Generative Modeling by Estimating Gradients of the Data Distribution
score function generative modeling
I’ll refer to the ICLR Diffusion explained blogpost for the motivations of score based modeling
The idea is that the objective we want to solve is to minimize the fischer divergence 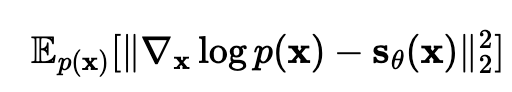 but we have ways of minimizing this without access to the true score values
but we have ways of minimizing this without access to the true score values
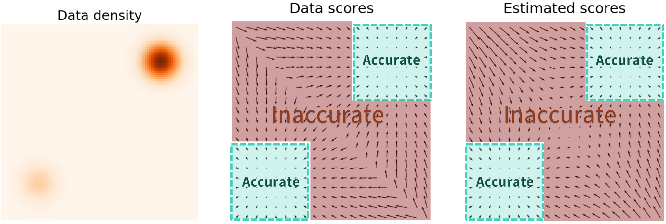 The problem is that the learned score function might be inaccurate in regions of low density
The problem is that the learned score function might be inaccurate in regions of low density
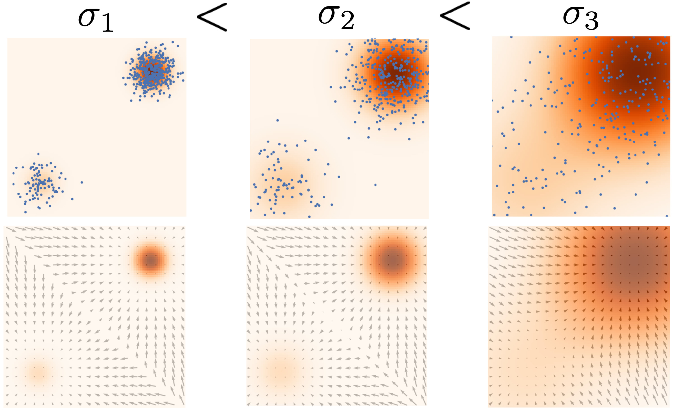
→ this motivates perturbing the data with noise, and training score based models on the noised data instead, which has less low density regions
- this trades off corrupting the data with getting a better score estimate
Idea: use many different noise amounts, and train a noise conditional score-based model to predict all of them 
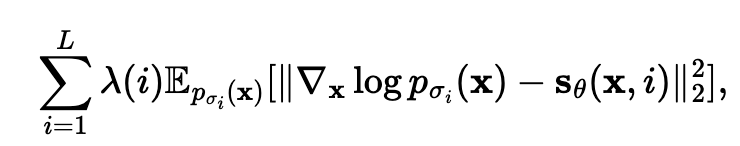 minimize the weighted sum of the Fisher divergences for the different noise scales
minimize the weighted sum of the Fisher divergences for the different noise scales
then to actually sample, use annealed Langevin dynamics: basically do the reverse langevin diffusion using decreasing noise scales
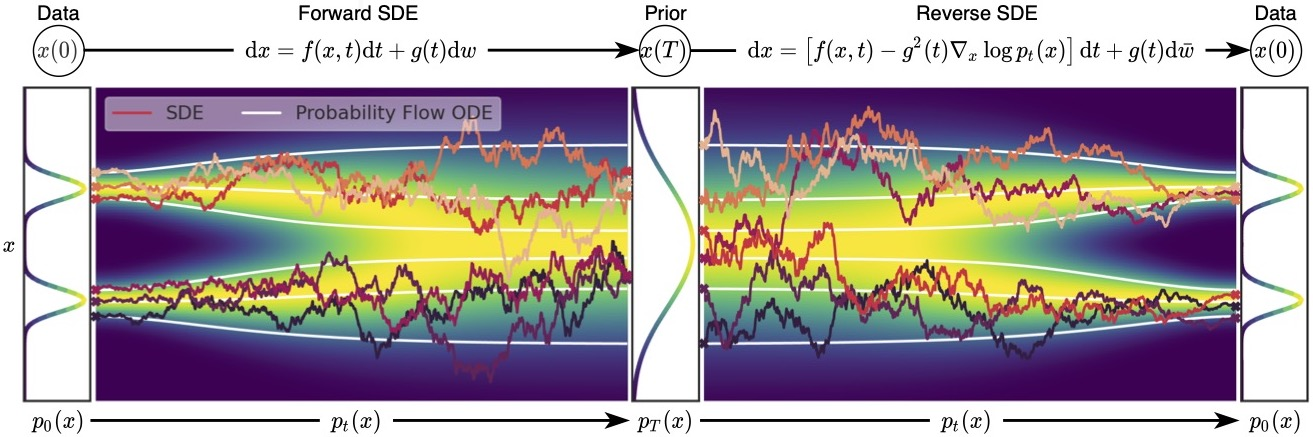
SDEs
Idea: take the number of noise scales to go to infinity, so that you have the pdfs p_t(x) for t \in [0, T] continuously
- p_0(x) = p(x) is the data distribution
- p_T(x) is pure noise
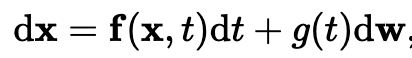 general form of an SDE
general form of an SDE
- dw is brownian motion
- in practice, you hand design the SDE. The SDE is part of the model, and it dictates how you add noise
Any SDE has a reverse SDE 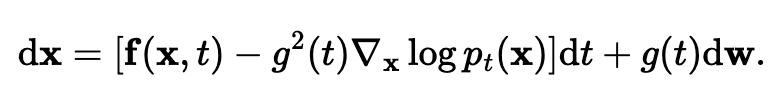

