ML Tea: Planning and Problem-Solving with General, Scalable Neuro-Symbolic Models
ML Tea LLMs \+ symbolic computing
This one’s a bit different since it’s a bunch of papers combined from the same author, who gave a talk at the ML Tea series.
Idea 1 (https://arxiv.org/html/2306.06531v3): LLMs suck at things like planning a trip while minimizing costs, or combinatorial optimization (e.g. solving a game of 24) through textual reasoning alone. But we have symbolic solvers that do this well. Do the following: 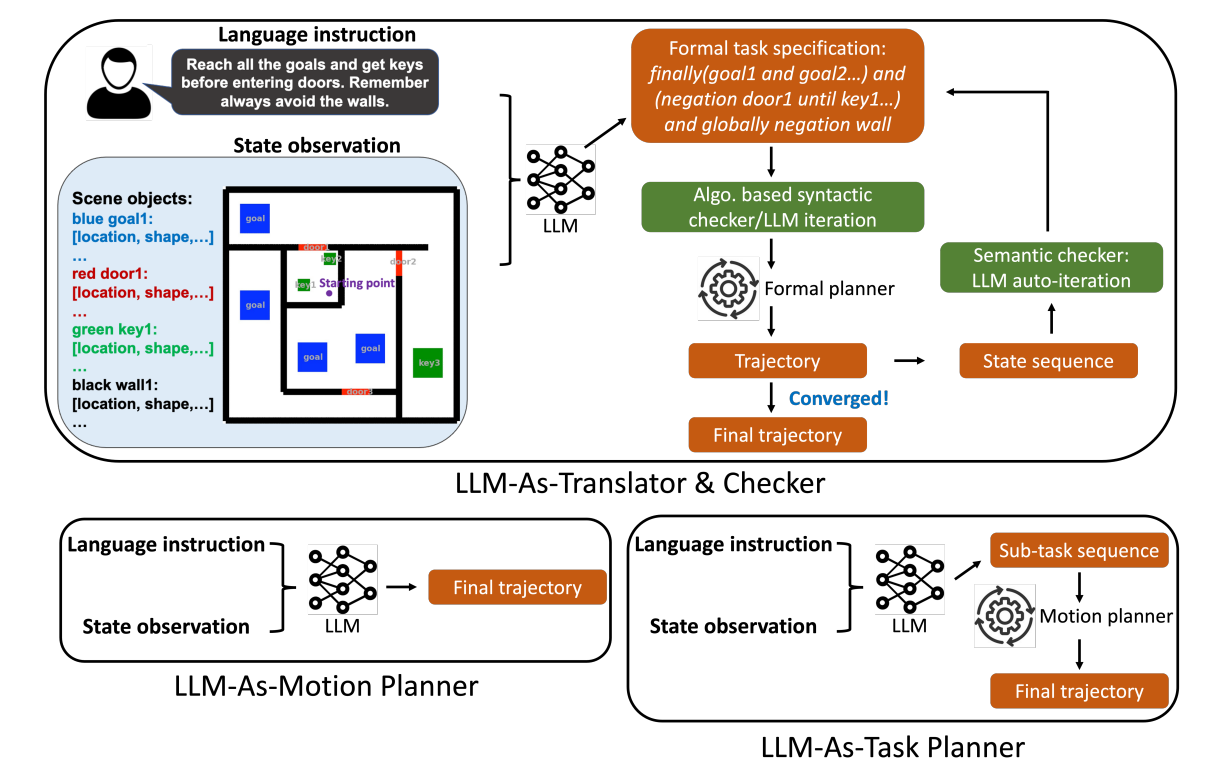
LLM: textual instructions → input format for the symbolic solver (can be a math solver, robot planner, etc)
- while syntax invalid, loop: syntactic checking
symbolic solver ->(no AI here) actual actions ->(no AI here) resulting state space resulting state space -> LLM, have it check if the output seems correct given the original instructions
- while unreasonable output, loop: semantic checking
Problem with idea 1: one of the good things about LLMs is that they’re generalizable, but this requires a specific symbolic solver for each new use case.
Idea 2: what if we use code as a symbolic solver instead? have the LLM just write code. https://arxiv.org/pdf/2503.01700? Problem: doesn’t ChatGPT already do this? Answer: Yes. But is ChatGPT doing it inside a robot? I didn’t think so.
Idea 3: Ok, maybe always using code as a symbolic solver isn’t ideal. We’ve discussed three ways to do planning so far: use pure textual reasoning, use symbolic solvers, and use code. Surprisingly, ChatGPT sucks at knowing when to use which: for like 7 _ 9, it gets it right by textual reasoning. For like 123849238 _ 192030910, it gets it right using code. But for like 238 * 193, it gets it wrong sometimes with textual reasoning. So maybe there’s some utility in training a model that learns which type of assistance (or lack thereof) to use when.
