Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics
arithmetic heuristics
Arithmetic without algorithms
Shows that LLMs do arithmetic by having a sparse set of neurons encode heuristics, not doing any algorithmic computation or memorizing, by finding and analyzing the arithmetic circuit.
Figure 1: shows some of these neurons in the MLPs (which are in middle to late layers) and what heuristics they capture. These neuron activations then impact the final output logit and make it more likely. 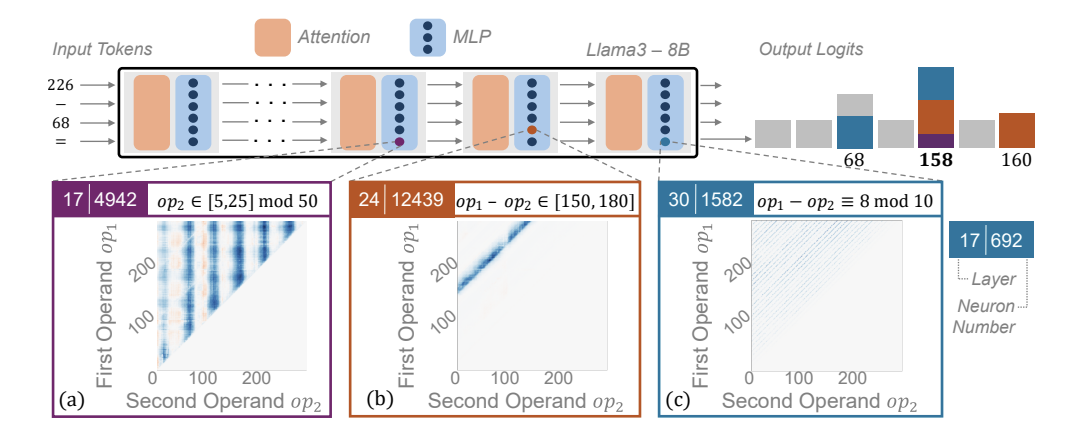
Prompts are literally 4 tokens, like “226 - 68 =”
Identifying and evaluating the arithmetic circuit.
Unlike the Nikhil fine-tuning paper, they don’t try to find the edges in the circuit (not path patching, only activation patching). They’re just trying to find the heads and MLPs that are responsible for arithmetic and at what token positions they act (layer is already included in the definition of the head / MLP)s.
They take two prompts, p and p’, and then for each component (head or MLP layer — During circuit discovery, they patch the entire output of the MLP, not just the intermediate activations.) that they’re evaluating, they patch over just the outputs from p’ to the generation with p. Then they see how this affects the E(r, r’) score from equation (1) 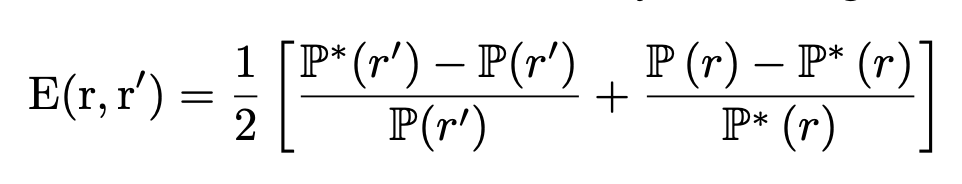 , essentially looking at how much the patching raises the probability of the answer for p’ while decreasing the answer for p.
, essentially looking at how much the patching raises the probability of the answer for p’ while decreasing the answer for p.