- notice the score function popping out
once again, we train a time dependent score function based on a weighted fisher divergence 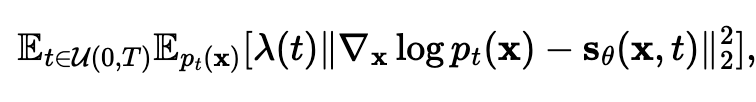 When you choose lambda(t) = g^2(t), you actually get that this is an upper bound to the KL divergence between p_0(x) and p_theta(x)!
When you choose lambda(t) = g^2(t), you actually get that this is an upper bound to the KL divergence between p_0(x) and p_theta(x)!
use numerical solvers to solve the reverse SDE for sampling.
Probability Flow ODE
Problem: with SDEs, we can’t compute the exact log likelihood of an x_0
You can convert any SDE into an ODE (difference is an ODE is deterministic) that has the same marginals  (no guarantees about the trajectories, i.e. as you vary t continuously, but same marginals yes).
(no guarantees about the trajectories, i.e. as you vary t continuously, but same marginals yes). 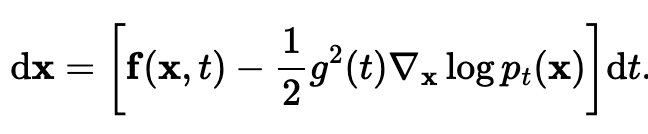
 And then since this becomes a neural ODE / continuous normalizing flow when you plug in the approximation s_theta(x, t), you can use numerical ODE solvers to compute the p_0 likelihoods.
And then since this becomes a neural ODE / continuous normalizing flow when you plug in the approximation s_theta(x, t), you can use numerical ODE solvers to compute the p_0 likelihoods.
Controllable generation
Bayes Rule for score functions 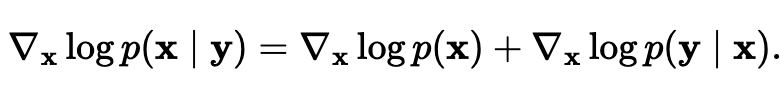 Have the first term on the right by score matching, and the second term they lowkey seem wrong about how you can get it. I feel like I like the lil log explanation of conditional diffusion more.
Have the first term on the right by score matching, and the second term they lowkey seem wrong about how you can get it. I feel like I like the lil log explanation of conditional diffusion more.
What is this useful for? 
- class conditional image generation

- image inpainting

- image coloration (hey wait a second that looks somewhat similar to what I’m doing for my UROP uh oh)
Connection to diffusion models
on the surface, seems like they’re different because
- score based models are trained by score matching and sampled by Langevin dynamics, while
- diffusion models are trained by ELBO and sampled with a learned decoder
but turns out the ELBO loss is equivalent to the weighted fisher divergence objective
different perspectives of the same model family