HunyuanVideo: A Systematic Framework For Large Video Generative Models
Hunyuan video
Section 3. Figure 4, hierarchical data filtering 
- They later do curriculum learning, going from low-resolution to high-resolution long videos.
Data annotation via their in-house captioning model.
Architecture
3D VAE trained with some interesting reconstruction loss terms 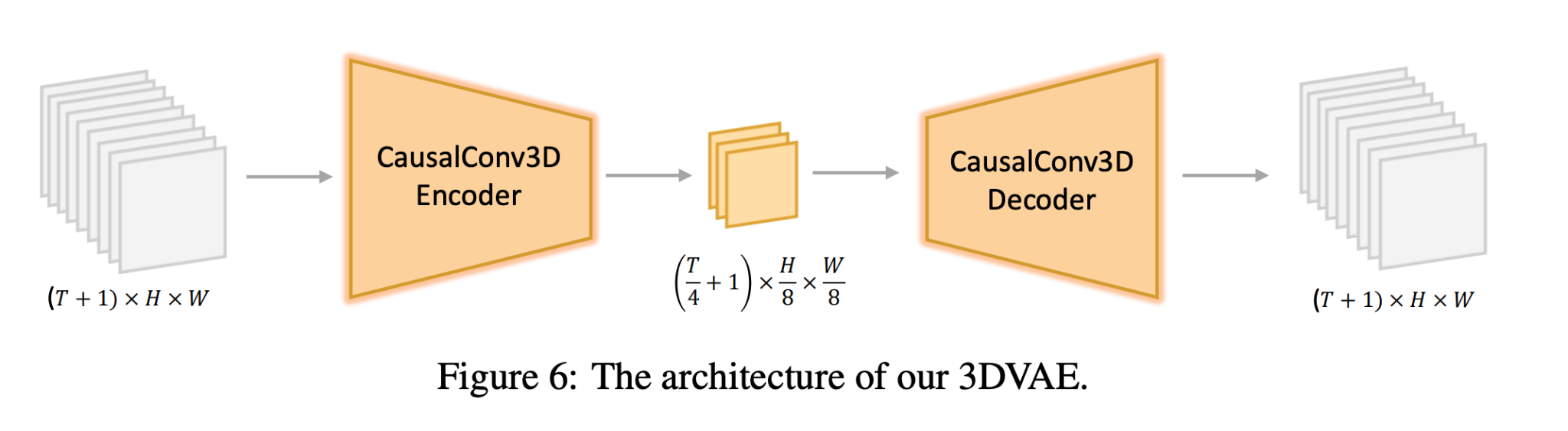
Even this is not sufficient compression for high-resolution, long videos, so they do extra spatial-temporal tiling.
Their architecture is actually very similar to Flux, with the dual-stream and single-stream blocks. 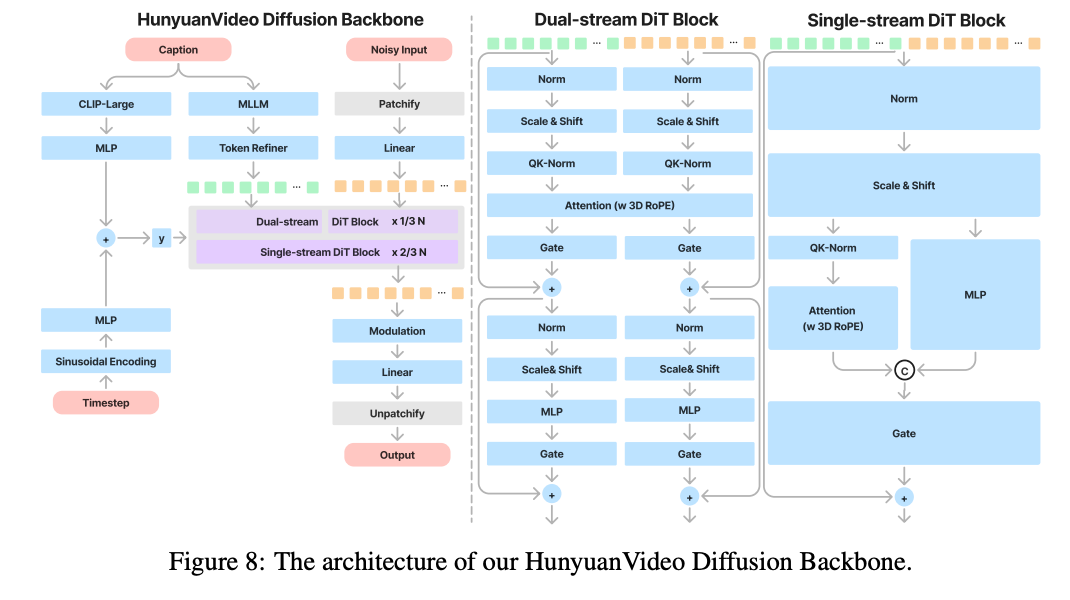
- 3D RoPE: rotation matrix calculated separately for each of the three dimensions (height, width, and time)
- out of the 128 dimensional attention features, first 16 dimensions are time, next 56 are height, last 56 are width (d_t, d_h, d_w)
- This seems to be just arbitrarily chosen for only the 3D rope. It’s not reflected anywhere else.