They evaluate the circuit that they find using faithfulness
- slightly different from the nikhil paper: equation (2)
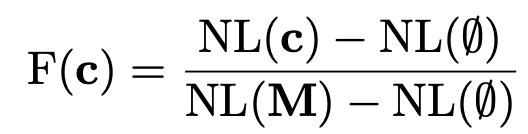 . They basically take the logit for the correct answer with everything but the circuit mean-ablated, normalize it by subtracting a baseline and dividing by the oracle - baseline
. They basically take the logit for the correct answer with everything but the circuit mean-ablated, normalize it by subtracting a baseline and dividing by the oracle - baseline - get faithfulness of 0.96, pretty good
Figure 2: What is the circuit that they found? 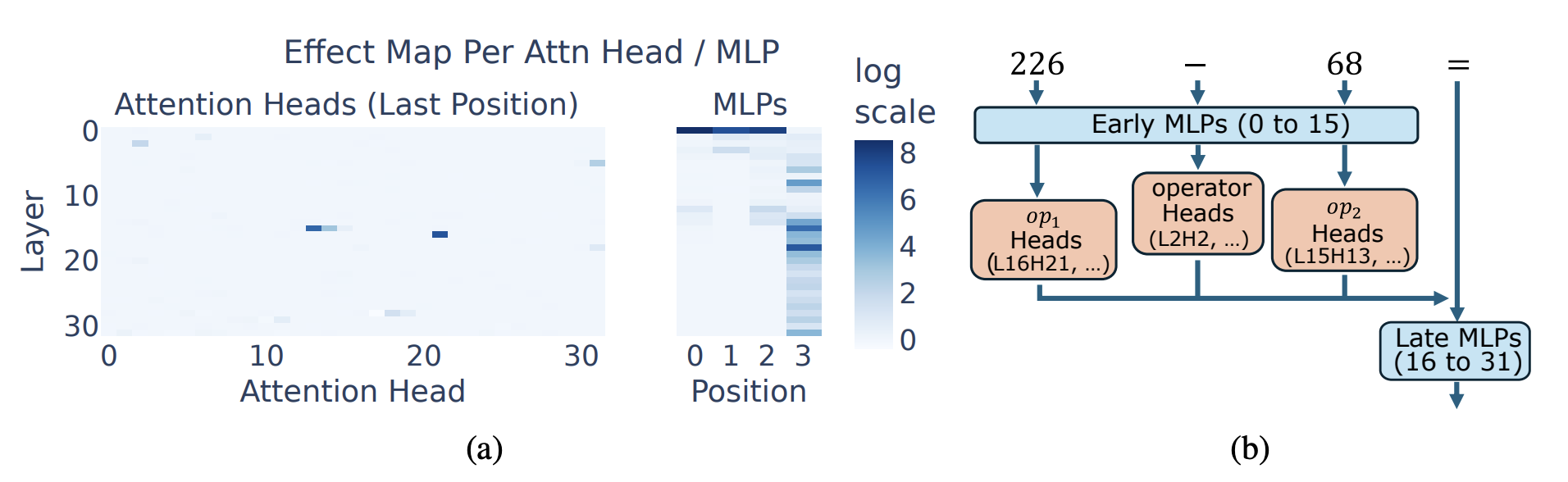
- early MLPs do a lot of work, on each of the input tokens besides the last one
- then a few attention heads move this information from the other tokens to the last token. (“projecting” just means that the attention head in the last token pays attention to these earlier tokens)
- the middle to late MLPs then do a lot of work for the last token specifically
