Weight-sparse transformers have interpretable circuits
Leo Gao OpenAI sparse circuits
Below notes are taken from his ML Perf reading group talk, not my own notes on his paper
Motivation / comparison to SAE’s
- review: SAE’s train to reconstruct the residual stream using a wide autoencoder that’s sparsely activated
- issue: how did the model get from a feature in one layer to a feature in the next layer?
- anthropic tried to solve using cross layer transcoders, same sparse autoencoder to try to predict the next layer’s activations given the previous layer (SAE’s are trying to reconstruct the current layer given the current layer); transcoders are essentially approximating the attention / MLP layer
- issue is that their errors compound
- why can’t you just scale them up? can’t increase the L0 (the number of things active) because then at some point you’re not a bottleneck, also can’t make it wider since each thing activates less frequently because each feature is more granular, break your features into smaller features that don’t make sense
- some features are naturally sparser than others
- want to enforce circuit sparsity in addition to feature sparsity
- the connections from interpretable features in the layer’s transcoder bottleneck to interpretable features in the next layer’s transcoder is still dense (it’s one decoder and then another encoder), that feels like it shouldn’t happen: in the real world, we expect sparse relationships between features
- circuit sparsity actually just corresponds to having sparse weight matrices, since the edges between nodes are just weights (described below)
Questions for Leo: “We also enforce mild activation sparsity at all node locations, with 1 in 4 nonzero activations” what does this mean that’s not already covered in the “sparsity of all weights and biases”?
- answered below basically
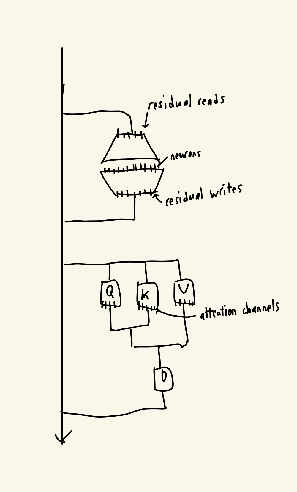
What exactly are the different nodes? I assume neurons are the individual scalars in the hidden layers of the MLPs, and that residual reads and residual writes are the projection matrices from the residual streams, but what about the attention channels?
- every node is like a row of a matrix
- residual reads is like when you project from the residual stream, you get a few scalars
- neurons are the activations in the hidden layers of the MLPs
- residual writes are the outputs before we add back to the MLP
- attention channels are just the QKV vector elements
- every edge happens to be a single weight in the model
After pruning, how did they go about interpreting the remaining circuit?
For pruning, are the nodes mean-ablated during training when you’re learning the masks? Or do you only mean-ablate the nodes after you’ve trained the masks and figured out which nodes you’re deleting?
- the pruning is not the important part of the paper. main idea is they just train a mask on each of the things they’re trying to make sparse (and have some weird bisection thing). Appendix A
What hope is there that these results generalize? since we don’t want to do sparse pretraining in general
- sparse and dense models might be similar: they have a 0.93 correlation in the losses on each token (dense and dense with different seeds is 0.94), figure 33
the ] vs ]] circuit
- attention can’t do a sum, it can only do mean. it approximates the sum using something explained in the paper
- attention sinks: you basically have a token (here they forced it, sometimes the model learns it itself) that acts as like 100 tokens, so when you average over 101 of them instead, it’s not super different. Basically approximate this by the attention being like 99/101 on that token or something
- but then if you elongate the context length, it goes below the threshold
offline talking
Question: how do you actually know if the feature that you’ve identified (e.g. in a SAE) is actually the “dog” feature? 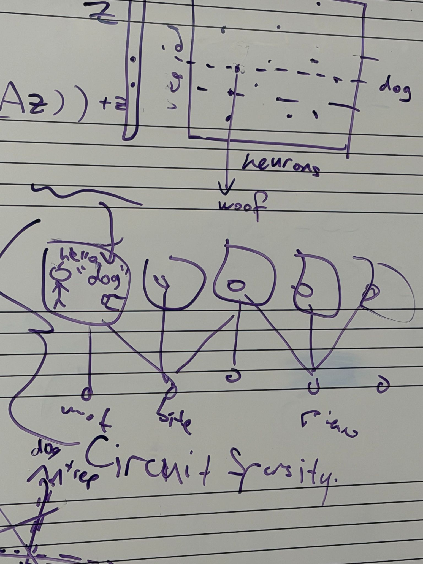 answer: you expensively replace that activation by manual labels of whether or not “dog” appeared in the input context, and see if your model still works
answer: you expensively replace that activation by manual labels of whether or not “dog” appeared in the input context, and see if your model still works
question: why does he hate his top k sampling paper? 
- they fail at exactly this thing of checking if the feature that they’ve claimed is what they think it is
- let’s say there’s a feature that’s actually “dogs on jetskis,” but they think that it’s dogs. What they do is they check for completely randomly chosen inputs, that the feature is not activated, and for the top k most activated features, there’s dogs in the input
-
i.e. they only check that P(dog feature is high) = 100% -
but this doesn’t stop the feature from actually being “dogs on jetskis”, this misses P(feature is high dog in input)
-
- it’s even worse when you have superposition (which is the multiple peaked things). Like maybe the medium (not 0, not high) activation levels of the feature correspond to different real life features like house and tree. You’re missing that entirely too, since random is not going to hit those concepts
Why do neurons suck? compared to other nodes
- neurons have a privileged basis. Residual stream and other parts are rotation invariant, but neurons (this is my conjecture) have the GELU part that depends on the basis
general advice: figure out research taste, make predictions about what’s going to be important and then check back in 2 years (e.g. GANs, capsuleNet died), write a lot of code and run a lot of experiments. Having a mentor probably helps a lot. Execute on your mentor’s research taste and slowly develop your own research taste that’s not your mentor’s, try your own takes.
How to read hard papers? talk to the authors instead / talk to other people instead
how to find which papers to read? vast numbers of papers, most of them were bad.