Building Diffusion Model's theory from ground up
ICLR Diffusion explained blogpost
We need to be able to sample from a generative model p_theta(x) that approximates q_data(x) 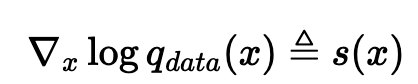 the score function of the data distribution interests us
the score function of the data distribution interests us
- compared to q_data(x), we think it might be tractable because the normalization term dies
Generate a new sample, assuming we know the score function perfectly
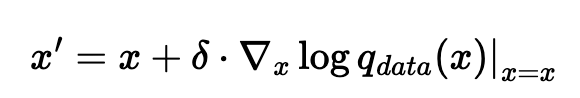 if we just naively optimize it through gradient descent, we’ll only go towards the peaks of the distribution
if we just naively optimize it through gradient descent, we’ll only go towards the peaks of the distribution 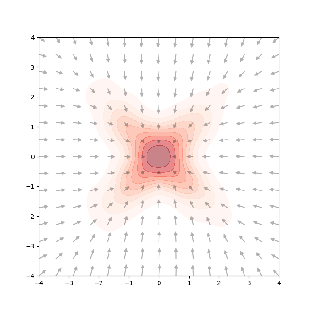
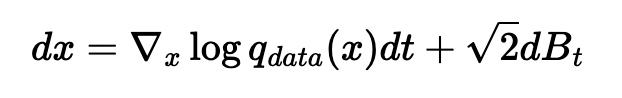 but langevin proved that if we follow this and add a little bit of noise at each step (B_t = brownian motion = N(0, dt)), then we do end up sampling from q_data(x)
but langevin proved that if we follow this and add a little bit of noise at each step (B_t = brownian motion = N(0, dt)), then we do end up sampling from q_data(x)
Fokker-Planck equation (only helpful in theory): shows how the probability distribution p_t(x) evolves over time; at t = infty, it becomes q_data(x) 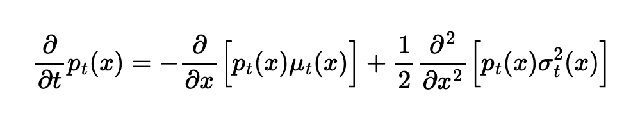 shows that we can start from any initial distribution p_0, and following langevin sampling transforms us to q_data
shows that we can start from any initial distribution p_0, and following langevin sampling transforms us to q_data
Estimating the score function
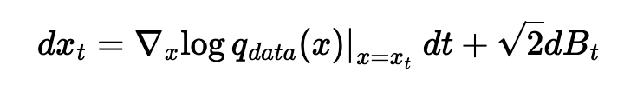 estimating the score function directly as s_theta(x) isn’t expressive enough provide the time t as well, s_theta(x_t, t) is probably sufficient
estimating the score function directly as s_theta(x) isn’t expressive enough provide the time t as well, s_theta(x_t, t) is probably sufficient
but how do we get samples? Going from t=infty q_data(x) to t=0 N(0, I) : forward diffusion process! 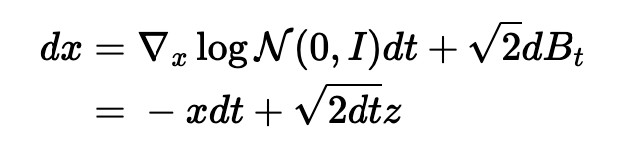
- the score function of the normal is really nice
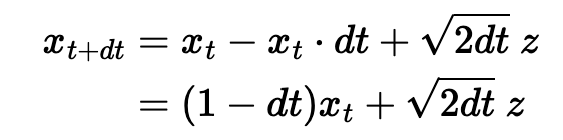
- discretize the equation

- and then transform the time to go from [0, 1] instead of [0, infty]
- can do multiple forward steps at once
Ok, so now we can get samples from each time step t where we want to learn the score function. That still begs the question — how can we learn the score function without having the true score values?
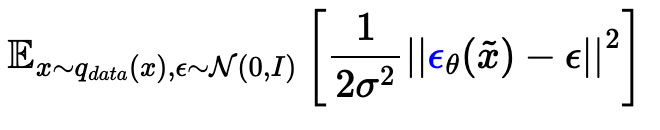
- from a noisy sample, learn the original clean sample
- this somehow learns the score
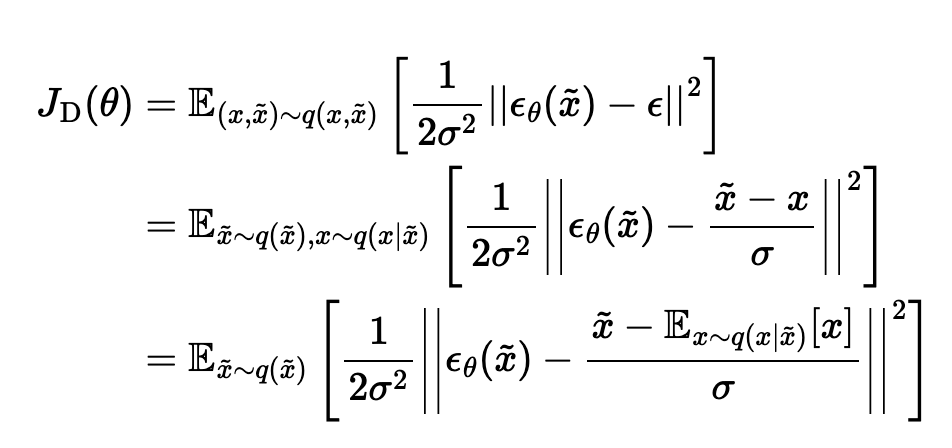
- another interpretation of this same objective: given noisy sample, it’s learning the expected direction of the noise that was added to get this sample
There’s another interpretation with Tweedie’s formula (but lowkey 6.7810 probably did that better)
There’s a whole other interpretation of diffusion models that doesn’t go through SDEs at all.