Figure 3: Where in the circuit is the answer determined? 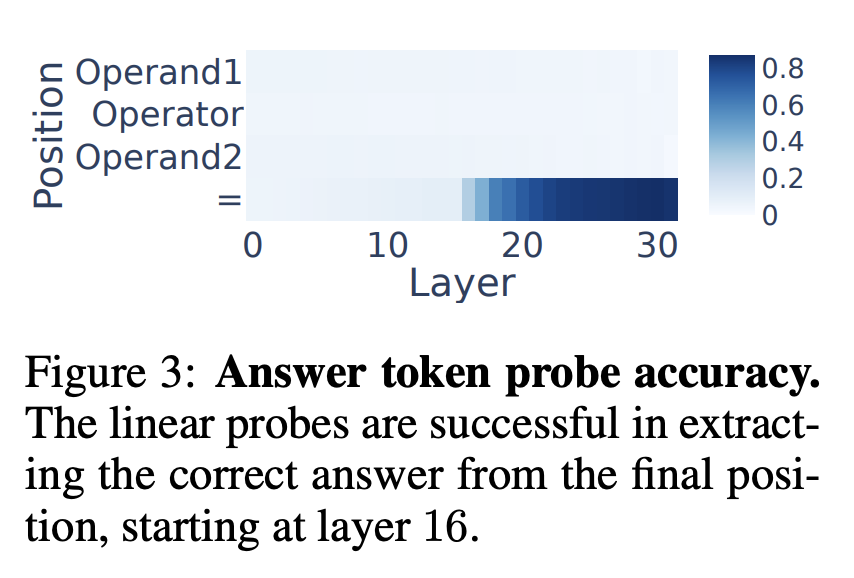
- They train a linear probe (i.e. a separate multiclass linear classifier) using activations for each layer and each token position, and find that only the linear probes on later MLP layers of the last token can successfully predict the correct answer
- This is more evidence that the MLPs in these later layers in the last token are responsible for generating the right answer
Claim: individual neurons are responsible for arithmetic heuristics
Neuron = individual activation after the up-projection of an MLP
Figure 4: they patched individual neurons for each layer. 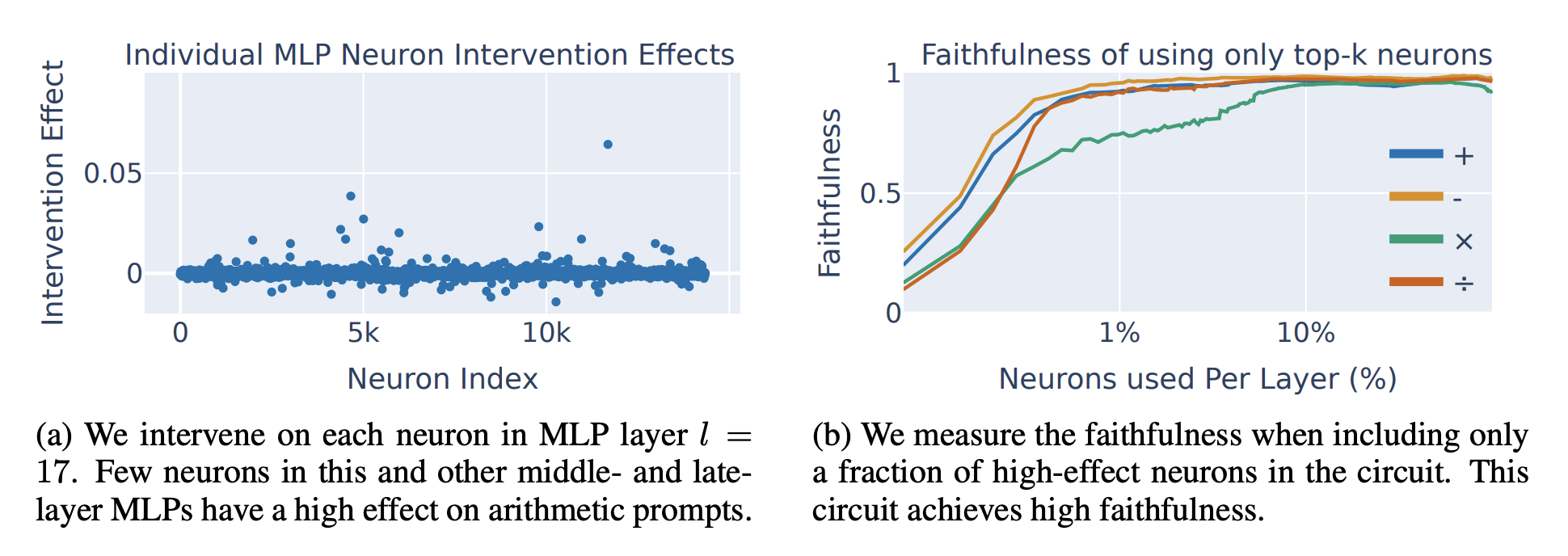
- 4a shows that a few neurons per middle late MLP layers in the circuit are impactful, and they differ based on the arithmetic operation.
- 4b shows that if you mean-ablate 98.5% of neurons in the mid-late MLP layers in the circuit, you still get a faithful circuit, so it’s really these neurons that matter.
