Localizing Knowledge in Diffusion Transformers
Localizing Knowledge in DiTs
Use attention scores to find the most important layers for different concepts, and then activation patch only those layers with an ablated prompt
project site: https://armanzarei.github.io/Localizing-Knowledge-in-DiTs/
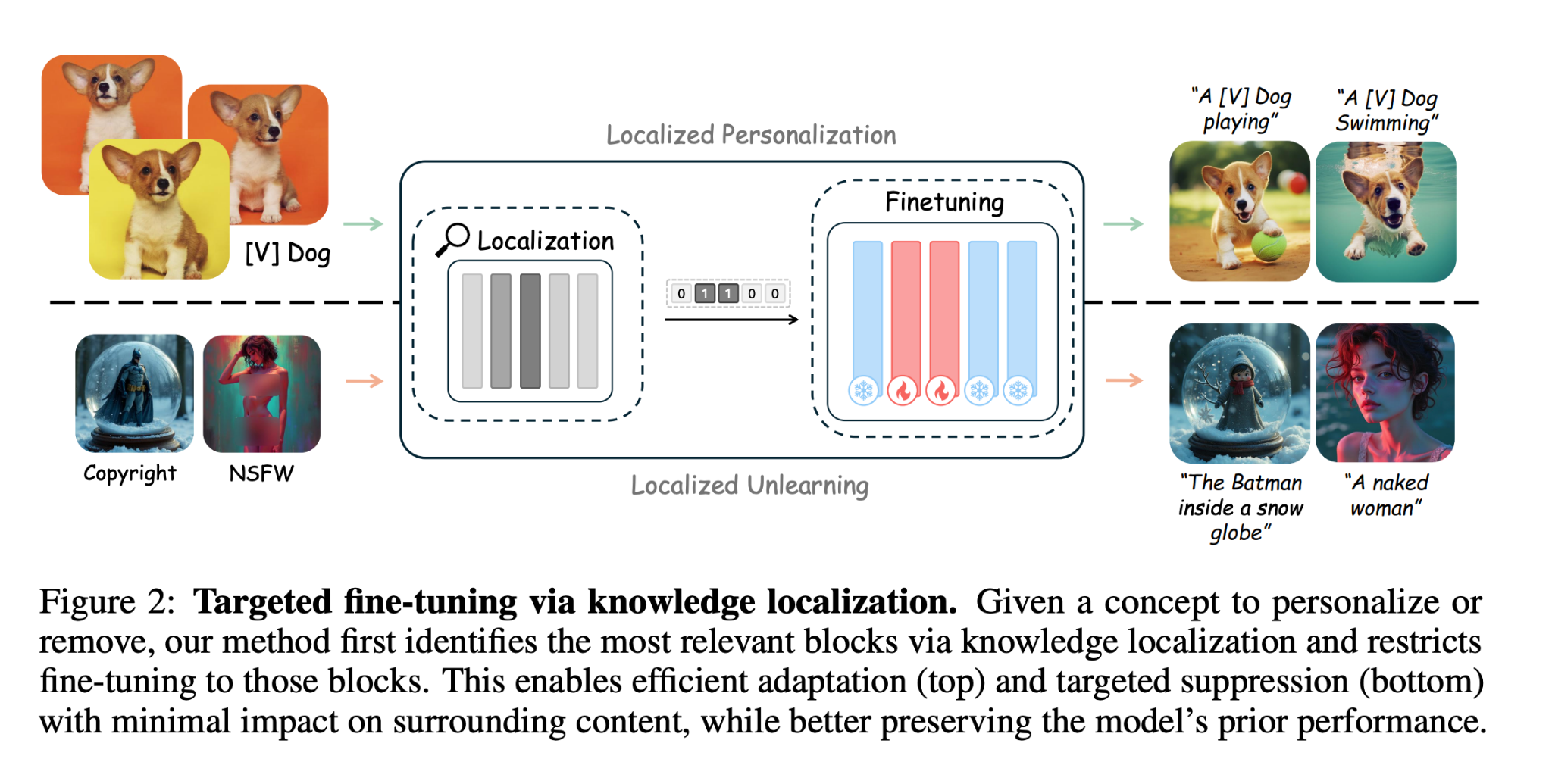 localize which blocks in the DiT are most responsible for knowledge of a given concept, then targetedly fine tune on those blocks in order to enable precise editing (e.g. forgetting copyrighted stuff or nsfw generation)
localize which blocks in the DiT are most responsible for knowledge of a given concept, then targetedly fine tune on those blocks in order to enable precise editing (e.g. forgetting copyrighted stuff or nsfw generation)
Related Works
- cites a bunch of works on interpreting layers in UNet based diffusion models
Data
- constructed a paired prompts dataset ablating the inclusion of each of the knowledges
- “the Batman walking through a desert” vs “a character walking through
- a desert”
Methods 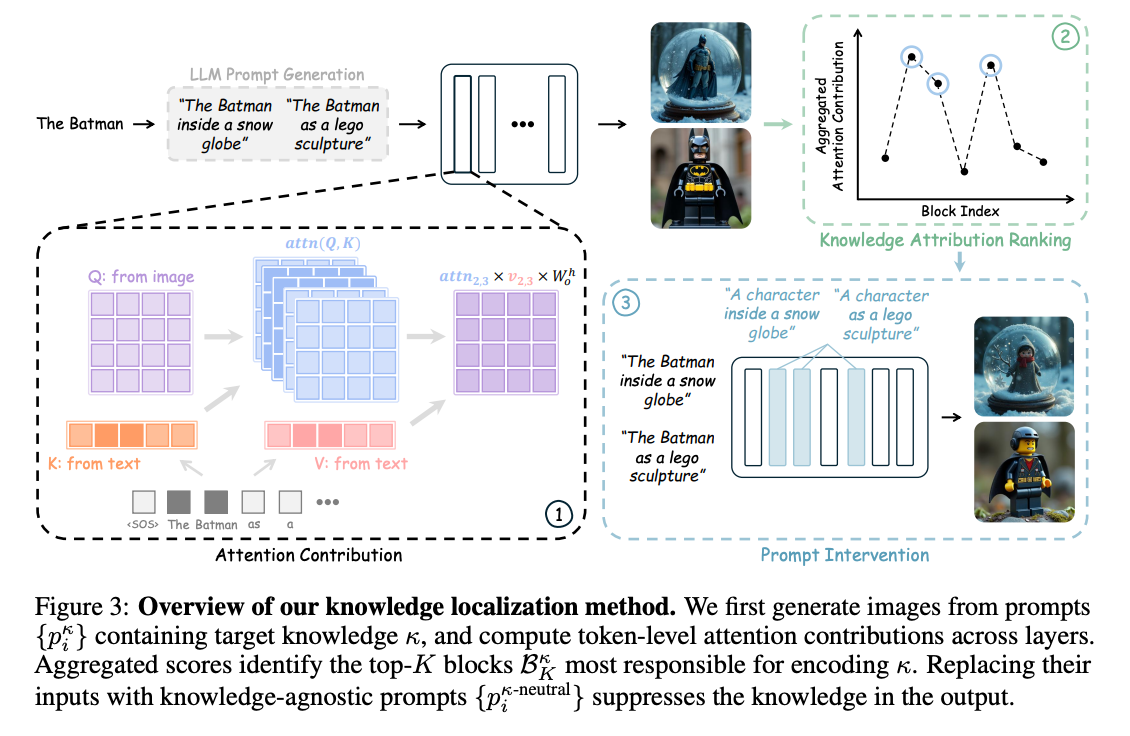
- Finding the attention layers that are most relevant for a given knowledge: they go through each of the layers, and for each layer, for each text token that contains the knowledge, they calculate the value-weighted attention contribution averaged over all the image pixels as key/values, and then they average this over many prompts containing the knowledge. They use this as a score for each layer, and take the top k layers.
- Then, using the corresponding prompts that don’t have the knowledge, they patch the activations over for only these top k layers.
Experiments
- PixArt-α, FLUX, and SANA
- Metrics: CLIP and llava question answering to tell if a knowledge concept exists in a picture. Contrastive Style Predictors metric for specifically style.
- Different types of knowledge took different levels of K in order to completely ablate
also applied their methods to Concept unlearning and model personalization: Use the methods for finding the most important attention layers for each knowledge, And instead of fine-tuning the whole model, fine-tune only those layers.
- model personalization: DreamBooth
- unlearning: used their own Lock dataset