Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
Multiagent Fine Tunes
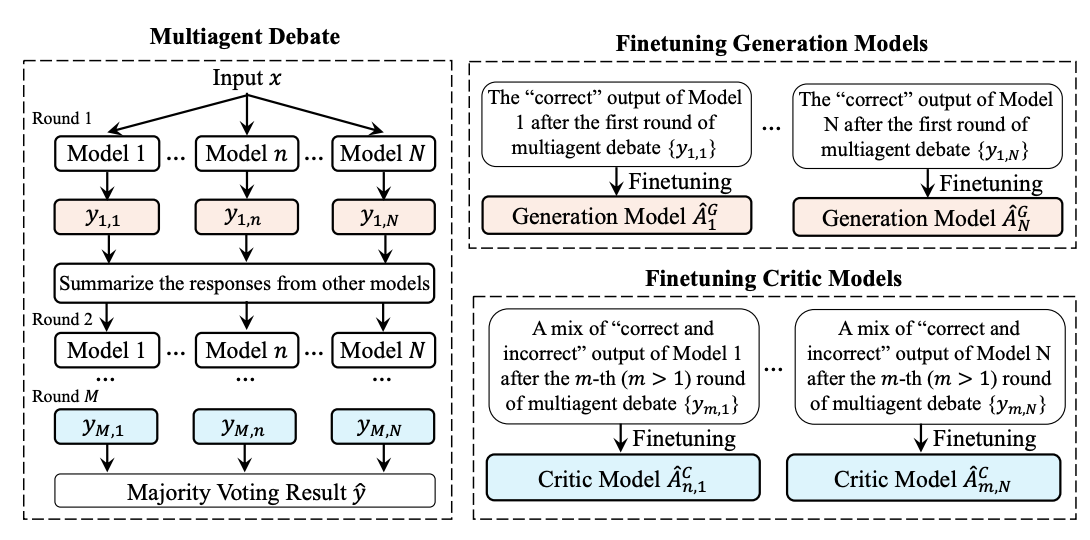
want to get an answer through multiagent debate: multiple specialized copies of the model produce answers, and then critics refine the answers
- generator model generates the initial answers
- critic model produces later answers, given summary of the other models’ answer (but not its own model’s answer)
also want to fine-tune the models on their own outputs. Key issue is that if you do this for a couple of iterations usually, loss plateaus and then starts going down and you lose diversity.
key to keeping diversity: train each model on only its own correct outputs (correct = matches majority voting final answer, don’t have the ground truth).
Results:
- do better than majority vote baselines / STaR / single model fine tunes
- have higher diversity, which is measured by each model’s NLL of the other models’ outputs