- they end up just using the top 200 neurons per layer for stuff later
Digression: according to Geva et al 2021, you can view MLP’s as key-value memories, where the row vectors of the MLP_in are the keys, which when matched, activate a given neuron. And when that neuron is activated, the row vectors of the MLP_out are the values that it adds.
- the “keys” here are numerical patterns in the input
- in Figure 1, can very clearly see numerical patterns in the inputs for when some of the neurons are highly activated
- the “values” are more subtle: they used logitlens (which literally just takes the value and multiplies it by the final output projection matrix to see what the contribution to the final logits would have been), and concluded that either the values directly encode the expected operation result, or are combined with other heuristics
Section 4.1 Interpreting the heuristics for individual neurons
Process is mostly Figure 6. 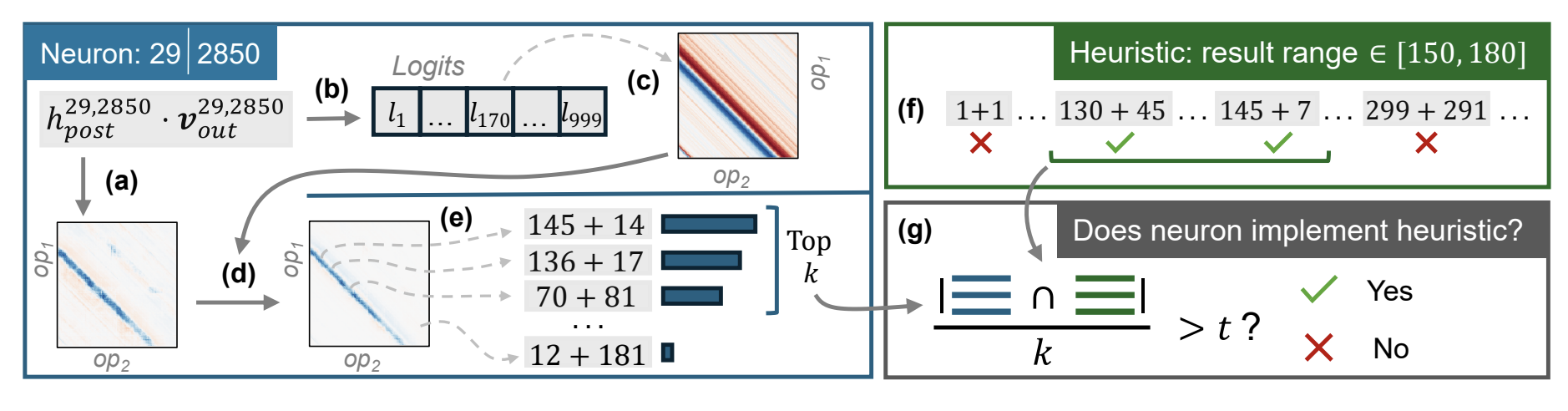
- They have a set of pre-defined heuristics, and they put together a bunch of inputs that correspond to each heuristic. Then for every prompt in the dataset, they see how highly the neuron activates, multiplied by the MLP “value”’s logit for the right answer (using logitlens), and then compare the prompts that effectively activated the neuron the most to the heuristic’s list. If intersection >= 0.6, then neuron implements heuristic.
- Surprisingly, this successfully classifies 91% of the 16 layers * 200 neurons/layer.
