Circuit Mechanisms for Spatial Relation Generation in Diffusion Transformers
Circuits in DiTs
They train DITs from scratch to generate spatial relations between objects and individual object attributes. They find that when they use T5 as the text encoder, the circuit for this task uses fused information about the spatial relation and object attributes from just one tax token, while when they use random text embeddings, two separate cross-attention heads do these two different roles.
Dataset: Two objects with some spatial relation and individual properties
- ex. “Blue triangle is to the upper left of red square.”
models: DiT architecture, different model sizes, VAE from Stable Diffusion, T5 and random text encoders with and without positional encodings
- Idea for random embeddings is to see if the DiT can learn object relations without contextual structure in the text embeddings
- Random embeddings without positional encoding predictably does poorly because “red A on top of blue B” and “blue B on top of red A” are equivalent
sampling / evaluation: 14 steps, classifier free guidance, use standard object segmentation and classification to see if the image was generated correctly.
Figure 2: training dynamics. During training, the model first learns single object attributes, then spatial relations. 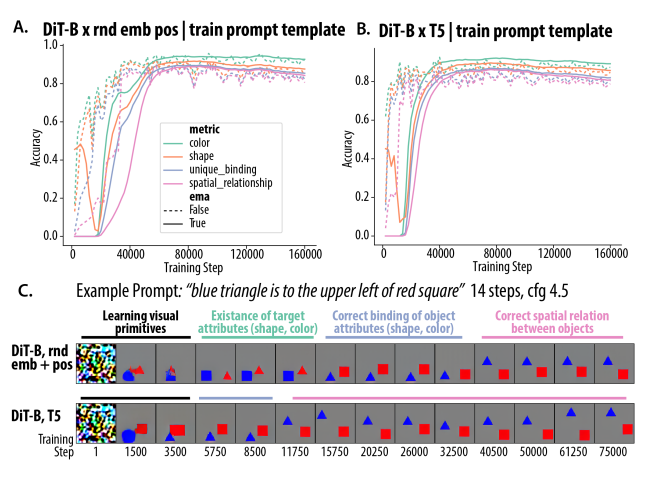
Figure 3: “attention synopsis”. First, aggregate (mean sum) attention across the tokens in a given category . Then average across time steps. 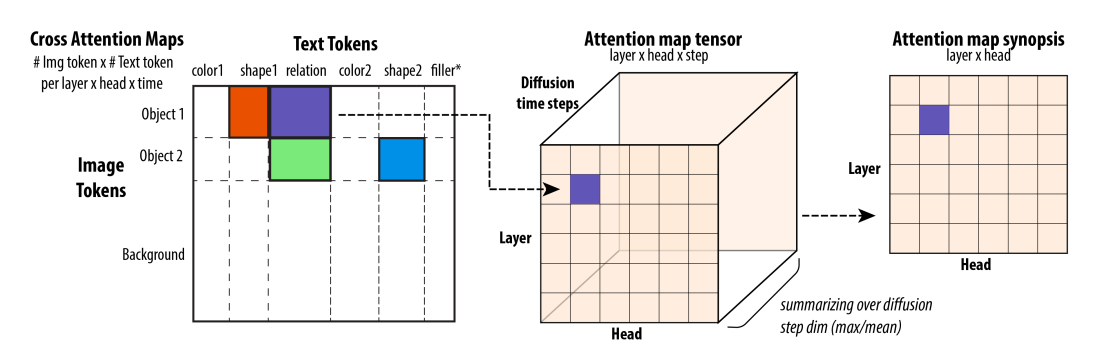
Section 4. The circuit for random text embeddings
Figure 4: The cross-attention head for image to spatial relation text (“spatial relation head”) 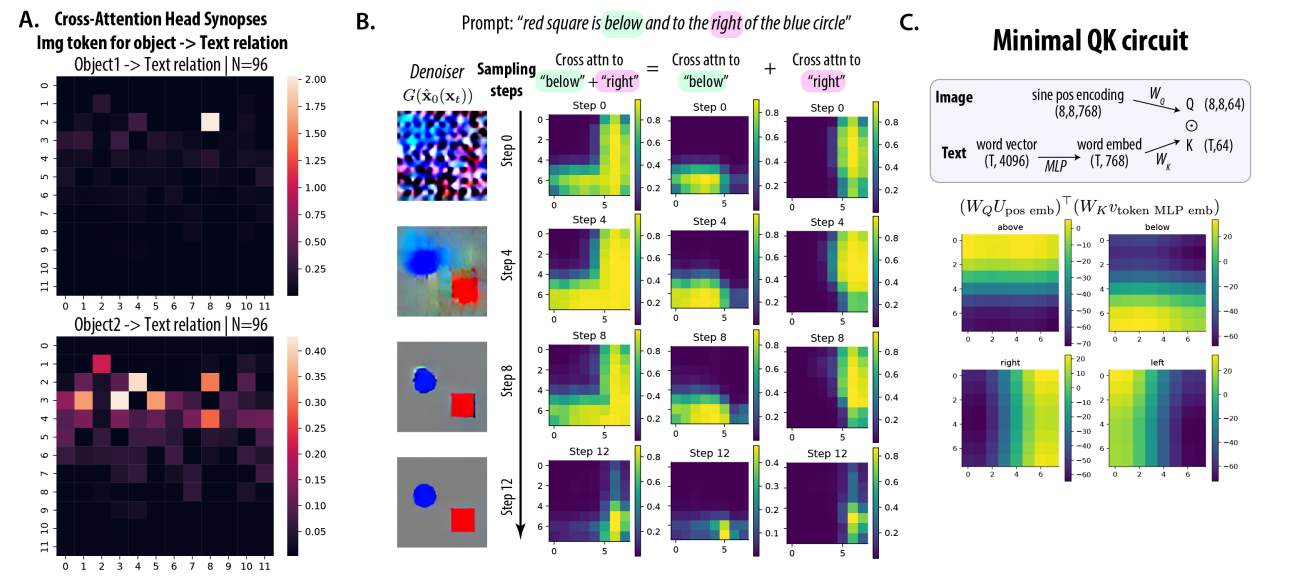
- Figure 4a: Looking at the attention synopsis for each object in the image, paying attention to the spatial relation words in the text. For object one, there is very clearly one attention head doing the work.
