On scalable oversight with weak LLMs judging strong LLMs
GDM scalable oversight
I did not actually finish reading this paper, but the idea was that we’re trying to figure out how a dumb human can get an answer from a possibly lying superhuman AI. Except for now, we’re simulating the dumb human (“judge”) with a weak LM, and the superhuman AI with a stronger LM
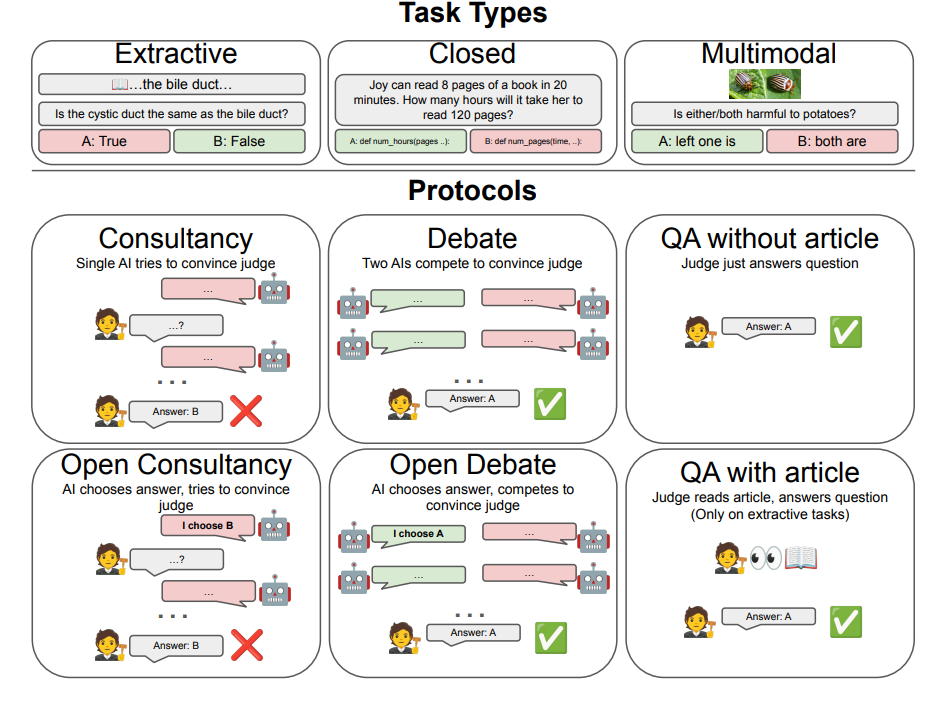
Two types of information asymmetry:
- extractive: the information is in some text somewhere that the LMs have access to but the judge doesn’t
- reasoning: the problem is some hard math/code problem and requires difficult reasoning to solve. Only the strong LMs can figure out the answer
Experiments using just a single AI, or with two AI’s debating different answers. Found that debating helped get to nearly information symmetry in the extractive case, but that debate didn’t really help when the problem was just too hard for the weak judge. GG