SliderSpace: Decomposing the Visual Capabilities of Diffusion Models
Sliderspace
Half of the captions on the blogpost are wrong and are the same exact caption about 1 erasure
Overall goal: self-supervisedly decompose a diffusion model’s understanding of a concept into disentangled interpretable directions that can then be tuned using sliders
More specifically, we want these controllable directions to
- span the major modes of variation in the possible images that can be generated
- appear consistently across different initializations
- are orthogonal
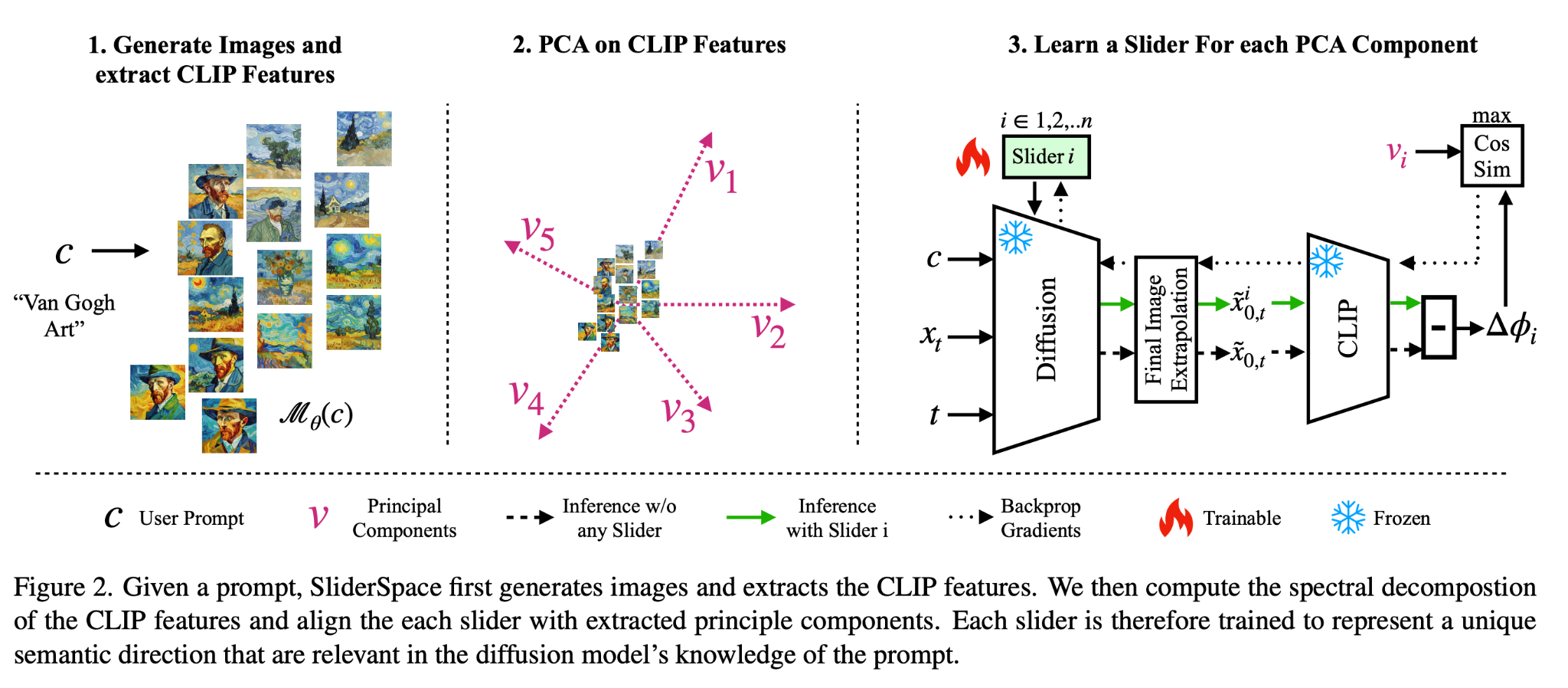
observation: for the predicted denoised samples, they do 5000 trajectories, but they actually take the intermediate predicted denoised samples from each timestep in each trajectory
- (recall that you can do this because the reverse process of diffusion has many equivalent parameterizations: epsilon_t, x_0, x_{t-1}, score, etc)
-
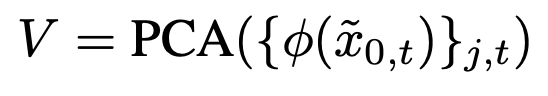
- so the final set of embeddings that they end up doing PCA on is much larger (j is the index of the trajectory, t is the timestep in that trajectory that you’re predicting the final image from)
- Why do they do this? (from Gemini, not from the paper) Reason #1 is that you want to find directions that are consistently semantically meaningful throughout the entire generation process. Reason #2 is that this just gives you more data
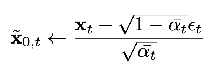
For the training of the slider, it’s a completely different slider from their concept sliders training method 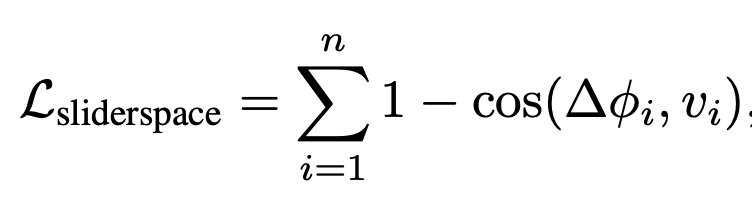
- Sample a data point and a time t
- (conditioned) predict x_0 with the slider (lora) and without the slider. Run both of the predictions through the CLIP embedding; the difference in embeddings is ∆phi_i
- Compute the cosine loss as above
- this incentivizes the slider to get the embeddings perfectly along the direction of that principle component
I’m somewhat curious if they ended up using the singular values, since they should have that from PCA as well. Were the top principle components more interesting somehow?
Applications
Application #1: Concept Decomposition
