Attention Residuals
attention residuals
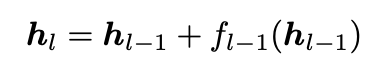
- Standard residual connection only uses the output from the previous layer
- As layers go on, this means that later layers can have less and less effect on the residual stream, since it grows as O(L), and the gradients accumulate and are largest at layer zero.
- It’s sort of the RNN problem of trying to compress each layer’s information into only a single hidden vector.
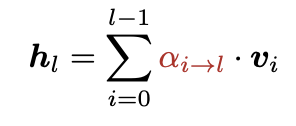
- So instead, do softmax attention over the previous layers’ outputs
The attention and weights are determined as follows: 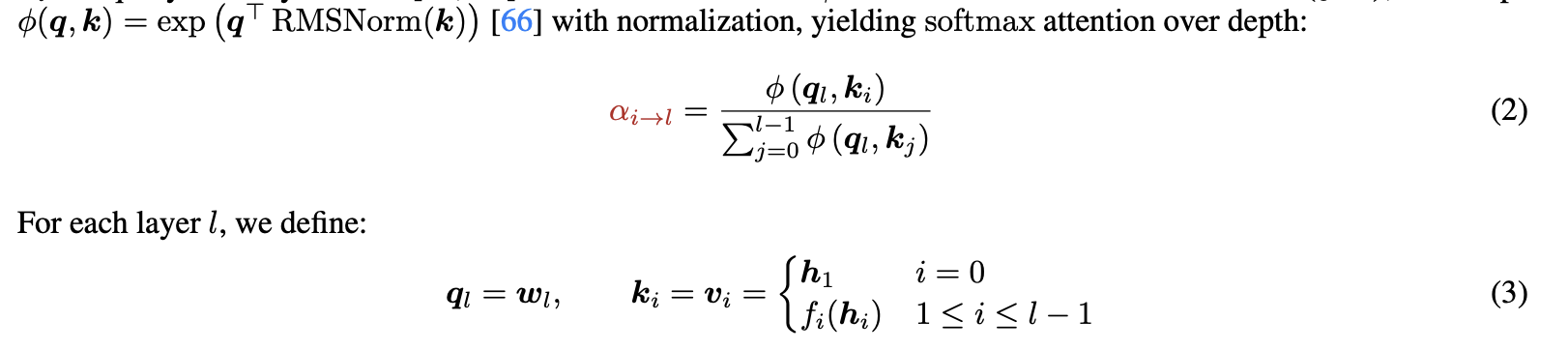
- The RMS norm is to make it so that layer outputs that have large magnitudes don’t dominate the attention.
- The pseudo query labels are learnable weights.
Blocked version: full layer version is best but uses O(Ld) memory, and communication costs get too high. Block layers together into N blocks, N < L, using O(Nd) memory 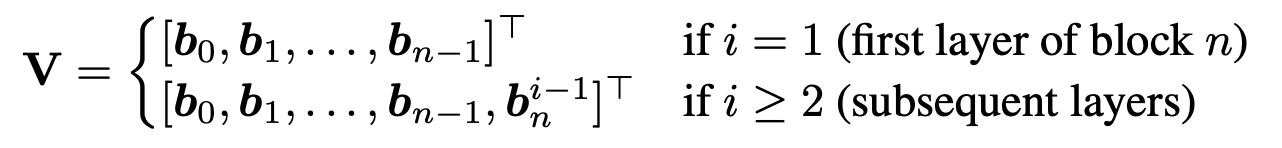
- Each layer can pay attention to the output of the previous blocks, as well as the prefix sum of the current block’s layers.
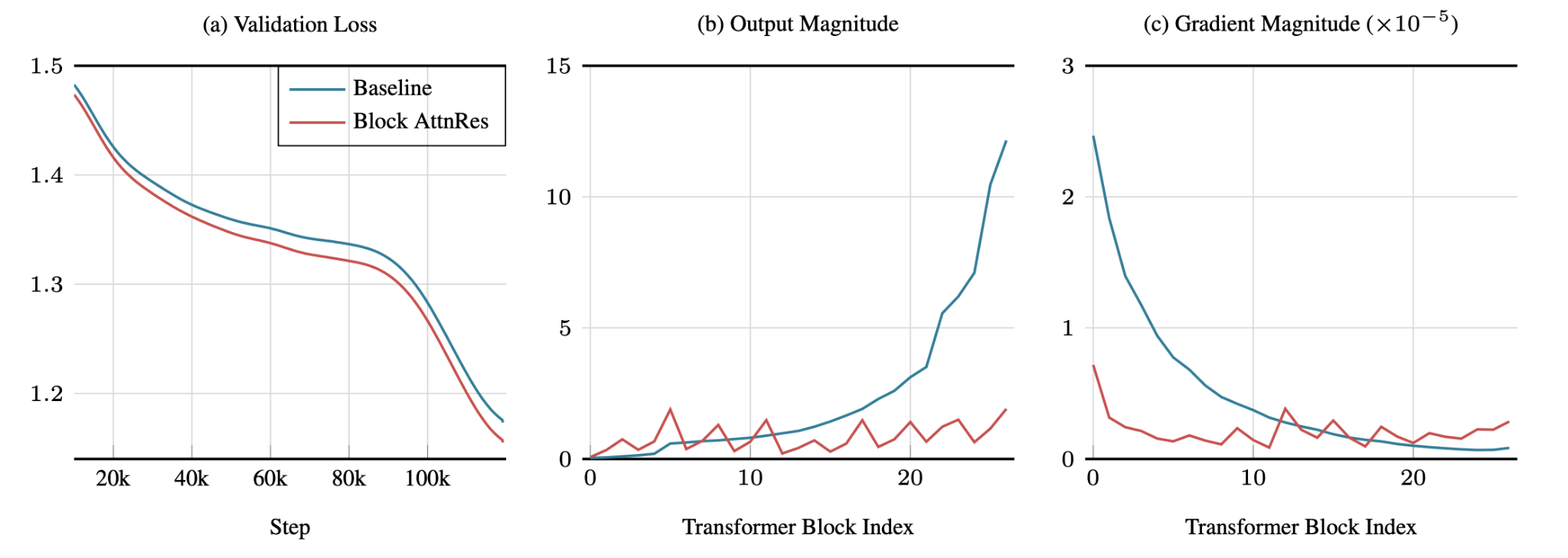
- Figure 5: Solves the layer output magnitude problem in the gradient problem I mentioned earlier and gets better validation loss than using the normal residual connections.
