Reliable and Efficient Amortized Model-based Evaluation
IRT difficulty prediction
In particular, the Fluid benchmarking modeling paper came in september 2025, after this one.
This one makes the claim that it takes way too many model evaluations on a dataset in order to actually get a good calibrated difficulty score. They use this to motivate
- training a linear model on problem embeddings to predict the difficulty of a problem
- training a model to generate new problems of a certain difficulty
in order to reduce the cost complexities of question difficulty calibration and question bank construction
their motivation on why you would need to add questions to an existing benchmark (which requires quickly predicting difficulty) is to replace contaminated questions (He & Chen 2020; Zheng 2014)
But the september one goes ahead and just does it anyways using OpenLLM training data, which lowkey calls into question this paper
Section 3 of this paper
just summarizing the same process as the Fluid benchmarking paper about how you do IRT: you use EM algorithm to estimate the abilities and the difficulties (they only have one parameter, not 2 parameters like Fluid benchmarking).
Then during evaluation, once you have a calibrated dataset and a current estimate of the model’s ability, you keep selecting the question that has the highest fisher information from the remaining dataset, and then you re-run the EM algorithm to get the new abilities and difficulties estimates
Section 4.1 Training the difficulty predictor
Hoping to get a predictor that generalizes across datasets. One advantage of training a model as opposed to just using each question as a blackbox question id is that they get to embed the text of the question as an input into the model.
Still EM algorithm:
| E step: predict the levels of ability theta, based on the observed responses Y and p(Y | theta, z), as well as using the fixed predictions z from the neural network of the question difficulties |
M step: fixing our guesses for ability levels of each problem, update the neural network weights to maximize the likelihood of the observed responses from the predicted difficulties from the neural network
Section 4.2 Training the question generator
the idea being here that choosing the “question with the highest fischer information” actually means choosing the difficulty score with the highest fischer information, and then choosing the question from our dataset with the closest difficulty score to that, so at that point why not just have a generator directly generating questions with different difficulty scores?
trained an LLM using SFT and PPO, with the reward being the negative distance between the predicted difficulty and the target difficulty of the question
Section 5 experiments
22 NLP datasets, 172 LLMs, binary responses, masked 20% of data for testing For numerical stability, they don’t include any test takers who have exactly the same responses as each other (section 5)
First, only using IRT, not using their difficulty estimates or question generator 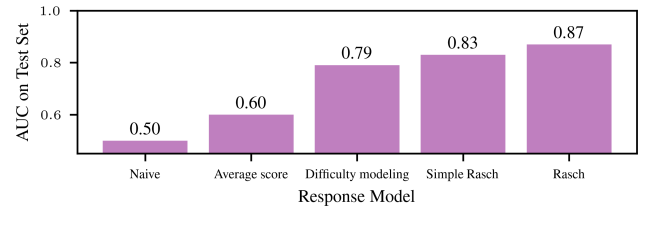
Use different response models, train on agent x task pairs, and then see how well they predict how the model is going to do on a held out set of agent x task pairs (but where no agent or task is new)
Rasch Model achieves an AUC of 0.83: means that if you randomly select an example where the model got the answer right, and an example where the model got the answer wrong, there’s an 83% chance that the IRT model assigned a higher probability of success to the correct instance
- “average score” baseline: always predict that the model has the same chance of getting the question right regardless of the actual question itself, where the average score is the score on some randomly selected subsample
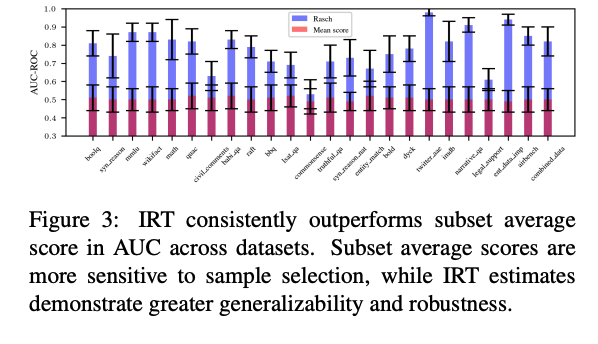
- this is another view on the same experiment / metric I think. Red bar just shows the AUC on different datasets of the “Average score” baseline, and blue bar shows the Rasch 1PL method
- find unsurprisingly that Average score is quite susceptible to the subset that you choose
In addition to AUC, they also use as a metric the correlation between model ability and model performance on the entire benchmark (section 5)
strong generalization: for an IRT score trained on two samples, you can use their learning from subsample technique to get a good estimate of the IRT ability score with fewer sample samples. They compare this to just directly calculating the average score in the sub sample
- For their first strong generalization experiment in section 5.1, they actually do have a little bit of data leakage. They’re using IRT difficulty scores that are trained on their evaluation set
- For their second experiment, they explicitly say that they actually do hold out the one test taker from the IRT calibration. Then they try to learn the IRT ability of this held out test taker using a much smaller subsample, and compare that to if they just use the average score as the ground truth, mapped using the logit function in order to be directly comparable to the IRT ability parameters (this part is a little sus, apparently IRT ability to be mean 0)
They actually predict the IRT ability of a model, directly from its training, compute FLOPs (section 5.1)

- the AUC scores are similar whether you train traditional calibration or use their model difficulty predictor.
