SliderSpace: Decomposing the Visual Capabilities of Diffusion Models
concept sliders
 Continuous, composable, out of the box sliders for image editing train lora adapters on diffusion models
Continuous, composable, out of the box sliders for image editing train lora adapters on diffusion models
Training the LoRA
When we can condition on the desired property, i.e. it’s in text form
(I think the blog post has a typo swapping theta and theta* in the first paragraph of “Textual Concept Sliders” ) 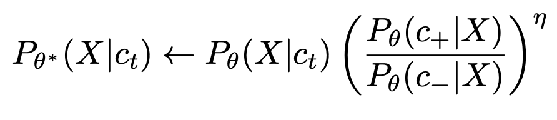 our goal is to get model theta*: theta is the original model, c_t is the prompt you condition on, want to bias the slider towards exhibiting property c+ and not property c-
our goal is to get model theta*: theta is the original model, c_t is the prompt you condition on, want to bias the slider towards exhibiting property c+ and not property c-
if you do some Bayes rule algebra, this rearranges to 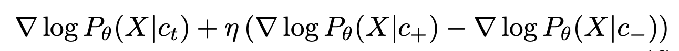
and then Tweedie’s formula + a reparameterization trick (elaborated on below) turn the above into this following description of how the new noise prediction looks
- recall from here that Tweedie’s formula gives you a relation between the score and the source noise
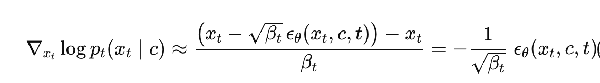
- Now plugging this back into the bayes’ rule equation and then dividing both sides by sqrt(beta_t), we get the desired equation in terms of the noise predictions
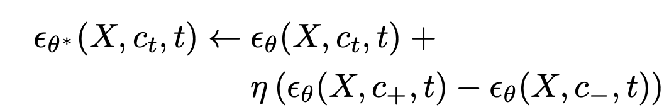
- In practice, because concepts like age are often entangled with other concepts like race, we choose a bunch of p’s to hold fixed, and get the model to favor c+ over c- while controlling for each of the p’s one at a time
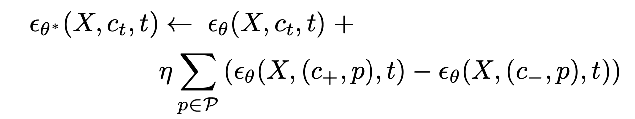
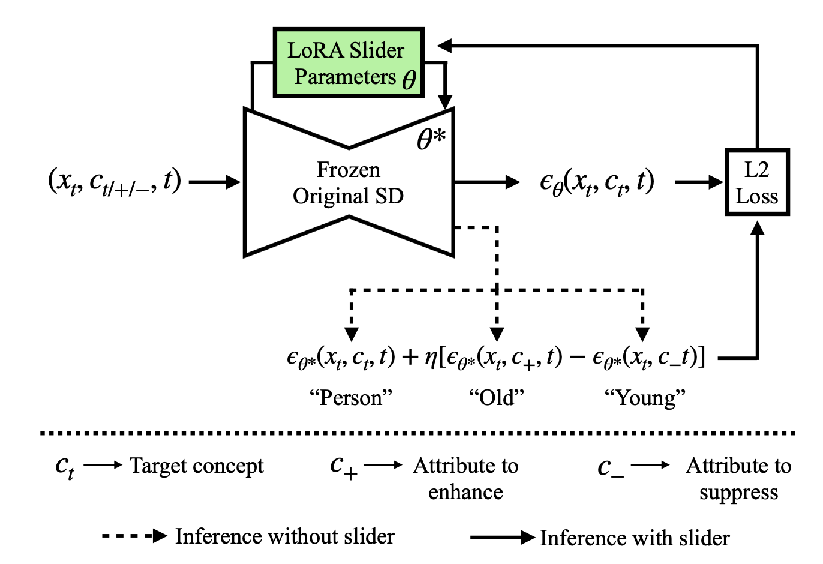 I think this figure also mixes up theta and theta* on the two boxes So the actual distillation training loop for the lora adapters looks like the following:
I think this figure also mixes up theta and theta* on the two boxes So the actual distillation training loop for the lora adapters looks like the following:
- generate x_t by partially denoising from the frozen diffusion model.
- At the fixed x_t, run the frozen base model multiple times with different text conditionings: only c_t, and then c_t with all the properties included or not included as well (RHS of equation (8))
- then use L2 loss to get the prediction of the lora-included network, epsilon_theta* (x_t, c_t, t), to be close to the RHS of equation (8), the equation with the eta term.
When we don’t know the desired property e.g. we have a bunch of image pairs that are positive and negative for the property 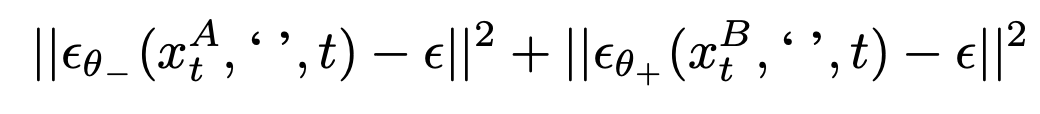
- the ground truth label is no longer a prediction from the original model
- A is the negative image, B is the positive image
- generate source noise epsilon, pick a time t, and then couple the noise added to x_t^A and x_t^B
- then train the model with the - alpha ∆W LoRA to predict that noise leads to A, and the model with the + alpha ∆W LoRA to predict that noise leads to B
Surprisingly, the place where they get continuous modulation from during inference is not eta, it’s from alpha in the LoRA 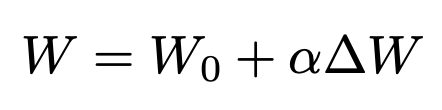
Experiments
Use Stable Diffusion XL During inference time, use the original model for first t steps, and then turn on the LoRA adaptors for the remaining steps (following SDEdit paper)
I’m gonna give up on the baselines for now, hopefully not too important
Textual Concept Sliders Table 1
- Want high ∆ CLIP score (change in CLIP score between original and edited images evaluated on the text prompt describing the desired edit) — achieved feature change
- CLIP score is actually its own separate paper from the actual CLIP paper
- Want low LPIPS distance to original image — less distortion of other features
Visual Concept Sliders Table 2 / Figure 4
- specifically just for the Ostris dataset about change in eye size, since they can measure exactly the change in eye size.
- and then min LPIPS distance as before
Figure 5: move a neuron around in StyleGAN, and then train a slider using the image pairs mode
Figure 6: composing two sliders Figure 7: composing up to 50 sliders
Figure 8, 10: repairing images
- note that user preference differs from FID (Frechet Inception Distance, automated metric for image quality)
Figure 9: repairing hands
- positive prompt was “realistic hands, five fingers, 8k hyperrealistic hands”
- negative prompt was “poorly drawn hands, distorted hands, misplaced fingers”
used amazon mechanical turk user studies for judging if the issues were fixed
Section 7 — ablated using low rank (probably did a full fine tune) and using disentanglement. Found that both help keep you closer to the original image, and they help target the change to that one particular feature.
Appendix You can edit real images using concept sliders by using null inversion https://null-text-inversion.github.io/ to turn the real image into an unconditional diffusion outputted image