Generative Modeling via Drifting
Drifting
Notes after a talk by Minyang 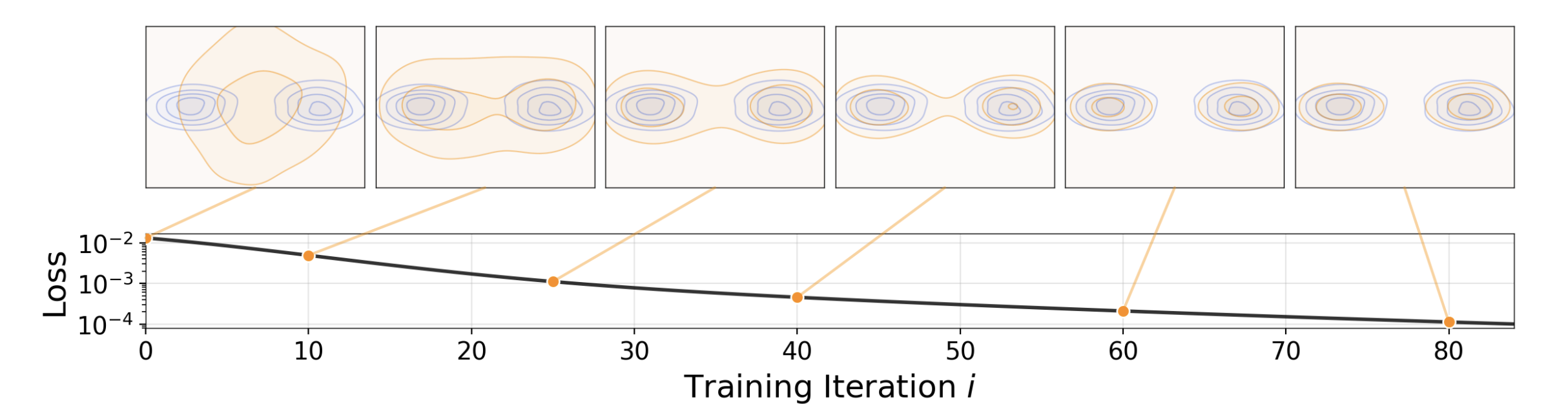
- Figure 1. Their goal is to train a one-step image generation model. There’s some sense that this being more end-to-end than the normal diffusion step-wise training loss.
- They do this by having the “current distribution” (i.e. the result of feeding a Gaussian distribution through their forward pass) change during training to align with the target distribution of the data
Key Idea: define a drifting field V_p,q (in terms of the current distribution q, and the target distribution p), that specifies at each point in the distribution, how it should move to more closely match the target distribution.
- Critically, p = q should be a fixed point of this drifting field, like it should map every point to itself and be an equilibrium
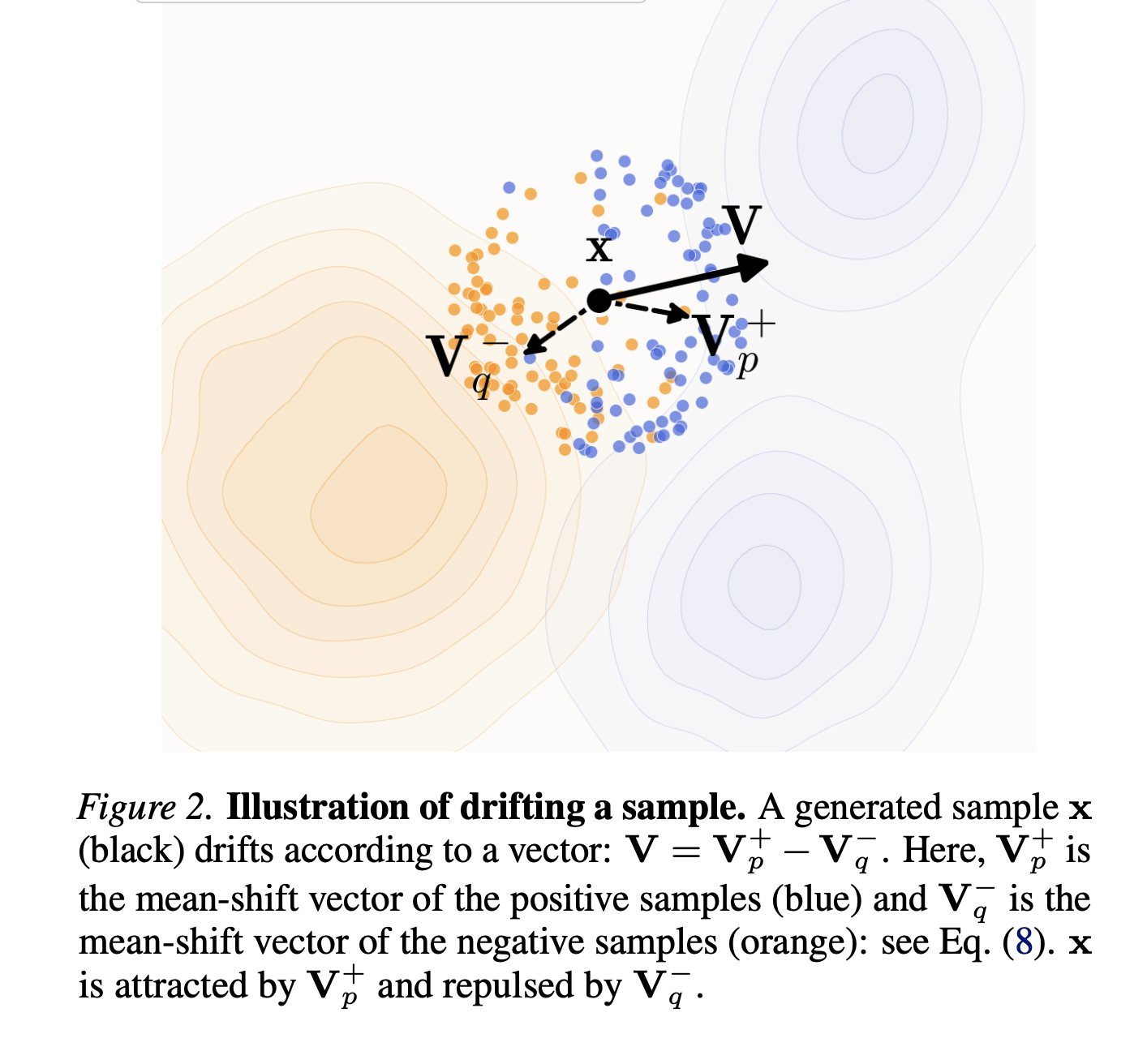