- note in this example, we’ve sort of shown textual reasoning as inferior to code, but there are cases where textual reasoning is preferred
Idea 3.1 for how to do routing: CodeSteer https://arxiv.org/pdf/2502.04350
- train a small helper model to help do routing for a larger model (they used LLama-3-8B to route for GPT-4o)
- tells the larger model what sort of approach (reasoning, search, code, etc) to use,
- how is this helper model trained? SFT on the multi turn traces, and then DPO on guidance comparison pairs
- for SFT, they ran into something called gradient cancellation, which basically on the first step, since there could be multiple different routes to an answer, different traces would recommend different things, and the gradients would cancel which was sort of bad [I don’t totally understand this]. They fixed this by weighting the last 2 actions in the trace most heavily
 Results? They actually beat o1, with this 4o + CodeSteer. But to be fair, this was an o1 using only textual reasoning.
Results? They actually beat o1, with this 4o + CodeSteer. But to be fair, this was an o1 using only textual reasoning.
Idea 3.2 for how to do routing: combine the LLM and the router into just one model, trained using GRPO https://arxiv.org/pdf/2505.21668? most of this paper is about how finicky GRPO is 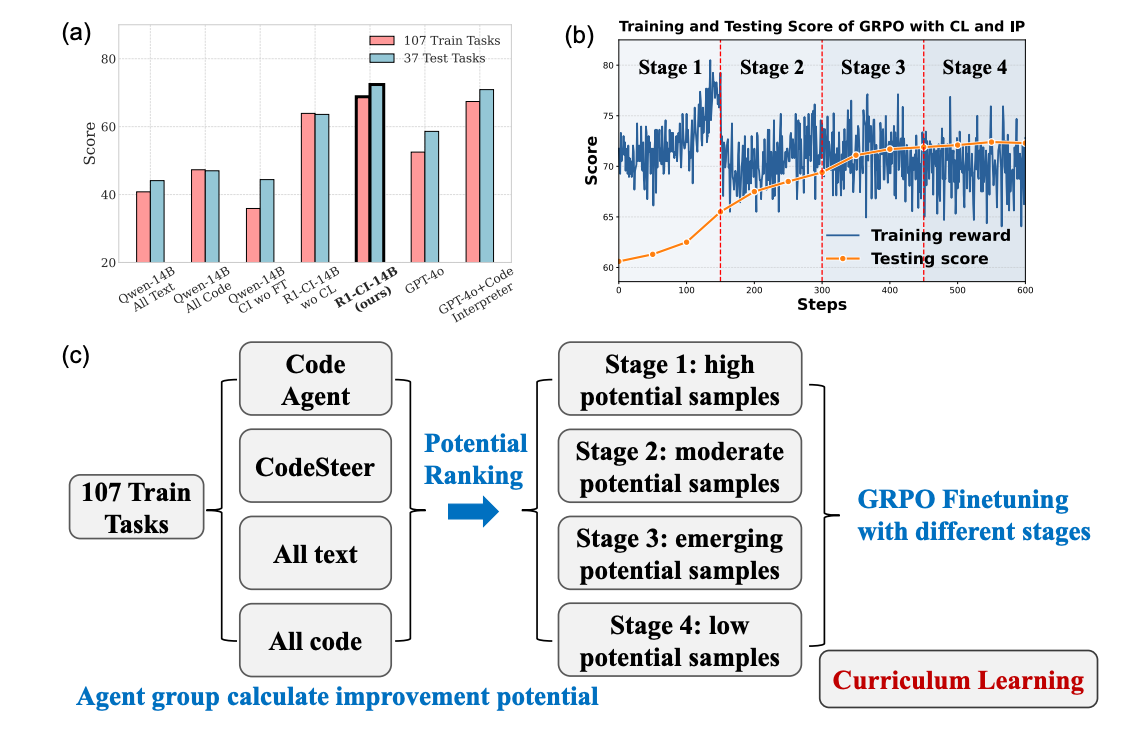
- GRPO initially didn’t really work, which they attributed to a lot of the calculated advantages (like the technical meaning of the word) being near 0
- so they reranked samples somehow based on their potential for learning, and used high potential samples first in training
- from what I can tell, potential just means “there’s some wrong outputs and some right outputs” or smth like that
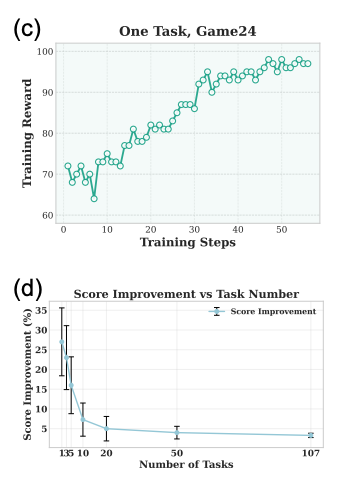
- Without the aforementioned curriculum learning, GRPO sucks at multiple tasks at the same time, but works well on singular tasks.