for their text encoder, they use CLIP-Large and a multimodal LLM (+ bidirectional) 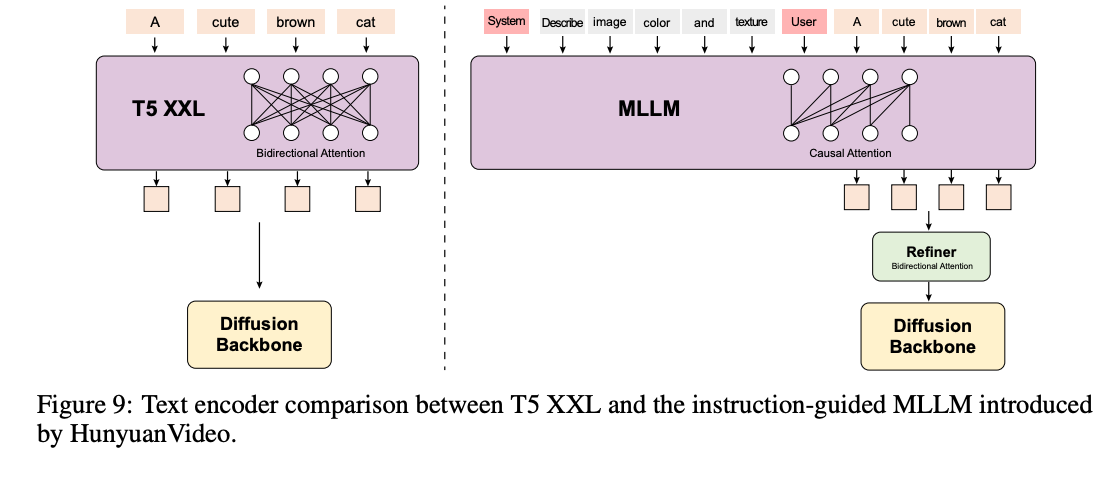
Scaling laws: Video models are trained from pre-trained image generation models, so need scaling loss for those as well.
Training
Literally exactly the rectified flow objective. First images:
- First 256 x 256, then a mix of 256x256 and 512x512 (Otherwise, it forgets how to do low-resolution)
Then jointly images and videos (there is very little high-quality video data)
tricks:
- LLM to standardize prompts
- Fine-tuning on really good quality data at the end.
Optimizations, Results, and Applications
Optimizations:
- Interesting times schedule to cut down on inference steps
- Distilled model for classifier-free guidance that doesn’t require two passes.
- Many types of parallelism.
Human evaluations mainly, against other open-source video models. Video-to-Audio (V2A) Generation, Image-to-Video (I2V) Generation, Avatar Animation