Scalable Diffusion Models with Transformers
Diffusion Transformers
Preliminaries: the VAE ELBO loss approach to diffusion, classifier-free guidance , latent diffusion models (used to save flops)
use off-the-shelf convolutional VAEs for latent diffusion, and transformer-based DDPMs for their actual network
Section 3 the architecture
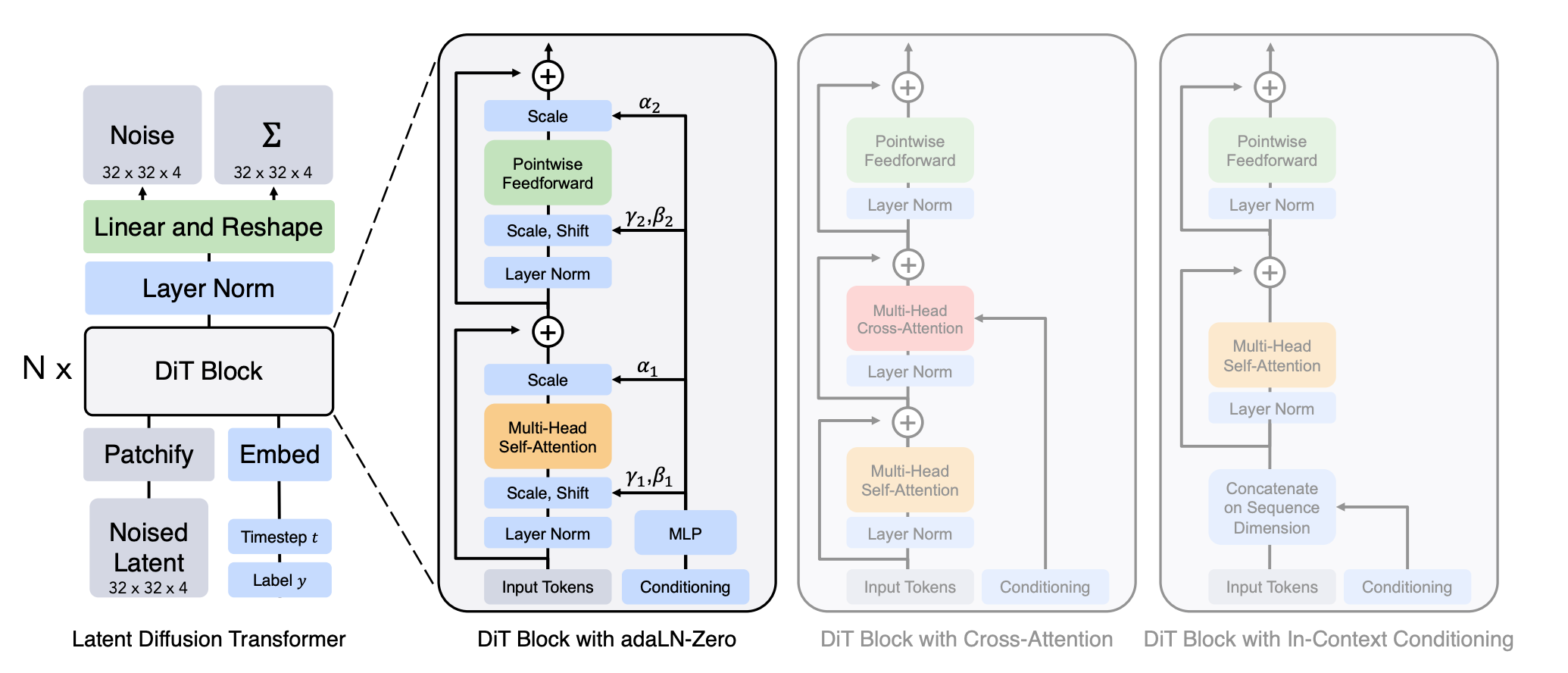
the outputs of the transformer are the predicted noise, and a covariance matrix
- Usually, diffusion assumes fixed covariance, but they actually learn it here for some reason.
Choices:
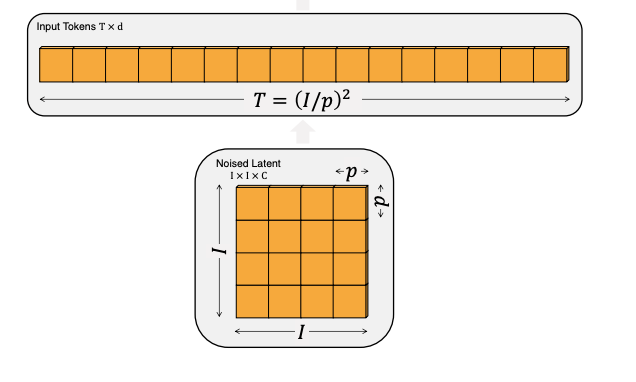
- the patch size (for turning an image into tokens), how big of a patch (full depth) do you embed into one d dimensional token?
- how to incorporate the timestep t and the class conditional labels y into the diffusion architecture? Tried the three (four) methods in the figure. -Zero means including the alpha parameters, which are initialized to zero so that it starts off just learning a residual
- use four model sizes following ViT
Section 4 Experiments
- class conditional image generation of multiple sizes
- metric: FID
- Inception Score [51], sFID [34] and Precision/Recall [32] as secondary metrics.
- Used a lot of hyperparams from ADM without tuning
- used off the shelf VAE from stable diffusion
Section 5 Experiments
- adaLN-Zero best
- scaling model Gflops, not model size, improves performance (decreasing patch size improves performance too)
- → DiT-XL/2 is their best model
- beats all previous sota besides gans on 512x512
- scaling up inference compute doesn’t really do much compared to scaling up training compute