ConceptAttention: Diffusion Transformers Learn Highly Interpretable Features
ConceptAttention
Goal: come up with good saliency maps localizing text concepts in produced images, without having to train any models
Related works: there is apparently a decent amount of past work doing diffusion interpretability, though DiT interpretation was underexplored at their time of writing. Should look into the interpretation of like the physics people though looking into the manifold stuff
Then motivating why zero-shot image segmentation is historically a good test for these saliency map esque interpretation techniques
Preliminaries: Basically they just use the MM-DiT architecture, and note that there are dual stream (residuals for image and text embeddings are separate) and single stream blocks (combined residuals) within flux
ConceptAttention Method: 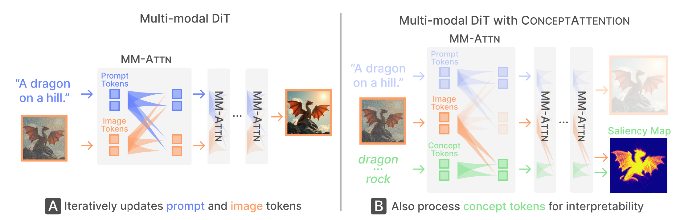
- Key idea: Add on concept tokens to the attention layers such that they only act as queries. Reuse all the weights from the attention processing of the text tokens. So they can pay attention to the image tokens (turns out they actually don’t pay attention to the prompt tokens, The figure is a little misleading in that way), but not the other way around.
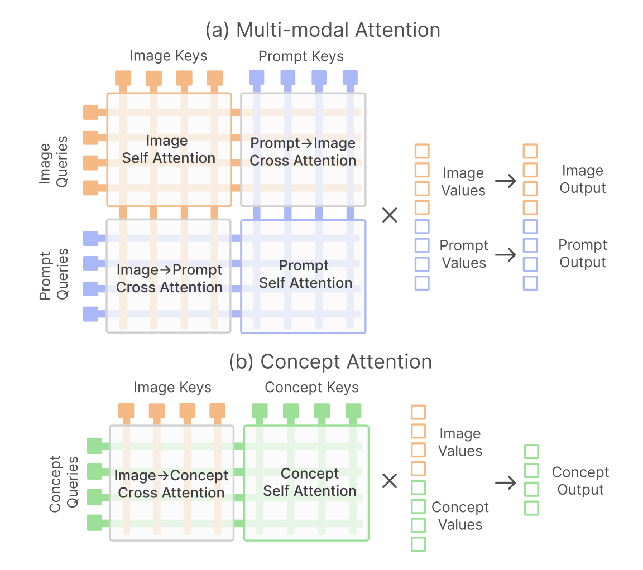
- Another view on this. Top is the unaltered multi-modal attention. Bottom: Cross-attention would be only concept queries paying attention to image keys. They find that including concept keys actually improves the saliency map.
- Unlike normal cross-attention, they are also not limited to the vocabulary of the prompt.
- For each of the concept tokens, The initial embedding is obtained via T5, and then you get the keys, values, and queries for the concept using the projection weights learned for the prompt.
- For future layers, keep a residual stream of the concept embeddings, which are updated the same way as the text embeddings residuals: Projection adaptive layer norm modulation and MLP
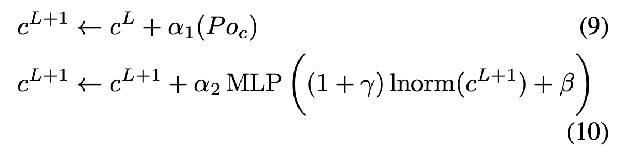
Get saliency maps by just taking a dot product between the concept outputs and the image outputs. 
Experiments Used Flux.1 schnell, As well as SD3.5 Turbo. and even CogVideo X (video generation model) Averaged saliency maps over last 10 of 18 layers; Averaged over frames as well for COG Video X.
Zero-shot Image Segmentation
- ImageNet-Segmentation (one main object) and PascalVOC 2012 (multi-class)
- limited to single token text descriptions for their vocabulary, so they have to simplify some of the ImageNet descriptions of classes
- “standard segmentation evaluation metrics, namely: mean Intersection over Union (mIoU), patch/pixelwise accuracy (Acc), and mean Average Precision (mAP)”
ablations
- Deeper layers have richer representations.
- The middle time step (in diffusion denoising) is the most useful.
- Concept attention adds more than just cross-validation attention.
- Maybe I missed this in the paper, but why did they do the weird output dot product as opposed to using the attention scores directly? Would have liked an ablation for that.