Use claude sonnet to label what the sliders are actually doing by giving it a bunch of image pairs
By randomly activating a sparse subset of 3 sliders for each image generation compared to the base model, the generated images have higher DreamSim diversity, while maintaining similar CLIP scores wrt the input prompt (so you’re not cheating)
Application #2: Art styles exploration
Have a dataset of all art styles from ParrotZone, which we then use as prompts to generate a ground truth dataset of all art styles in images. Metric is FID score against the distribution of images generated in these styles, which measures how good the match is to the diversity and quality of the real art styles
For evaluating sliderspace, used the prompt “artwork in the style of a famous artist,” got the sliders out of it, and then generated by again taking a random sparse sample of 3 sliders and using those
Baselines used:
- having chat generate 64 styles and then manually training concept sliders on those (second best)
- having chat literally just generate style names and generating based on those style names
Application #3: Reinjecting diversity back into the distilled model SDXL-DMD
Ran sliderspace on a ton of COCO-30k prompts, the resulting sliderspace on SDXL-DMD has much improved FID (measuring diversity)
Bonus application: sliders learned for one concept are sometimes transferable to other concepts
- e.g. age transfers from person to dog, which is kind of surprising
Appendix
- as before, during inference we only start applying the sliders after the first few steps of denoising
- used Dino-v2 and FaceNet as alternatives to CLIP, can target choice of encoder to the target domain
- found that rank 1 lora’s were the best, and PCA’s marginal usefulness diminished after 40 dimensions
- Ablations:
- ablated PCA by training sliders against just a standard customization loss and no contrastive objective, get a bunch of redundant directions
- ablated using CLIP by applying directly on the diffusion output space, bet a bunch of directions that are more relevant perceptually (color, shape) but not semantically
- more diverse training data leads to more diverse sliders