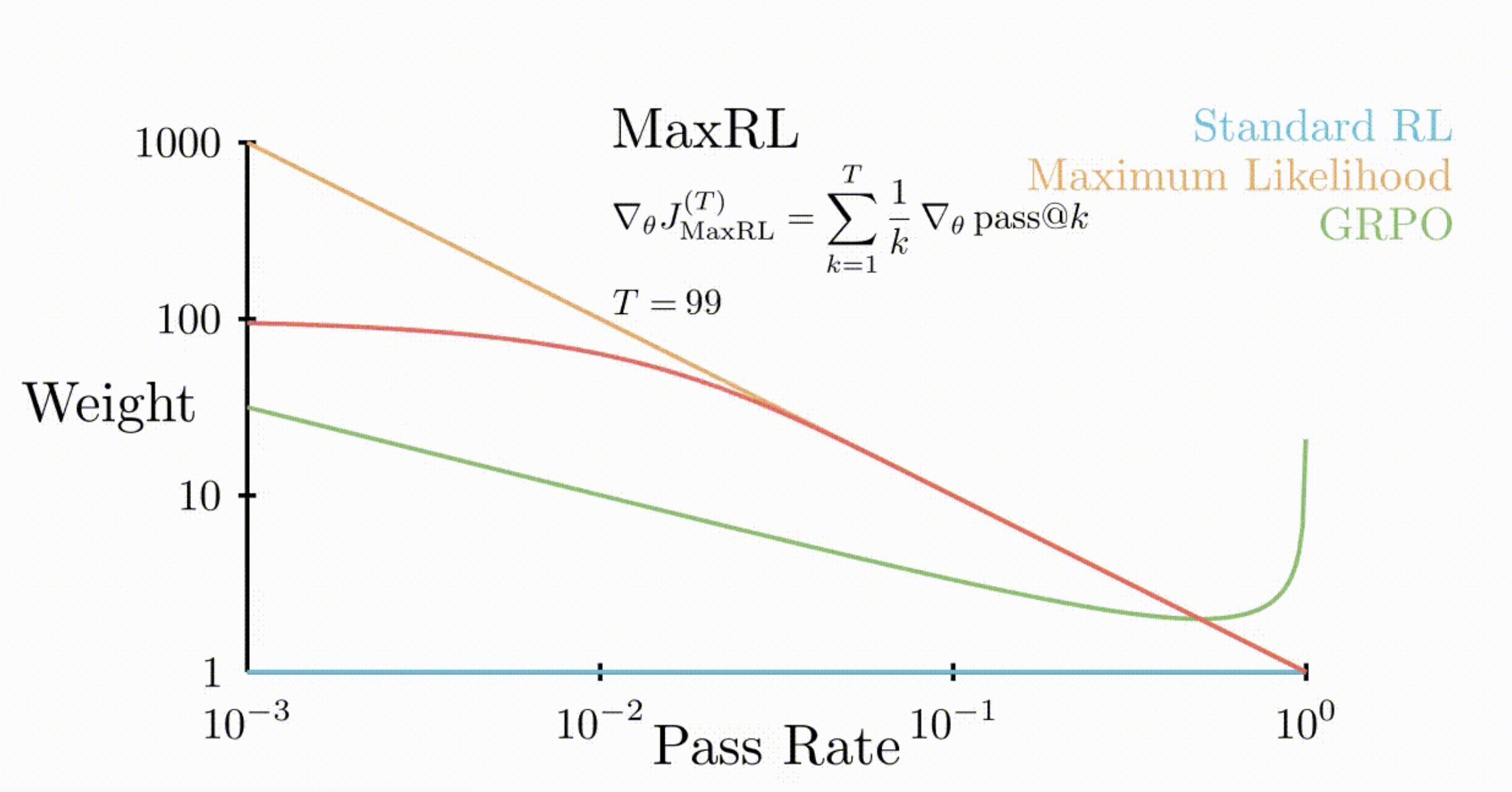
- Visually shows the above point that MaxRL weighs hard tasks much more than GRPO or standard RL
Instead of maximizing the infinite series, we’ll use different prefix lengths of the infinite series depending on our compute budget T. 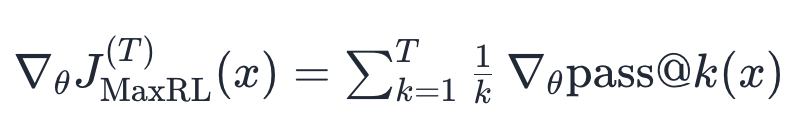
Estimating the objective function