- Figure 2. They found that many drifting fields work, for this paper, they just chose a simple one, which attracts to the local (weighing local points more heavily) centroid of the target distribution, and repels the local centroid of the current distribution.
-
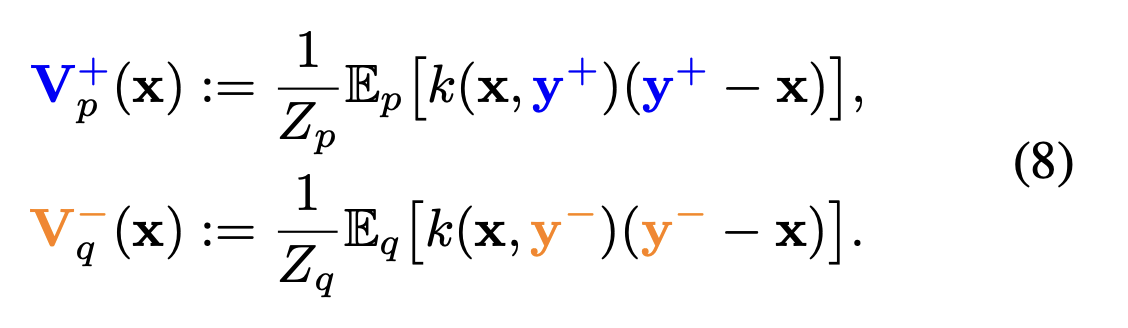
- Estimated using Monte Carlo sampling.
Using this drifting field V, we can update points via 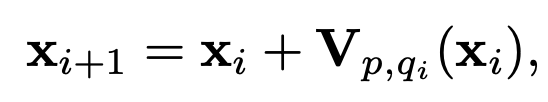
- where “points” in reality is sampled outputs of the network from adjacent weight checkpoints during training (since we’re trying to evolve the distribution through training)
-
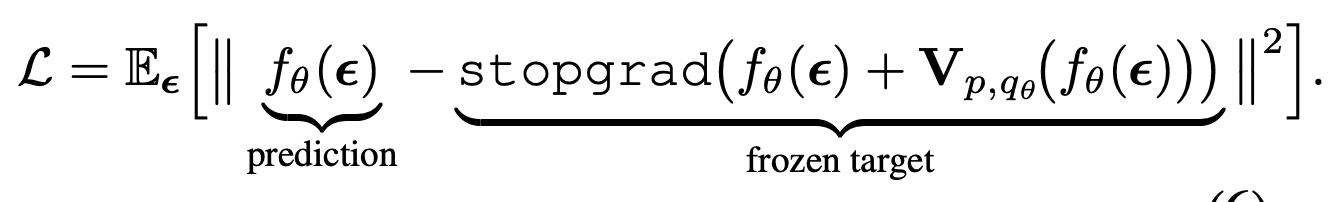
- Translates into the following loss function. The stop grad is just because we are only calculating this drifted version of the current point to use it as a label, not using it as a prediction.