- Figure 4b: For this one attention head, they look closer at its attention maps for each time step (How much attention is each pixel paying to the specific textual token). They find that even at time step zero, the pixels that pay most attention to the spatial relation words respect the spatial relation, which indicates that it’s capturing information from the positional encoding, because the image pixel encoding itself is just noise at this point.
- Figure 4c: To validate that this head is literally just capturing spatial relation using positional encoding, they take the dot product between a query weight matrix-projected positional encoding (which is fixed beforehand and doesn’t require a model generation) and a key weight matrix-projected text encoding of the word “above” or “below,” and find that it produces the same visual gradients as the attention map from 4B.
Figure 5: The cross-attention head for object in image to textual attributes (“object generation head”) 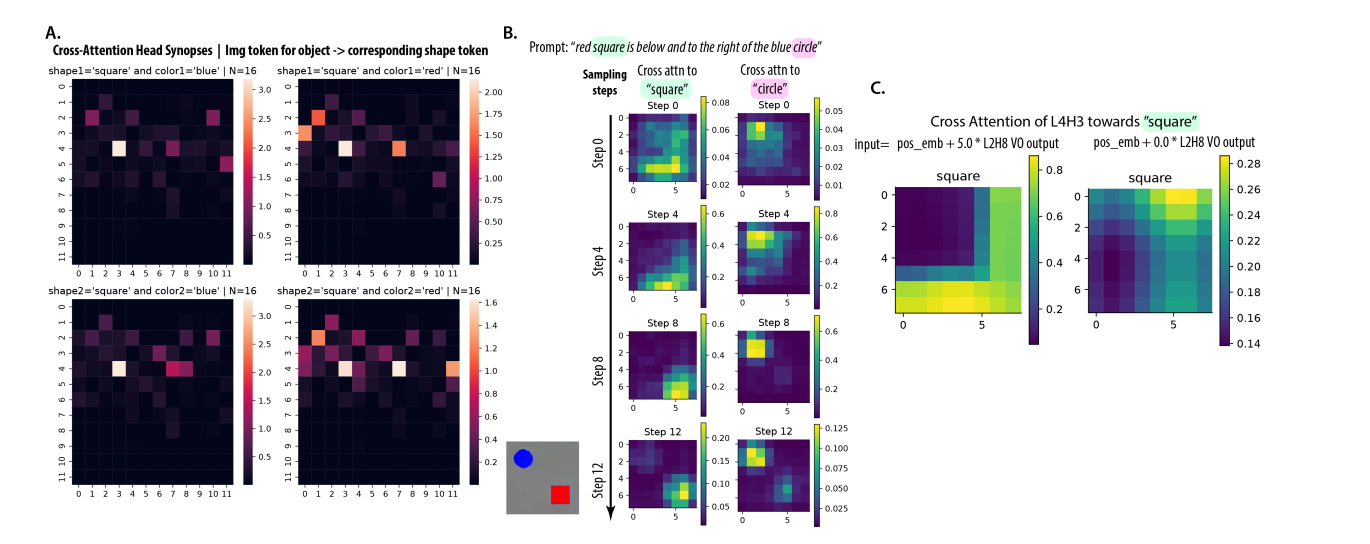
- 5a: head at L4H3 is consistently active regardless of the object or the attribute
- 5b: As time steps go on, the attention to a given textual attribute sharpens to the correct object
- 5c: They inject the output of the L2H8 head into the positional embeddings before the L4H3 head applies attention, and show that it drastically changes what the L4H3 head pays attention to, implying that these two heads are composing together
Figure 6’s head ablation confirms the roles of the attention heads 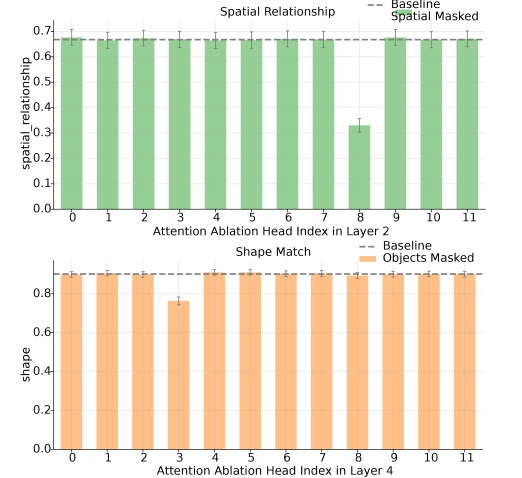