Instead of approximating the pass@k’s individually, they use a second, very clever formulation. Their theorem 1 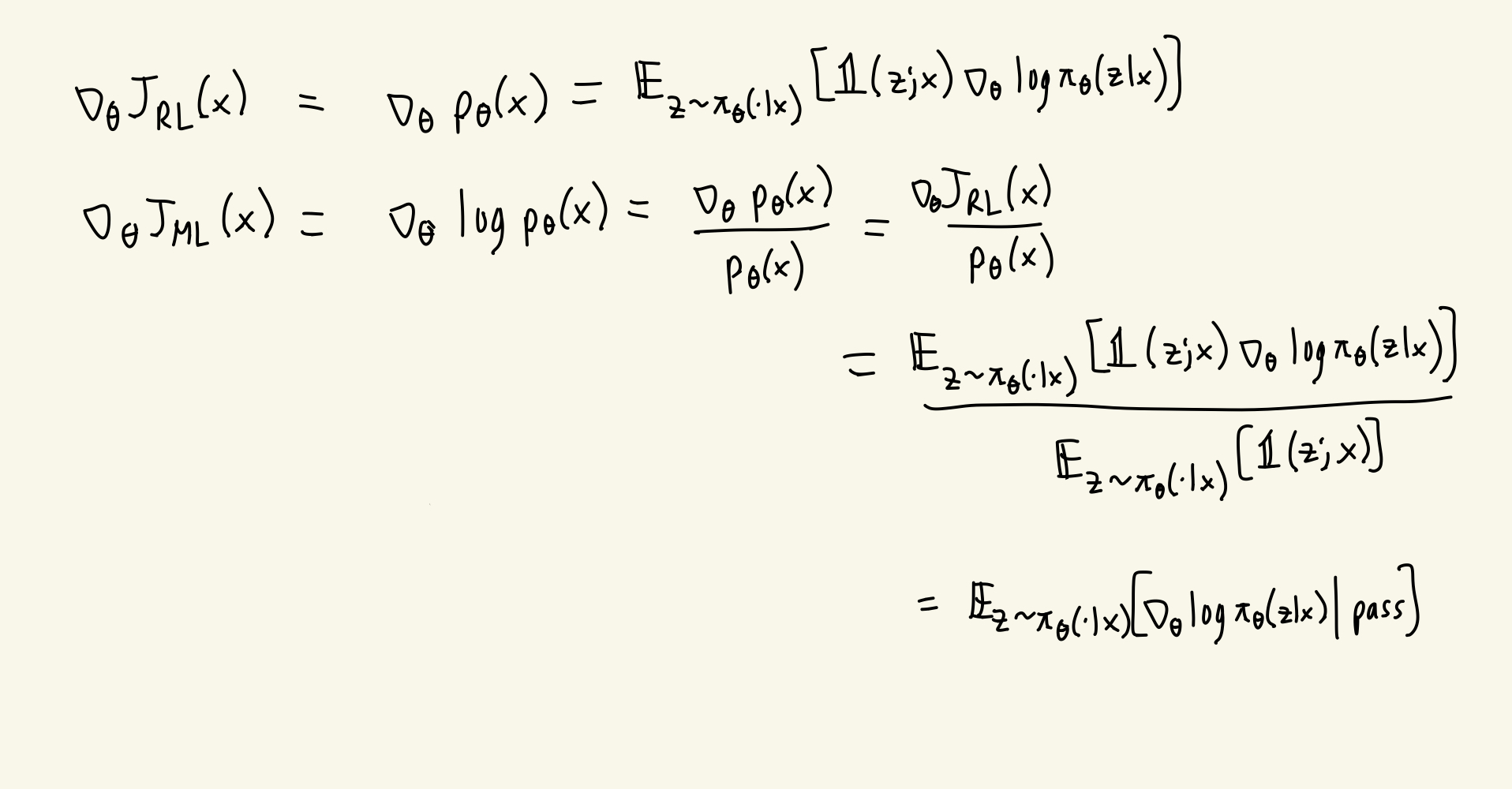
- Instead of multiplying the gradient by whether or not the rollout succeeded, you simply condition on the rollout succeeding and only use those rollouts to update your gradient.
