FLUX.2: Analyzing and Enhancing the Latent Space of FLUX – Representation Comparison
Flux 2 technical reports
(a little out of order from the blog post itself)
VAEs The latent space in latent diffusion models should be
- Able to reconstruct the output.
- Learnable (semantic)
- Have a decent compression rate.
Which are goals that are mostly in conflict with each other. Flux 1 leaned into reconstruction by including a bottleneck dimension that was 4x that of the original SD AE
So what does Flux 2 do about their autoencoder? They use an 8x bottleneck dimension, but introduce semantic regularization using Vision Foundation (VF) models like DINOv2 (e.g. REPA alignment objective)
- mini experiment: Measuring reconstruction performance
- metrics: reference-based metrics LPIPS (Zhang et al. 2018), Structural Similarity (SSIM) (Wang et al. 2004) and Peak Signal-to-Noise Ratio (PSNR). non-reference based reconstruction FID (rFID)
- results: better than SD VAE (it’d better be with 8x the bottleneck dimension lol), not necessarily better than RAE at reconstruction
Time Step / Noise schedule
Same idea as the scaling up diffusion transformers paper: because we have larger latent dimension (there it was for higher resolution but same idea), we have more redundancy, so you need to train with larger noise to have to learn anything useful
- consider shifted and unshifted versions of different distributions (like logit normal, plateau logit normal)
Main experiment: For different VAEs (SD VAE, RAE, flux 1 VAE, flux 2 VAE) and different choices of the time step schedule, how does the FID of 50k samples vs. training time look? on ImageNet, every 100k training steps, fixed inference budget of 50 sampling steps
- the shift happens at both training time and sampling time, and not necessarily using the same shift
Results:
- adding the REPA semantic regularization helps everywhere
- both logit-normal and plateau logit normal are good and work better than uniform
- the training shift has a large impact on the performance
- the sampling shift (usually should be higher than the training shift) has a smaller impact on the performance
Flux 2 itself
uses “a more compute-efficient global modulation mechanism (Chen et al. 2025)”
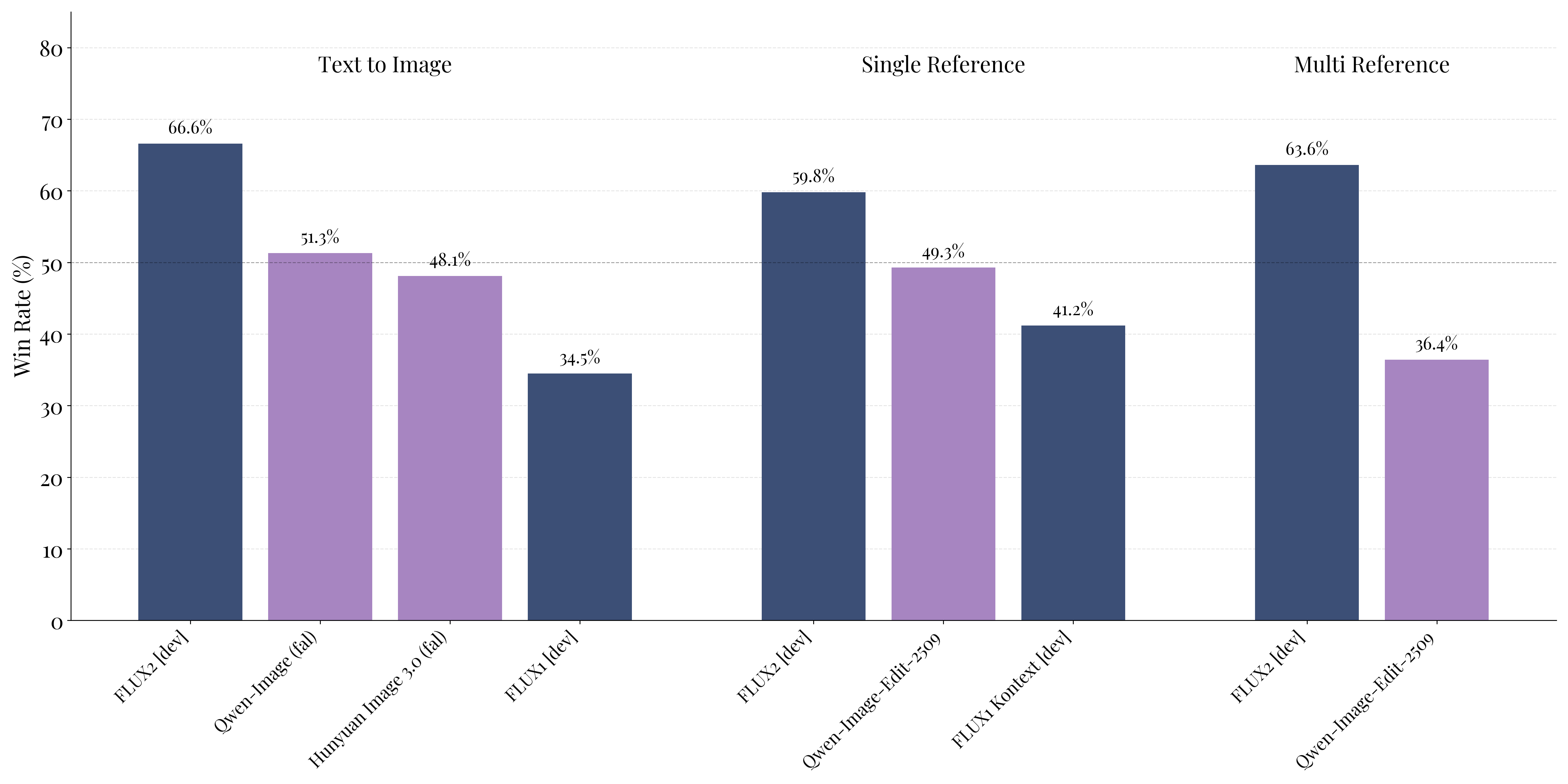 sota at these image generation tasks
sota at these image generation tasks
Text Encoder
- uses Mistral small for everything instead of having two different encoders
- stacks output from intermediate layers instead of just taking one output layer representation, because https://www.arxiv.org/abs/2505.10046 these guys found it to be better