FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Flux.1 Kontext
They try to solve three problems in image editing:
- Attitude images retain style from the original generations, limiting the range of edits you can make
- Details are often not preserved.
- Image editing can be slow.
Mostly everything was the same as Flux.2, in terms of the main pipeline 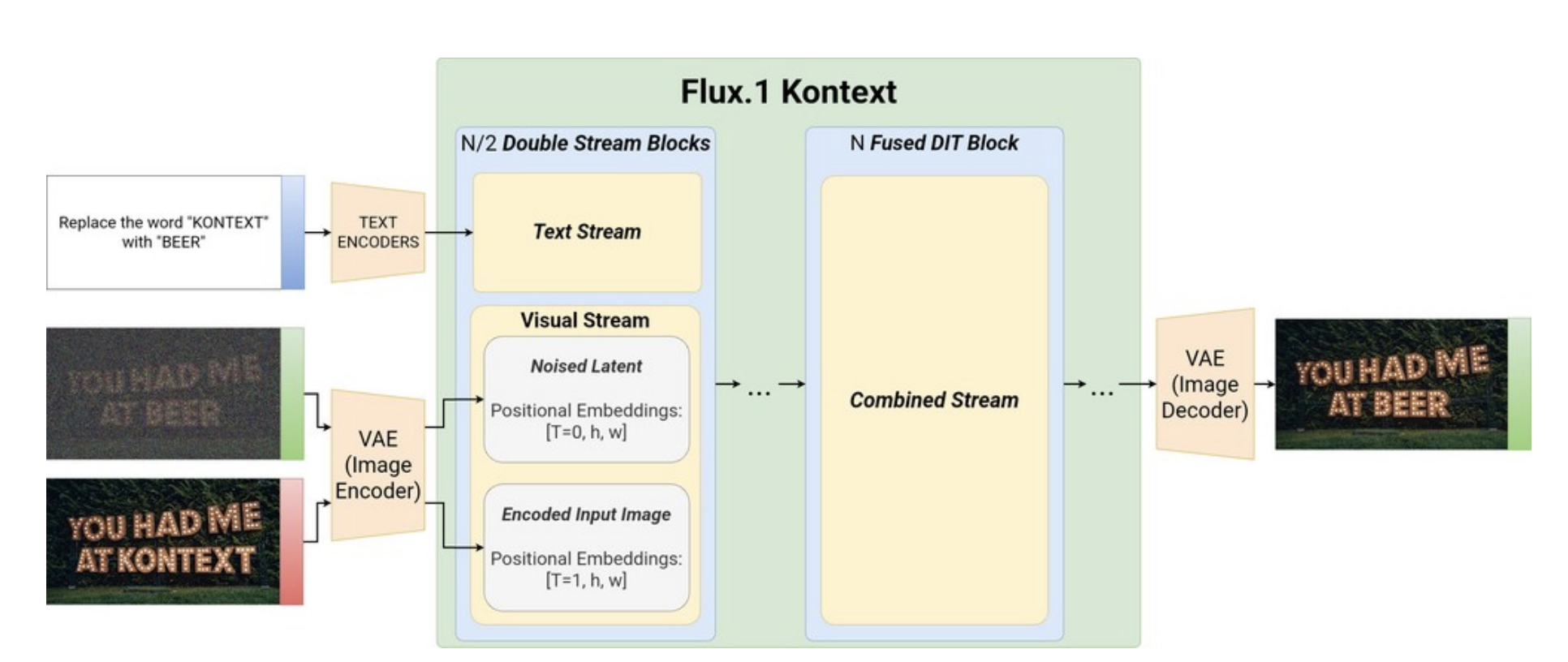
- You just put the reference image through the VAE encoder and concatenate it with the noise latents
They train on a bunch of both text-to-image and text plus reference to image data points. They train Flux1 Kontext [dev] only on image editing tasks to focus performance there.
I don’t think I learned very much from this. Here are the few differences I noticed from Flux 2.
- They use 3D RoPE instead of 4D RoPE
- They use LADD to distill Flux.1 Kontext [Pro] into a small number of time steps (I didn’t look too deeply at this, but it seems that it’s some kind of adversarial training solely in the latent space to match the diffusion output to the target distribution), and then guidance distillation to further distill into Flux 1 Kontext [dev]
- Recall guidance distillation is just approximating the CFG output without having to do two separate runs
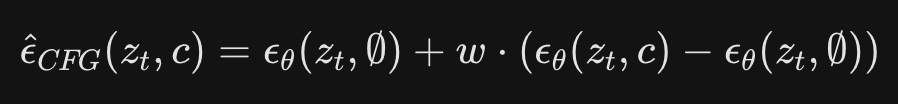
- In contrast, Flux.2 [flex] is not distilled, Flux.2 [dev] is guidance distilled. Flux.2 [Klein] base is its own model and not distilled. Flux.2 [klein] uses step distillation (training to approximate skipping steps in the trajectories of the teacher model directly), where the teacher is already using CFG
Experiments
They release KontextBench an image editing benchmark
Image-to-image:
- image quality, local editing, character reference (using the same characters repeatedly), style reference (transferring style while maintaining semantic control), text editing, efficiency
- human evaluations, for CREF, get facial characteristic measurements from AuraFace
Text-to-image:
- instead of “which image do you prefer” -> prompt following, aesthetic, realism, typography accuracy, inference speed
- prompts from DrawBench, PartiPrompts, real user queries
- They’re pretty good all around, but not the best at any one thing (Figure 9).
And then they emphasize their being able to do image editing iteratively without corruption