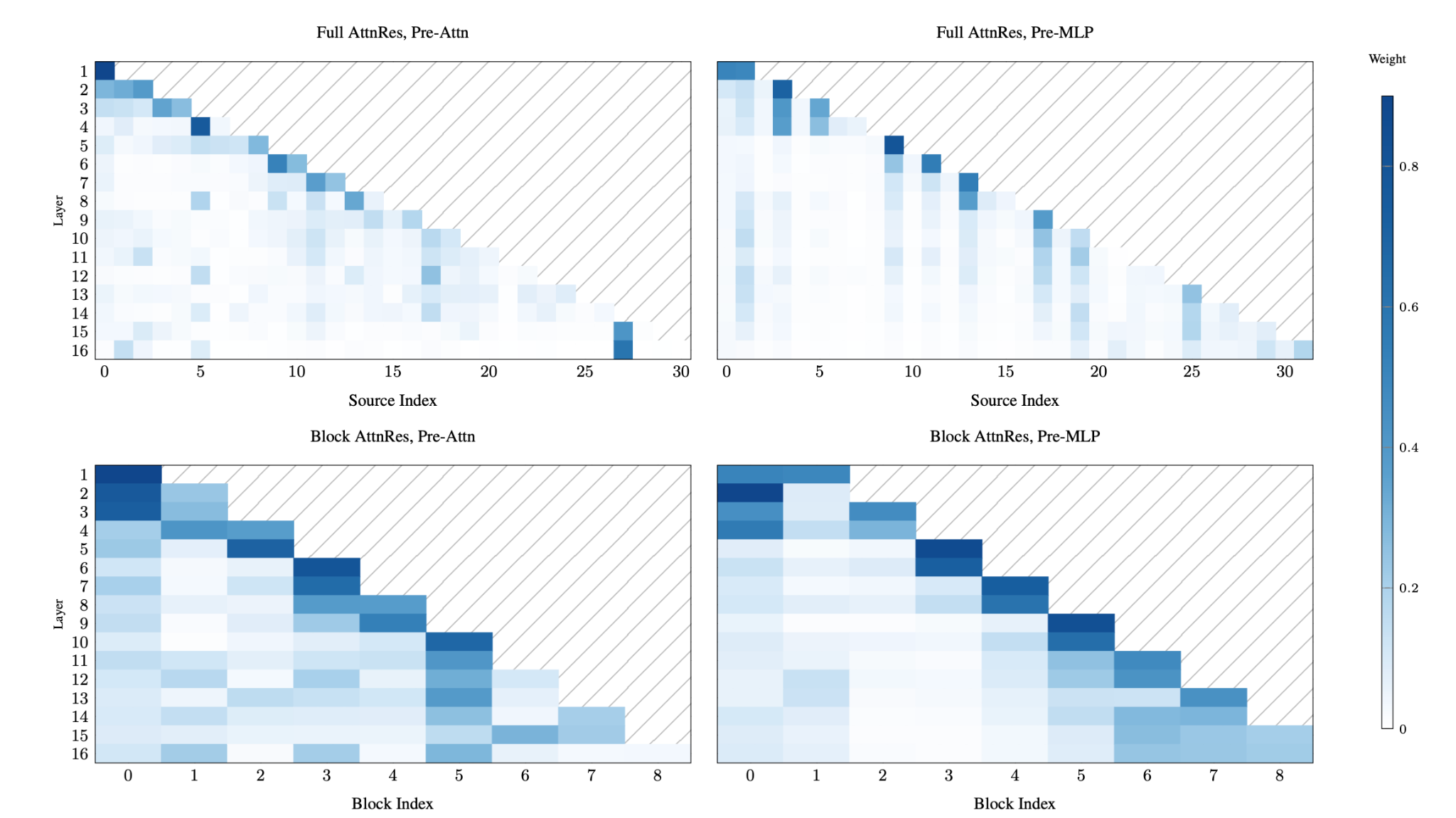
- Figure 8: Most of the layer attention is still paid to the current layer and to the original embedding layer, But there are some pretty strong skip connections.