DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek V3.2
MLA explanation (not this version of deepseek, but necessary knowledge)
https://arxiv.org/pdf/2405.04434 deepseek v2 paper
Motivation: storing the KV cache is expensive, and MHA / MQA / GQA aren’t a perfect solution. Maybe instead, we can store two latent smaller vectors: one for the query, one for the key and value (project onto a small subspace). Then to get the actual query, key, and value, we’ll up-project from the latents instead with many up-projection weight matrices, and do MHA with those qkv’s. 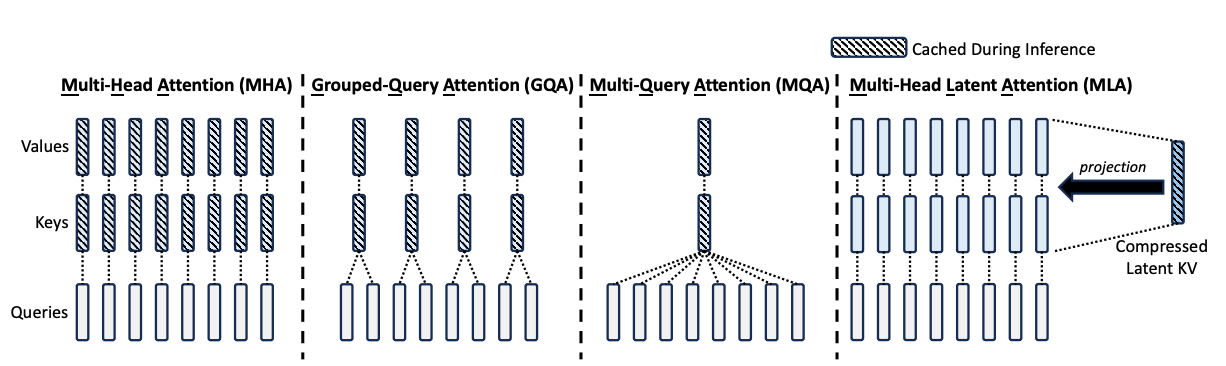
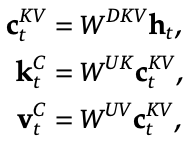
- key thing here: we only cache the c_t^KV, the latent.
- because we’ll later do q^TK = smth W_q^T W_UK c_t^KV, so we never have to instantiate the keys

- can do this in normal MHA, but it won’t save on efficiency because x and k the same size per token
- using fixed W^(UK) matrix, we generate d_h different keys and values
- do queries separately but similarly
But once you introduce RoPE, you no longer get W^Q and W^UK together, can’t just store the latent 
How to fix this? Decoupled RoPE 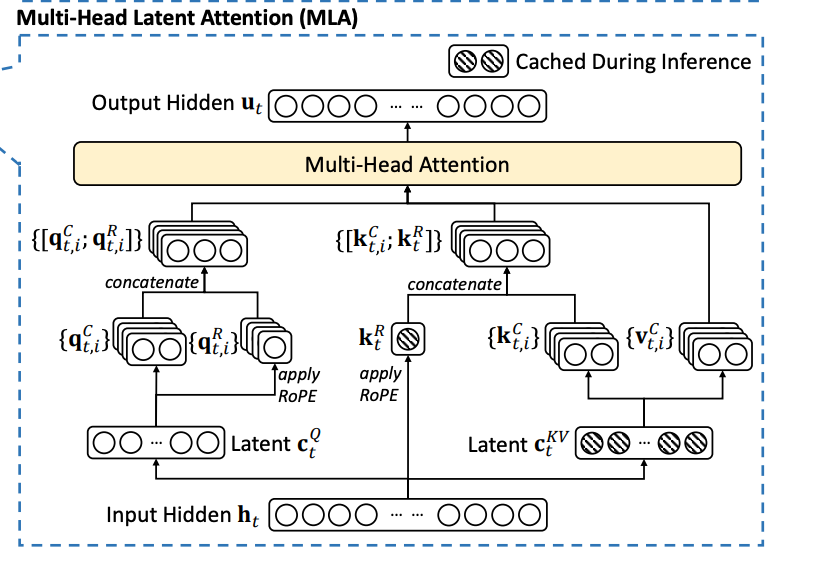 have some extra components of the query and key (a relatively small subspace) be for position information, and only apply RoPE to those components
have some extra components of the query and key (a relatively small subspace) be for position information, and only apply RoPE to those components