Section 4.2 Ablating neurons to show causality of the heuristics
Figure 7: picking a heuristic, ablating all neurons for that heuristic, and look at accuracy for 100 prompts with the heuristic vs accuracy of 100 prompts without 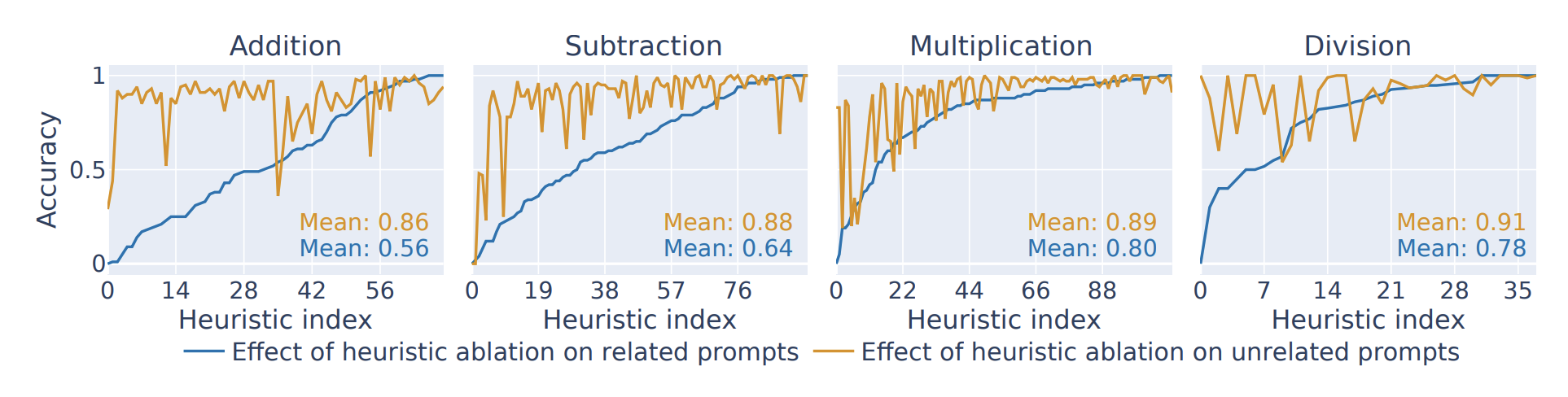
- the x-axis is ordered by how much ablating that heuristic dropped accuracy
- I don’t like this very much, since the neurons for the heuristic were chosen in the first place to be highly activating for prompts with that heuristic.
- they note that accuracy doesn’t drop to 0 because it’s only ablating one heuristic at a time, and they suspect a bag of heuristics to come into play
Figure 8: for each prompt, ablate the top k neurons for any heuristic associated with it. This does much better (since covering different heuristics), which at least supports the idea that the neurons are encoding different things. Compared to ablating a random k neurons ofc. 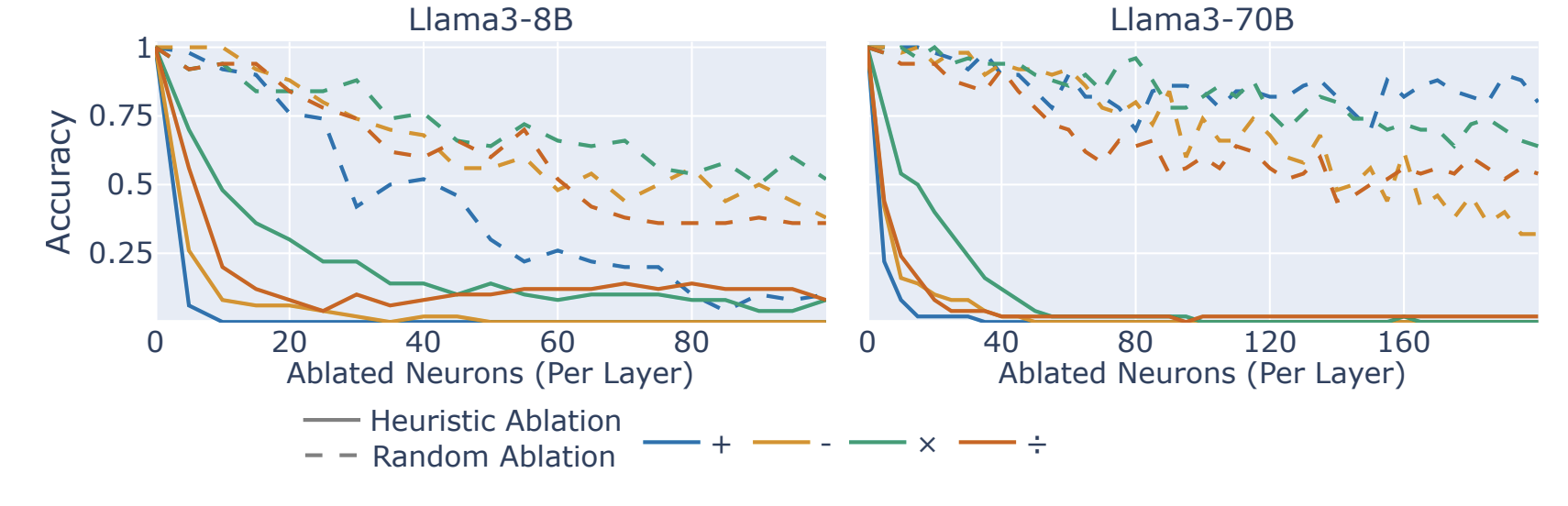
Figure 9 kinda sus, failing prompts have less effective activation by heuristic neurons. Implies that failing because not activating the right neurons, not because don’t have them in the first place. 