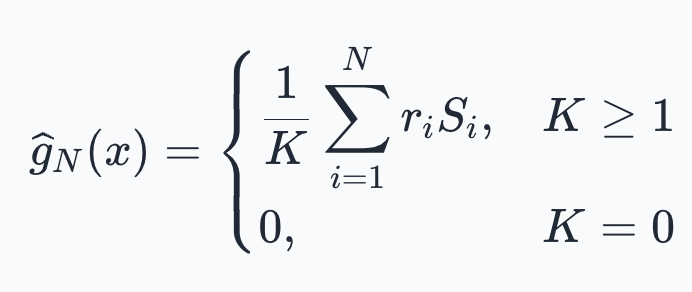
- You would think that this is an unbiased estimator for the actual objective, which equals to the infinite series. But because some of the time we have K=0, that is the only thing making it a biased estimator, as in those cases we have less gradient update per step than we should (you still have this problem of less gradient update per step if you just try again when K=0).
- However, by some black magic, Theorem 2 (proof in Appendix H), It turns out to be unbiased for the clipped at T objective
-
 So, this is their only difference in the estimators.
So, this is their only difference in the estimators. 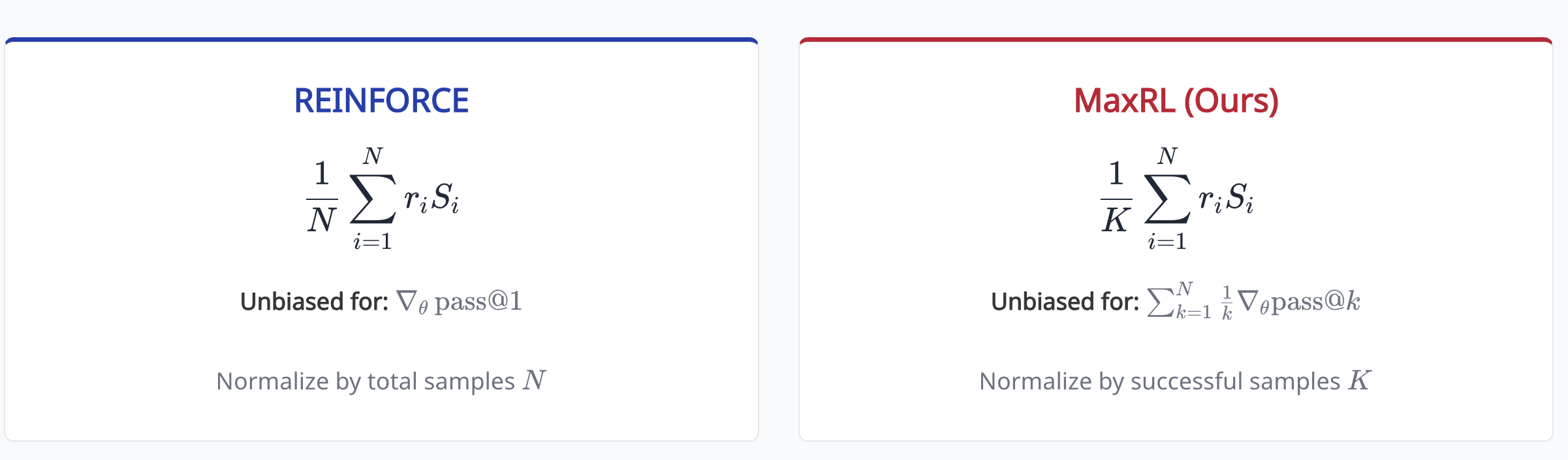
-

- This may explain why their methods scale better with more rollouts than standard RL methods. They are getting an unbiased estimator of an improving objective, instead of just reducing variance on a fixed objective.