- CTT correlation is how well the ability estimates (attained via either traditional calibration or amortized calibration) align with the actual average accuracy of the models on the full dataset
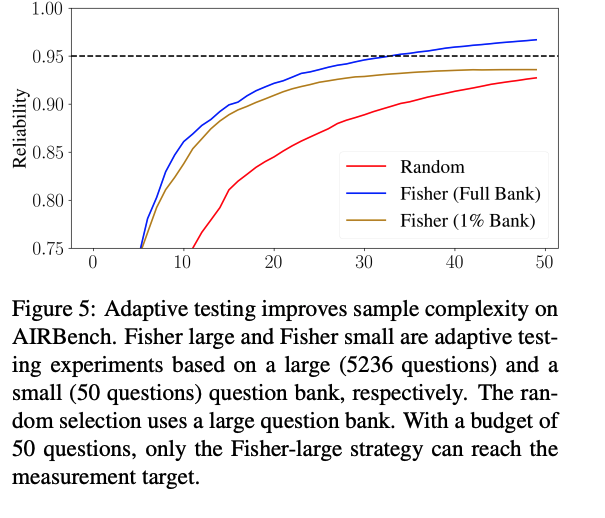 Goal of this experiment was to show that you need a large dataset for adaptively choosing problems to work well (motivation their question generator)
Goal of this experiment was to show that you need a large dataset for adaptively choosing problems to work well (motivation their question generator)
metric is reliability, some measure of how precise the measurement was 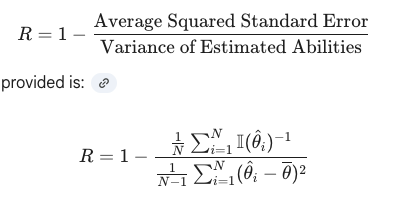 reduced questions needed by 53% on average
reduced questions needed by 53% on average
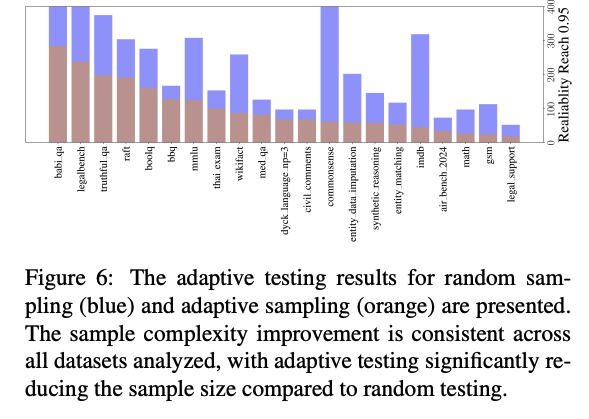
- another view of the same experiment
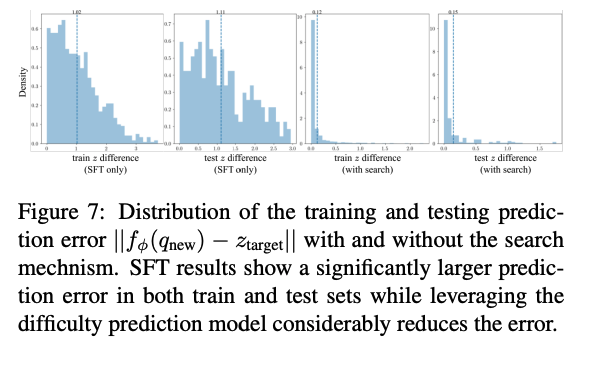
- “search mechanism” just means have their generator generate multiple questions, and then use their difficulty predictor to pick the one that’s closest to the target difficulty
- 0.96 correlation between difficulty estimates of original questions and mixed set including their generated questions
Some text only experiments / metrics:
- can somewhat predict latent ability theta based solely on pre training compute budget using scaling laws (so “ability” is not some bs arbitrary thing ig)
- 2PL and 3PL did not significantly improve performance over 1PL