Training dynamics
Figure 10: Does this heuristic mechanism hold up during training? use a model (pythia) that has open checkpoints (I recall the best one nowadays is probably olmo 3) 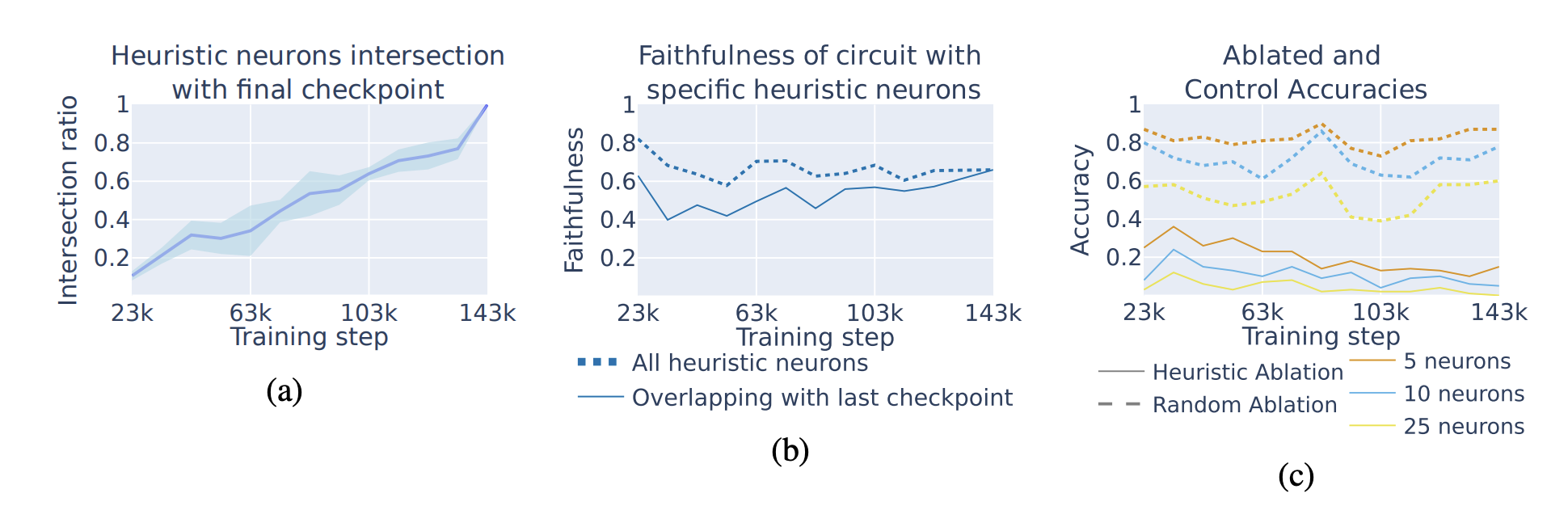
- 10a: the fraction of neurons who share a heuristic with the final trained model increases through training time (the model learns the heuristic neurons gradually)
- 10b: the neurons still explain most of the circuit’s behavior in earlier models, via faithfulness. There’s little sign of other mechanisms existing earlier.
- 10c: repeat the experiment where they knock out the heuristic neurons for a given prompt, works at any training step, further evidence that earlier training steps also used heuristics.