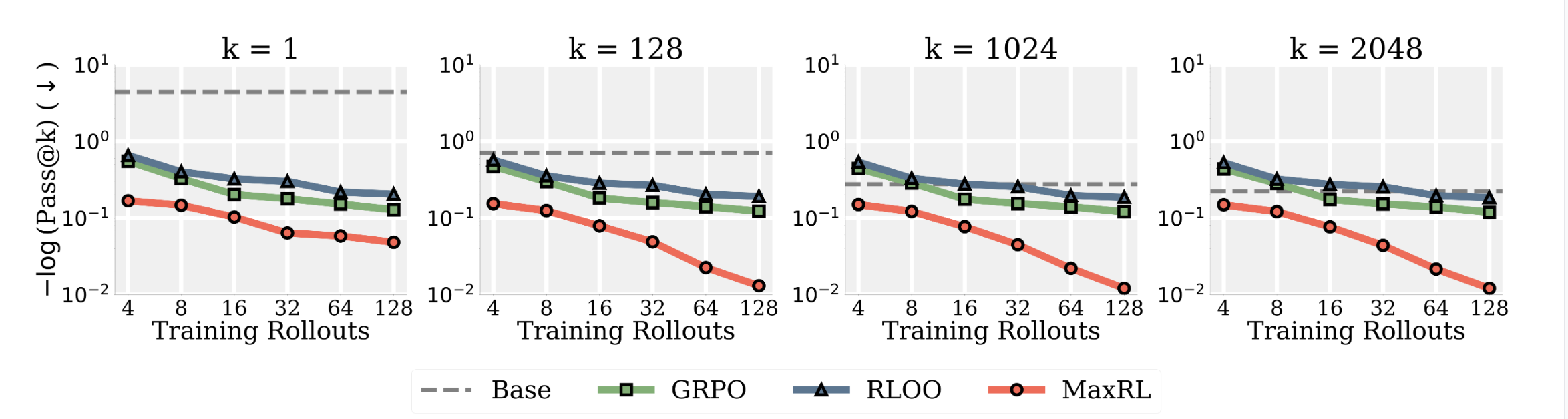
- Specifically the maze experiment. Lowercase k is just what validation pass@k they’re using. We see that, especially for higher values of k, as they increase N along the x-axis, they scale better than other methods at improving the pass@k
Other Experiments
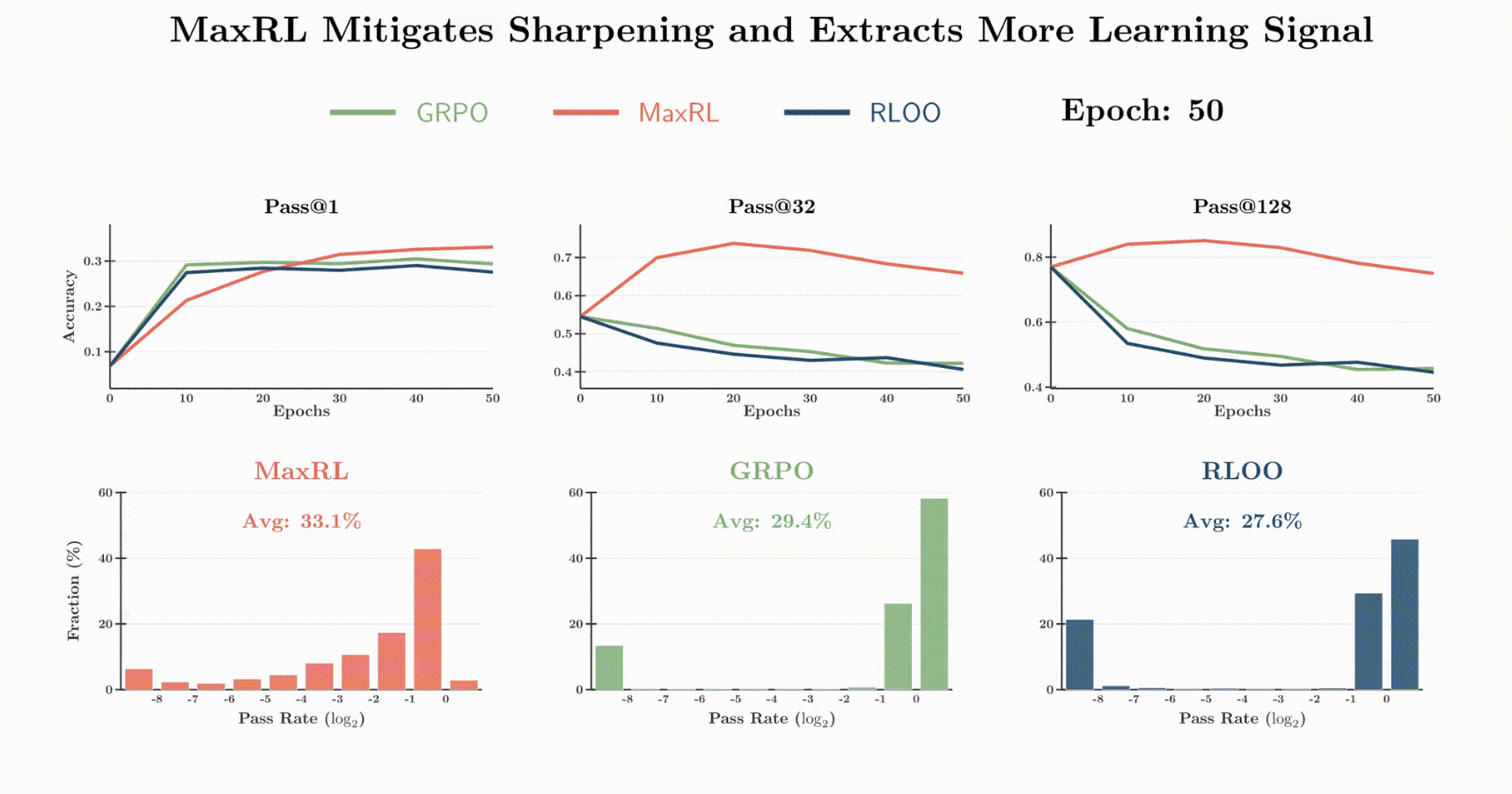
- This one confused us a bit. In the middle column, GRPO seems to have a pass rate of 1 on 60% of tasks, yet, at pass@32 , after 50 epochs, it has an overall accuracy of 0.4?