One problem with the current method is that the points for estimating the drifting field are uniformly sampled, so in the high-dimensional pixel space, it’s pretty unlikely to get a useful local sample. So their fix (this is kind of a shoddy fix, according to Mingyang, and he thinks they can do better), they drift in feature space. They use their own trained latent MAE (Table 3)
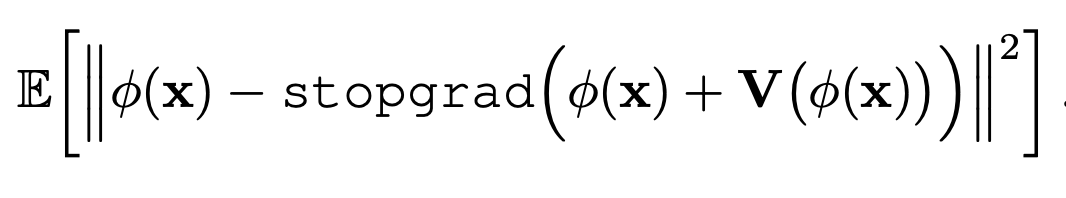
- The analogy that he made is that this is kind of like training RL. In normal diffusion with multi-step, you’re actually going off policy, but in drifting, you are on policy. The problem is reward sparsity, which is sort of the same problem here because you have high variance in your sampling of the drifting field.
Experiments
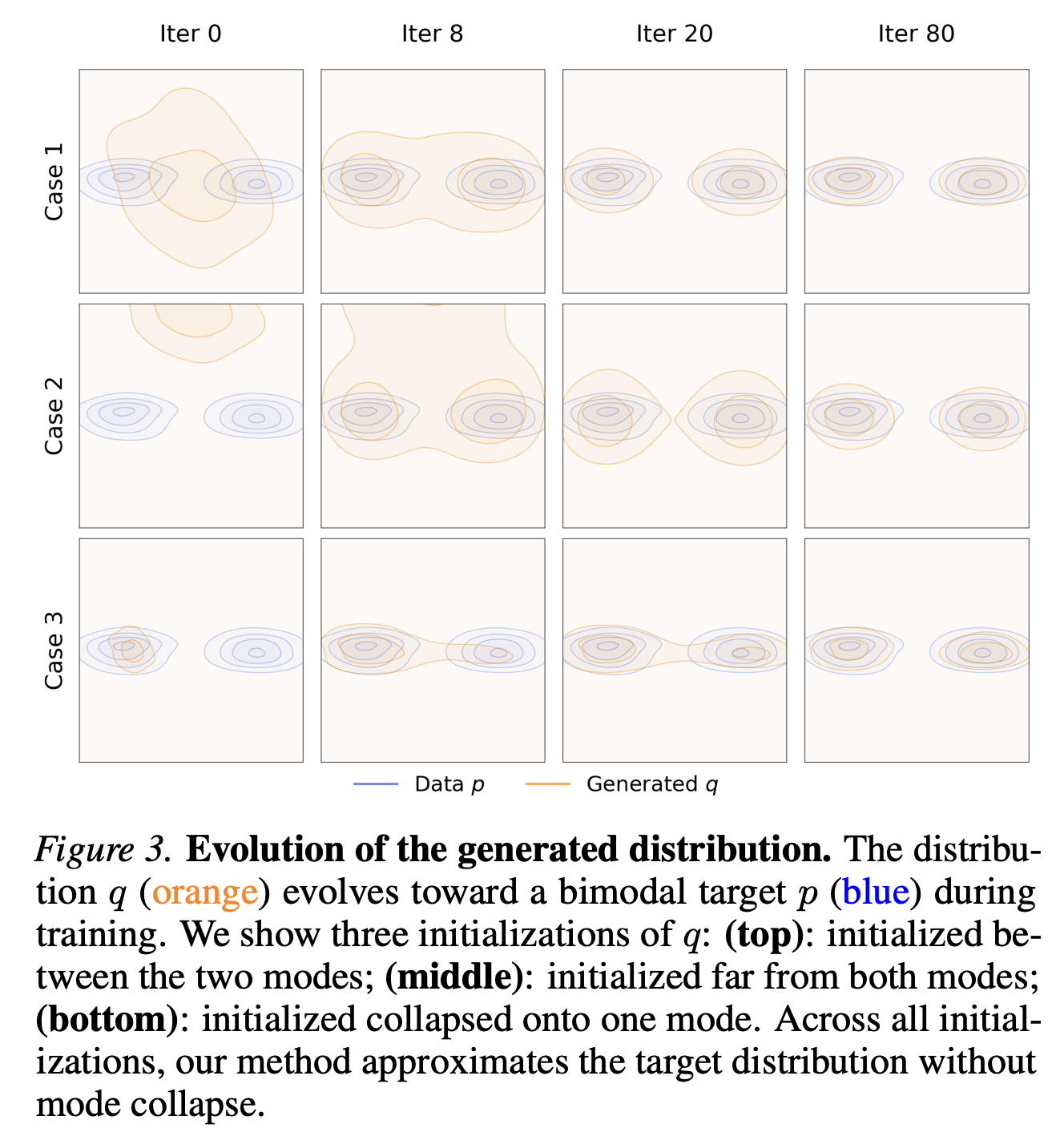