- have to cache the k_t^R’s now, but that’s fine because it’s smaller than the normal key
Deepseek sparse attention
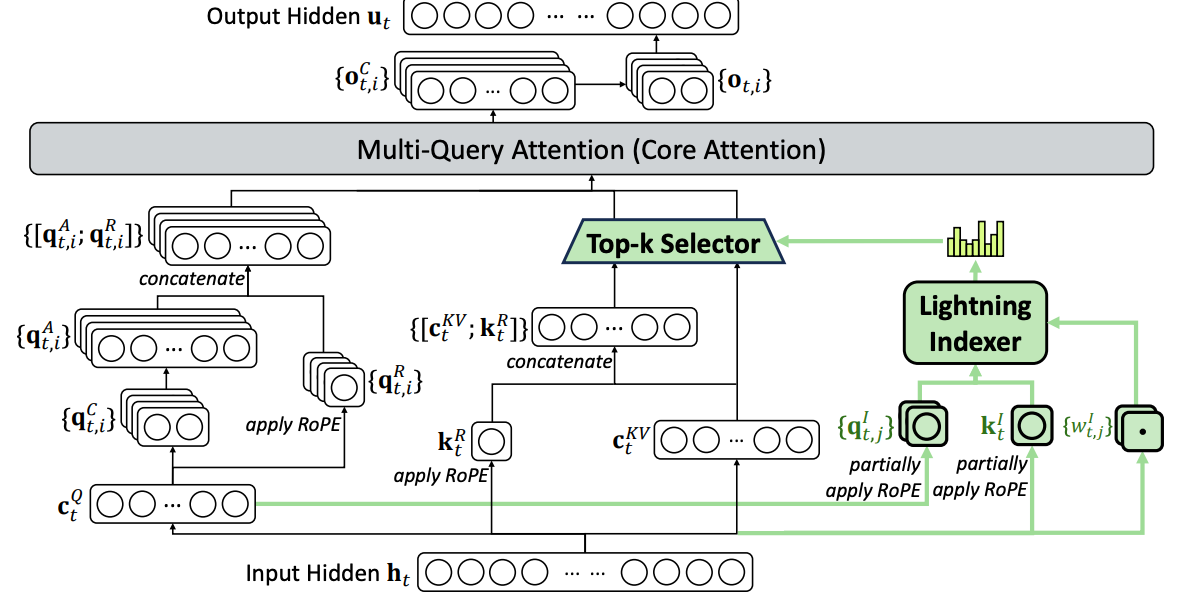 O(Lk) attention instead of O(L^2) !!! Use MLA but with the key and value vector shared for all heads
O(Lk) attention instead of O(L^2) !!! Use MLA but with the key and value vector shared for all heads 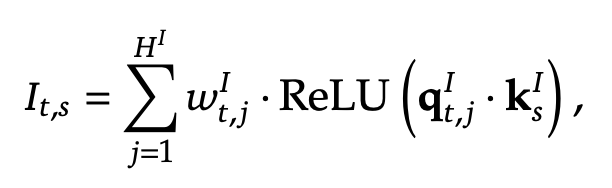 Lightning indexer to pick out the top k relevant tokens, only consider attention over those tokens
Lightning indexer to pick out the top k relevant tokens, only consider attention over those tokens
- why this is faster: fewer indexer heads H^I, smaller query and key size
continued pretraining Trained softmax(I_t, s) KL loss with the actual dense attention values
- initialize by freezing other weights and just training this network
- keep training it separately from the language modeling loss during sparse attention
- feels sort of analogous to training a router for MoE: why don’t we do the same thing as there?
checked using benchmarks that this doesn’t degrade on long-context tasks!
Posttraining
specialists
- trained a v3.2 base model on domains like mathematics, programming, general logical reasoning, general agentic tasks, agentic coding, and agentic search
- one thinking, one non thinking
- why use specialists as opposed to just training on the data that the specialists were trained on?