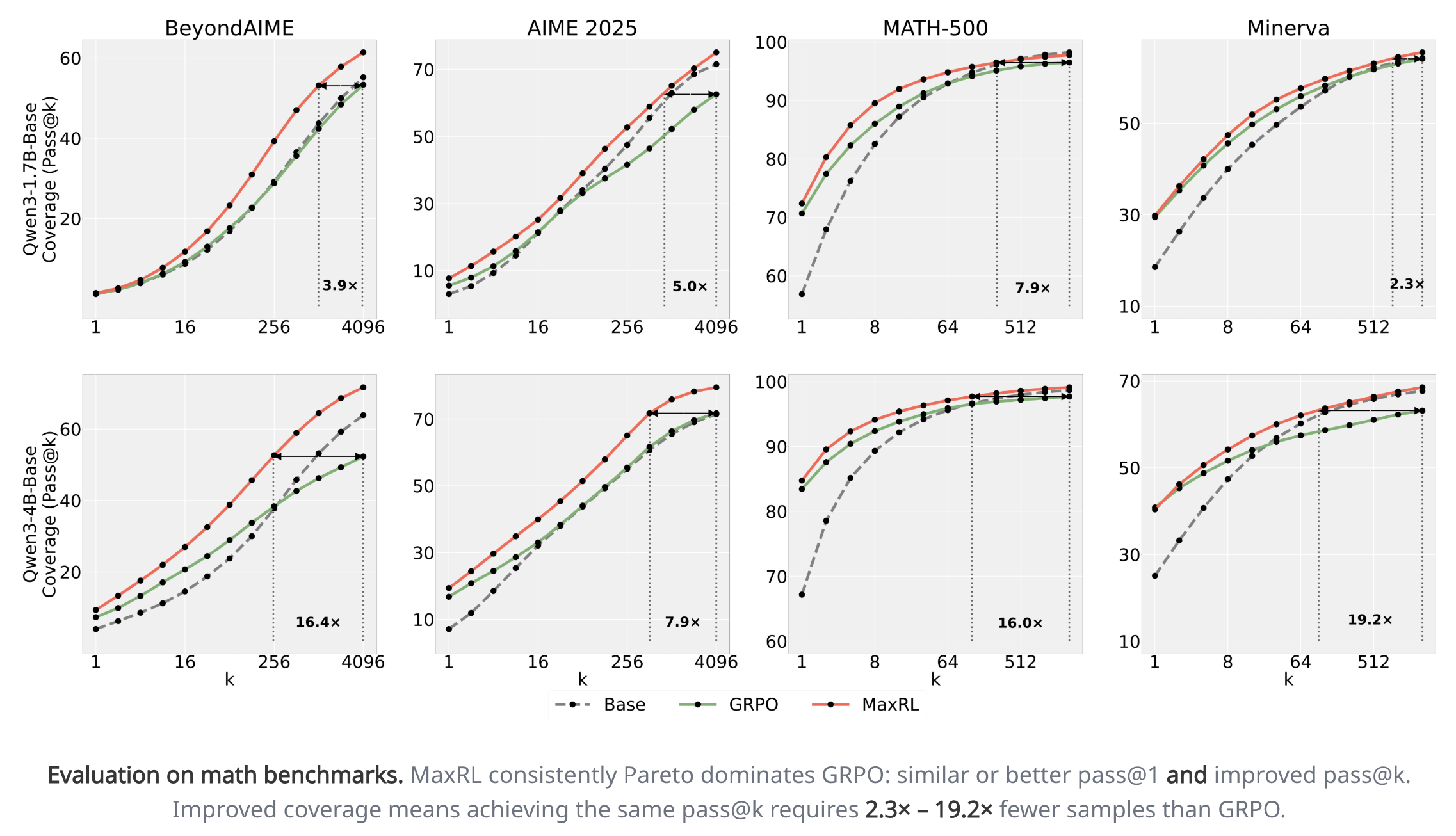
- On math, it does comparable to other RL methods at pass@1 and beats them greatly at pass@k