Idea 3.3 for how to do routing https://arxiv.org/pdf/2510.01279? TUMIX (with deepmind). Simply do all the approaches, don’t bother routing. After each round of getting answers from the different approaches, feed each approach the knowledge of what everyone else answered in the previous round, and keep iterating.
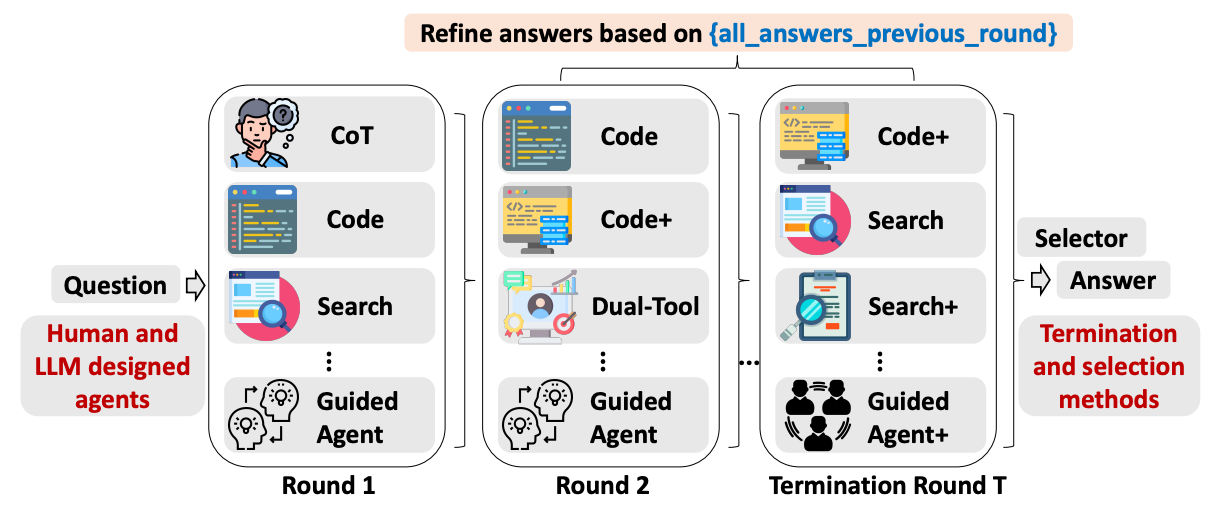
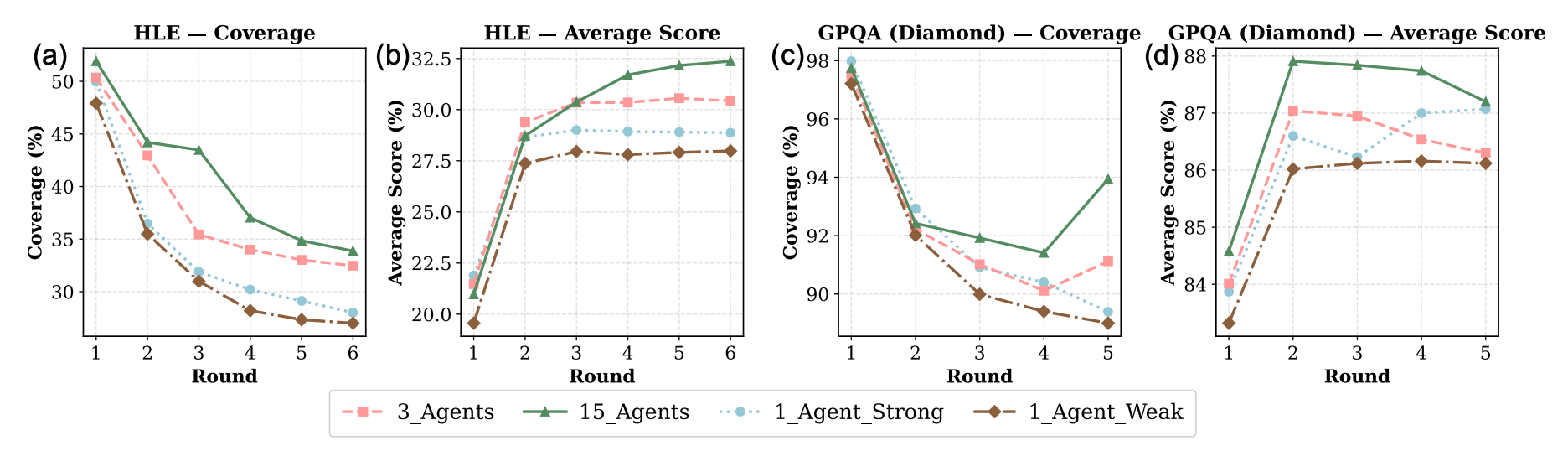
- very important to have diverse approaches when you’re doing this. Sampling the same strongest approach 15 times does not do nearly as well.