Figure 7: A summary of the conjectured circuit. 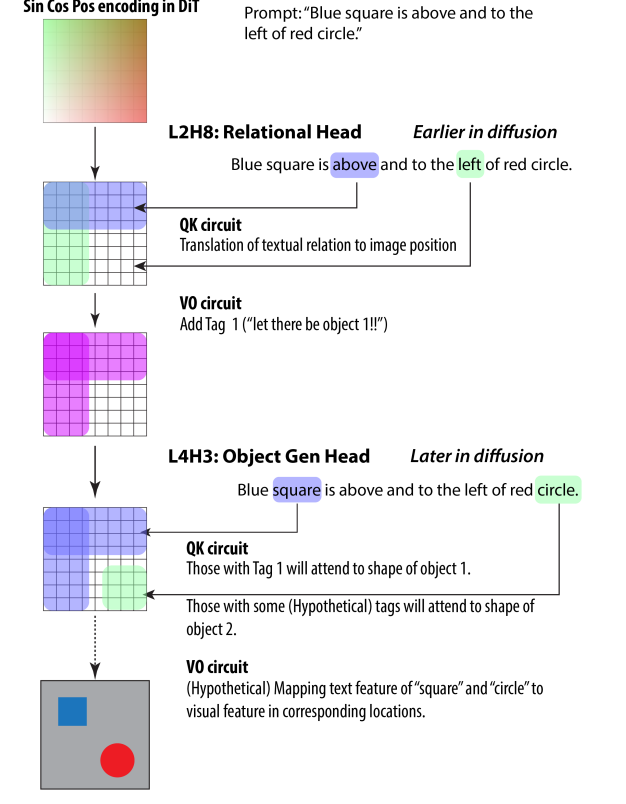
One potential issue with applying this to my work: unlike in their text prompts, if I’m not explicitly mentioning lighting, it’s unclear what I should measure attention paid to.
Section 5. The circuit when using T5 for the text encoder
They don’t find a similar least salient attention head for this version. They suspect that this is because the shape tokens already contain information about the spatial relation for T5 embeddings.
Figure 8: Some evidence for this through ablations and vector arithmetic 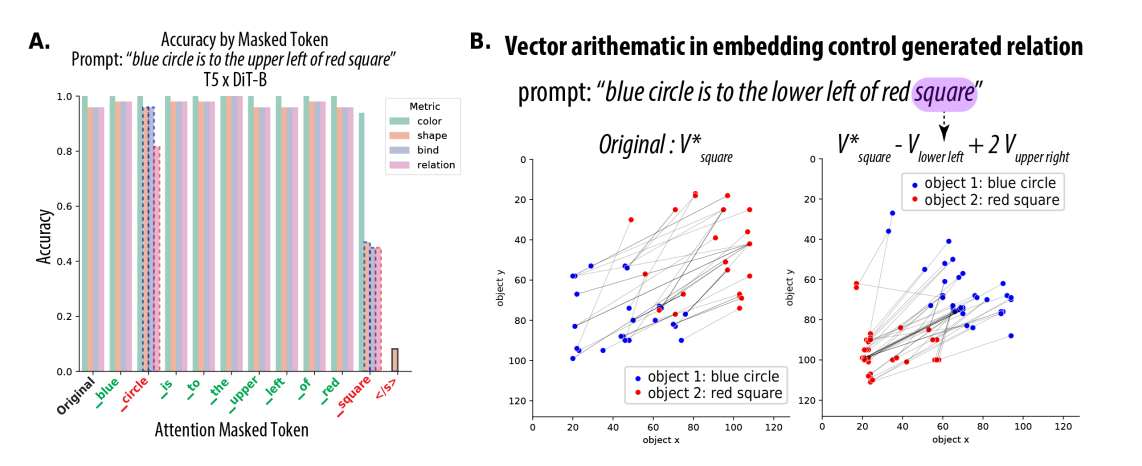
- 8a: When they ablate the spatial relation words from the T5 embeddings, there is suspiciously little impact on the accuracy. There is more impact when they ablate the shape words.
- First, they do their variance partition analysis, which is basically a multi-variable linear regression from the one-hot of the shape, color, spatial relation, etc to the actual shape2 token embedding, seeing which vector has the highest R^2

- 8b: Confirms that these vectors are causal: by taking the shape2 embedding and then subtracting the vector for lower left and adding 2 * the vector for upper right, they actually managed to swap the positions of the two objects in the image (object x and object y on the graphs are the coordinates of the objects)
bonus finding: When they vary the prompt format, even by a little bit, for the T5-based model, it causes a big drop in accuracy, unlike the random text encoding model.