Between the Bars: Gradient-based Jailbreaks are Bugs that induce Features
Gradient Based Jailbreaking
Apparently, this paper was written in the matter of three days, and is complete noise.
Analyzing gradient based jailbreaking attacks (nanoGCG), where you append a suffix to the prompt and then optimize it to make the model do bad things when it generates later. Claim is that they’re bugs but they reveal actual features representing harmful responses in activations.
gradient based attacks are very out of distribution (“bug”):
- compared their max probabilities of picking the next token to that of a baseline suffix which just takes the nearest neighbor of each token (i.e. is semantically similar), and finds that the gradient jailbreak’s is way lower
model activations for the jailbroken and baseline prompts are different
- if you K-means cluster with 2 clusters, you recover most of the jailbreak vs baseline grouping
- we can compute a steering vector which is just the difference in the mean activations of the final token in the suffix (prior work says that most of the contextual embedding is in this final token)
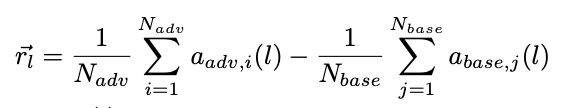
- now add this steering vector to plain HarmBench prompts, and boom it causes bad behavior
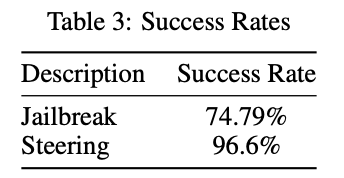
- and if you subtract this steering vector, you get good behavior
- steering most effective in middle layers
Glitch tokens appear frequently in the jailbroken prompts — suspect that these are seen rarely during training time
good summary 