- probably can get more data
GRPO on reasoning, agent, and alignment at the same time to avoid catastrophic forgetting
- lol contradicts the ML tea talk on multiple tasks GRPO
Speciale
- reduced length penalty during RL
- only trained on non thinking versions of the data
- added DeepSeekMath-V2 reward
Scaling GRPO (10% of data was RL wow)
TLDR for this section: a bunch of mitigations to control the difference between the rollout sampling with the old model and the new model currently being trained
Original GRPO objective 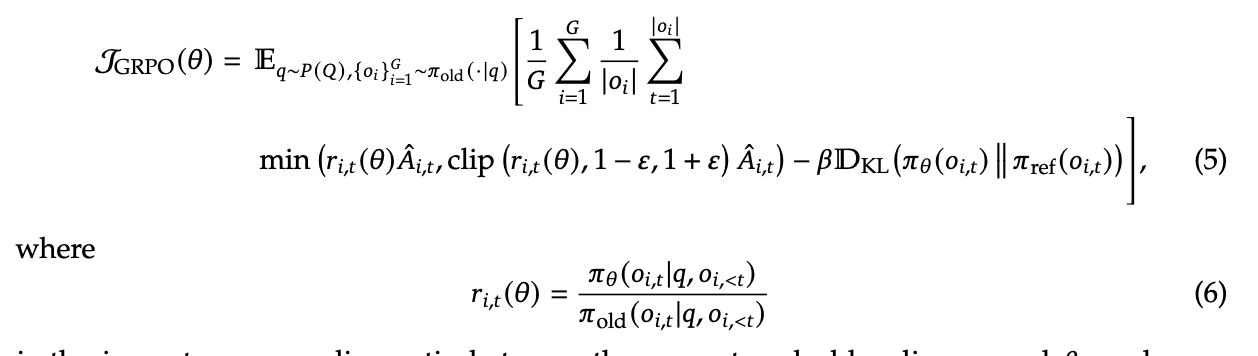
- clipping term just makes sure you can never have too big of an update due to old and new policies being different
- KL term is to not have catastrophic forgetting
- don’t need a KL term for specialists because they can catastrophically forget
- that second term is just a Monte carlo estimate of the KL divergence between π_old and π_theta according to the samples
- model learns from its mistakes (A_i, t < 0) the most, don’t want it to train unstably on the mistakes where it’s very off-policy
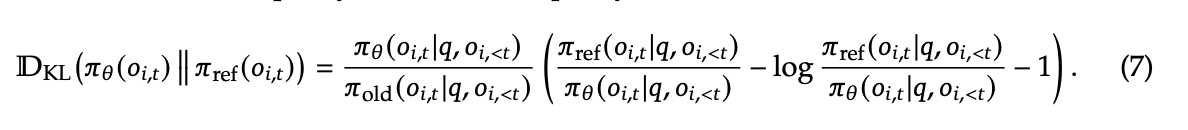 Used importance sampling in the estimator of the KL in order to make it unbiased (the first term)
Used importance sampling in the estimator of the KL in order to make it unbiased (the first term)
- crazy that people didn’t have that before wtf
https://arxiv.org/pdf/2402.03300 their first GRPO paper 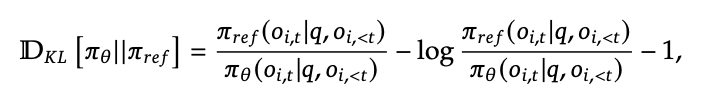 wtf yeah they actually did and no one pointed this out how is that not standard
wtf yeah they actually did and no one pointed this out how is that not standard
Keep routing: use the same experts in the MoE during training as you sampled from for the rollout in the first place
Keep sampling mask from topk truncation between old and new policy
Thinking agents
Context management
- problem: reasoning in <thinking> tags takes up a lot of space
- previously, got rid of it every step
- now, just get rid of reasoning on new user message. And don’t get rid of the tool call outputs
- discarding 100% of tool call history when you run out of context actually beats summarizing (so what is Anthropic’s compacting thing doing?)
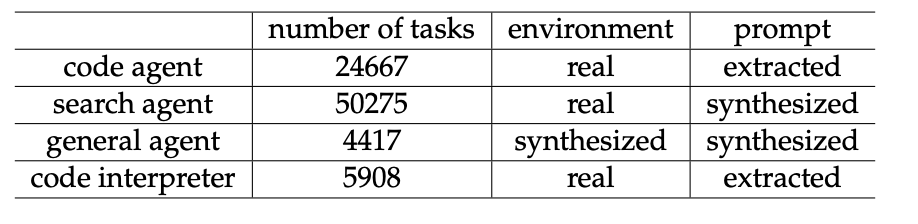 search data: pick an entity, search stuff about it, generate Q\&A, have a bunch of LLMs try to answer, only keep hard ones where ground truth is true but candidates were all wrong; responses are graded by llms by some rubric
search data: pick an entity, search stuff about it, generate Q\&A, have a bunch of LLMs try to answer, only keep hard ones where ground truth is true but candidates were all wrong; responses are graded by llms by some rubric
code: issue-pull request data from github, another agent builds the coding environment, only keeps ones where the patch actually works
code interpreter: math and code tasks on jupyter notebook
General (synthetic data): start with task category, gather a bunch of data on the internet. Come up with a set of tool calls, then an environment, verifier, and task, iterate on the tool calls and difficulty
- interesting ablation: when RL on this synthetic data, generalizes better than deepseekv3.2-exp, which is only RL’d on search and code
Results:
worse than gemini on reasoning, comparable to kimi k2 with less tokens better than open source on coding worse than proprietary on tool use speciale gets imo gold without targeted training
- less efficient in token usage than gemini