Exploring Multimodal Diffusion Transformers for Enhanced Prompt-based Image Editing
activation patching and attention maps in MM-DiTs
Study attention maps within MM-DiT’s, in particular, text-to-image cross-attention. Use activation patching for image features and blending source and target generations at each time step to edit images.
project site: https://github.com/SNU-VGILab/exploring-mmdit
SD3-M, SD3.5-M, SD3.5-L, SD3.5-L-Turbo, and Flux.1-dev/schnell 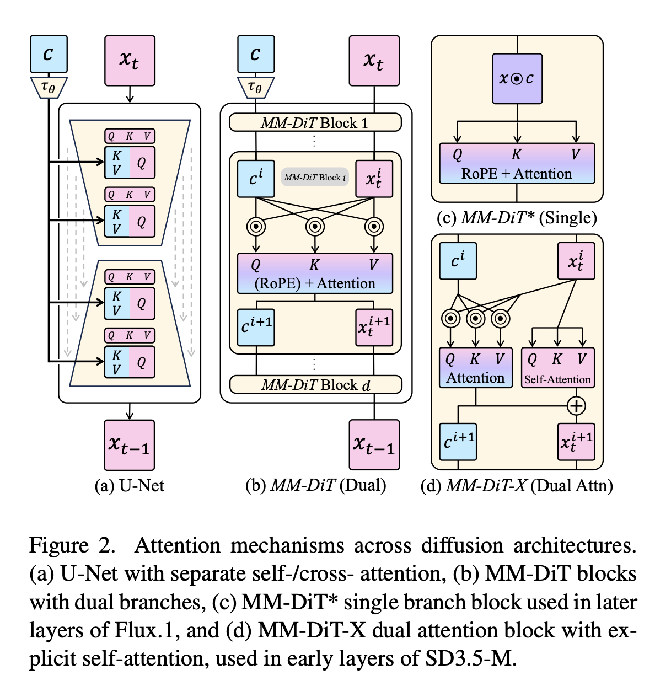 actually a pretty useful diagram for the general attention architectures of UNets, SD 3 family, and Flux.1
actually a pretty useful diagram for the general attention architectures of UNets, SD 3 family, and Flux.1
 T2I (text keys, image queries) is more useful than I2T (text queries, image keys) Because attention summing to one does not limit how many pixels can pay attention to a given text token like “cat” in T2I
T2I (text keys, image queries) is more useful than I2T (text queries, image keys) Because attention summing to one does not limit how many pixels can pay attention to a given text token like “cat” in T2I
3.3 Mitigating noisy attention maps
They find that as you scale up DiTs, the attention maps get noisier. They have two methods of getting around this:
- Only averaging using 5 of the attention layers
- Gaussian smoothing on the attention maps
- Validated using image segmentation on the PARTI prompts
Image Editing Experiments
Two major methods used in conjunction to do image editing given a source generation and a target generation 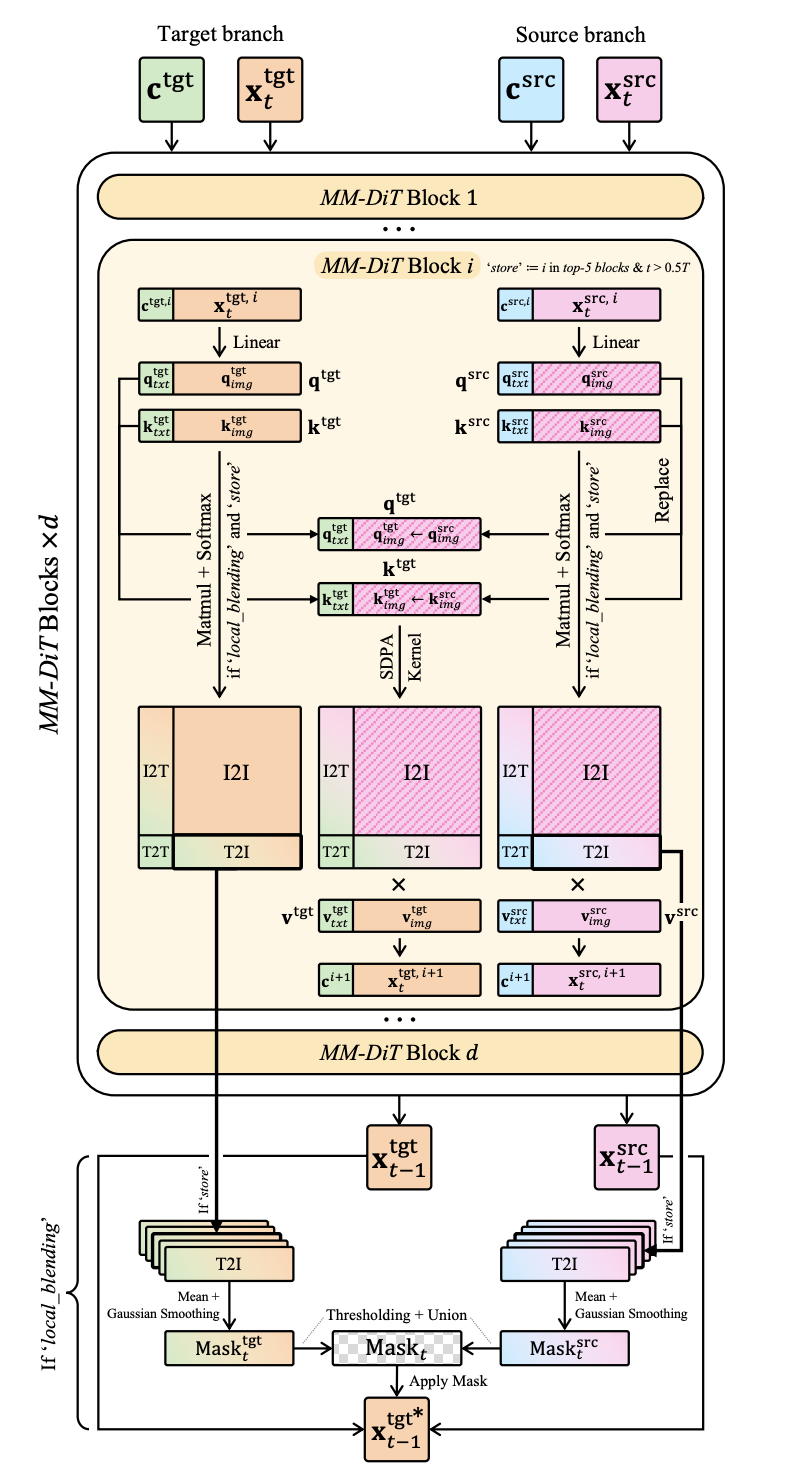
- activation injection (applied to every block*): They find that replacing both the image and text attention inputs q and k causes misalignment with the text. For the target generation, they only replace q_i and k_i (the image features)
- If you try to replace the attention values themselves, you lose out on some optimized performance SDPA kernels
- Allows you to do image editing when the target and source prompts are very different.
- *For Flux and other short-time step models, they don’t apply to every layer since they find that that forces it to stay too close to the source.
- local blending (applied only once per timestep): use the top 5 attention layers’ generated T2I attention map average and union them to get a mask about where the edited concept lies. Then use the source output for everything except that mask and the target output (which already uses q_i and k_i from the source) for everything in that mask.
- They only do the Q and K replacements for early steps, so that it properly does the finer details later.
- They also only do local blending for earlier steps (with a different parameter)
Editing real images: their approach is compatible with the standard method of reverse engineering the latent for the real image and then using the edited prompt to generate from that latent
- Find that the reverse engineering technique is the most impactful choice here