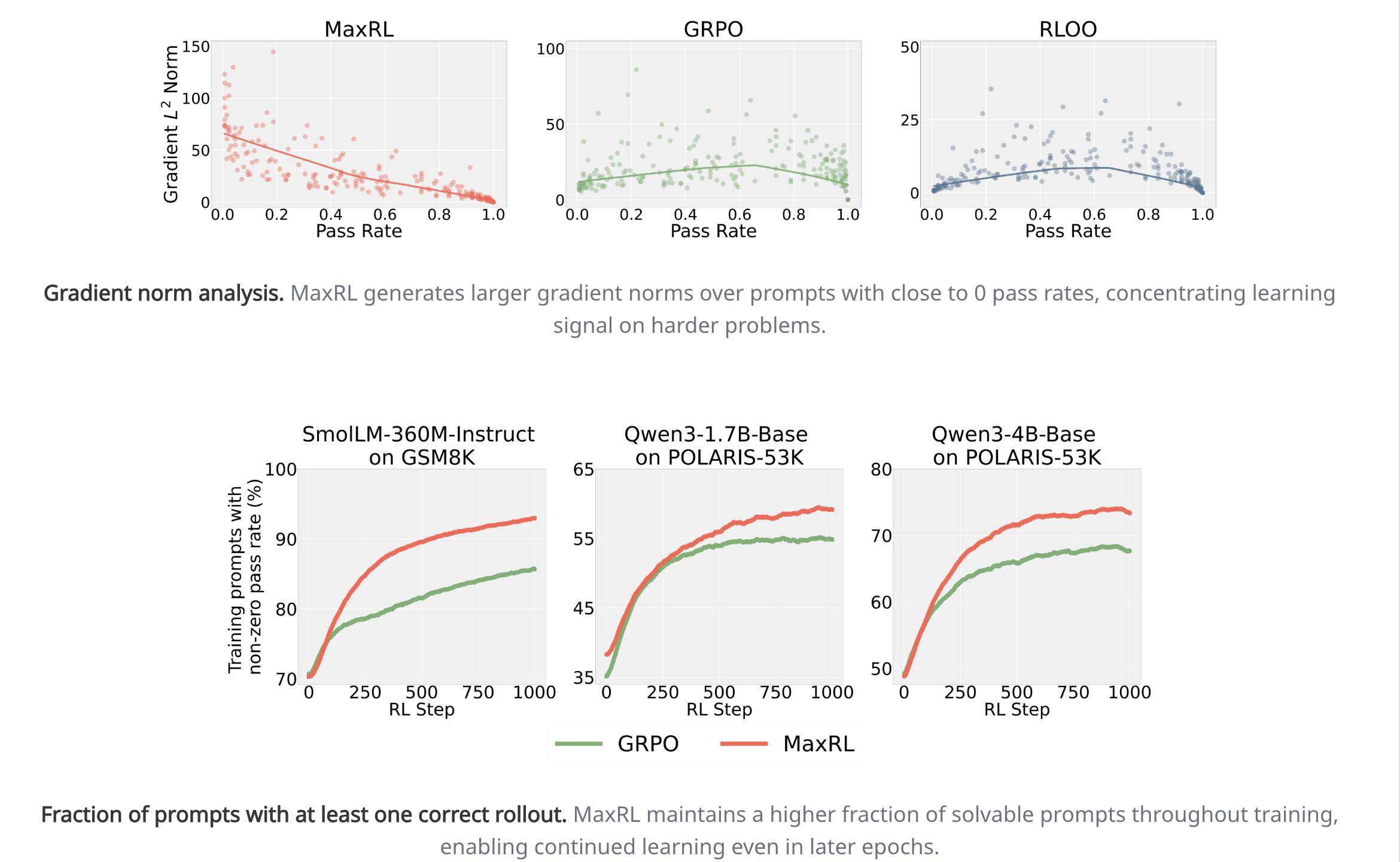
- Validation that MaxRL is (1) doing greater gradient update steps on hard tasks and (2) doing non-trivially on a lot of hard tasks