- Figure 3. The interesting result from the toy example is the bottom row, where even if you initialize fully in one mode, it actually doesn’t mode collapse and spreads out to the other mode as well. This is because apparently the attraction to the mode that you are in and the repulsion from the existing data cancel out, leaving just the attraction to the other mode.
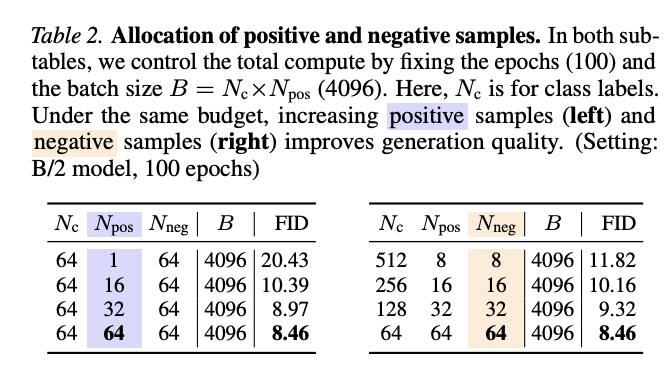
- Table 2. Somewhat predictably, generation quality improves as you increase the number of positive and negative samples used for the drifting field estimation
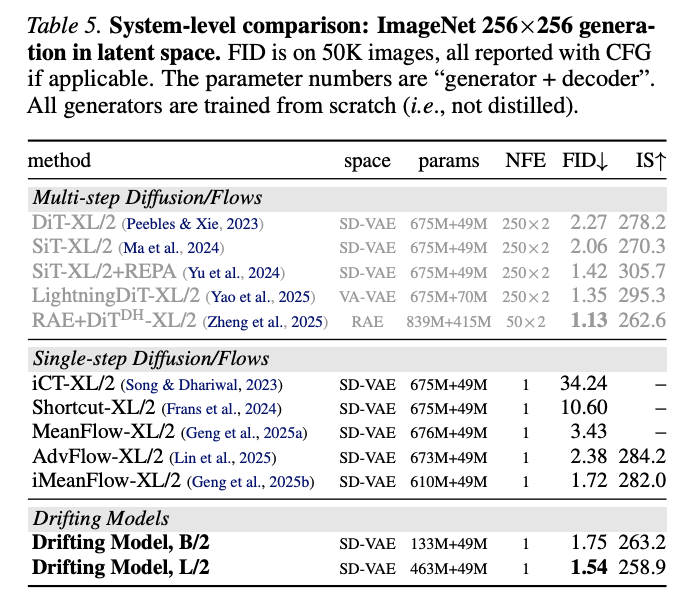
- Table 5. Not the absolute best FID on ImageNet, but pretty good given that they’re single-step.
My question from the talk: Can be used for T2I, you’ll just only have one positive example. T2I is actually easier than ImageNet, though apparently, because the conditioning is much stronger compared to class conditioning for ImageNet.