A Mathematical Framework for Transformer Circuits
Transformer Circuits Framework
Only working with <= 2 layer transformers, ignoring MLP’s, layernorm
the residual stream
 the residual stream is how each token’s vector gets passed through, and attention heads and MLP’s are doing linear operations on this residual stream
the residual stream is how each token’s vector gets passed through, and attention heads and MLP’s are doing linear operations on this residual stream
- each attention head is low rank → reading and writing to a small part of the residual stream
- residual stream functions as a “memory,” you even have some operations learn to delete stuff from memory
But the MLP’s have 4 * d_model neurons, how to store all that in residual stream?
- superposition (neel nanda references the toy model paper)
- most of the features are sparse, so even if there’s 10000 features, only 100 of them occur at a time
- a lot of the features are negatively correlated (don’t show up in the same scenarios), so you can have them in the same directions
- connection to CS 336 lecture 3: this is why the residual stream has to be linear and the layernorm should be outside of it, otherwise superposition becomes super messy
but this does make the residual stream really hard to interpret (it also doesn’t even have a privileged basis due to rotations), so we won’t try to. Instead, we will focus on individual paths through the transformer
parts of attention
Two actually mostly independent parts
QK-circuit: A = softmax(x^T W_Q^T W_K x)
- W_Q^T W_K acts together as a low rank matrix, W_QK
- bilinear operation, determines how information is moved between tokens
OV-circuit: Ax W_v^T W_o^T
- W_oW_v acts together: W_ov
- linear operation on the residual stream
(tensor product A \otimes W applied to x just means AxW^T)
Zero Layer Transformers
No information movement, so just W_UW_E (unembedding and embedding), learns to predict next token from current token → bigram model
One layer Transformers
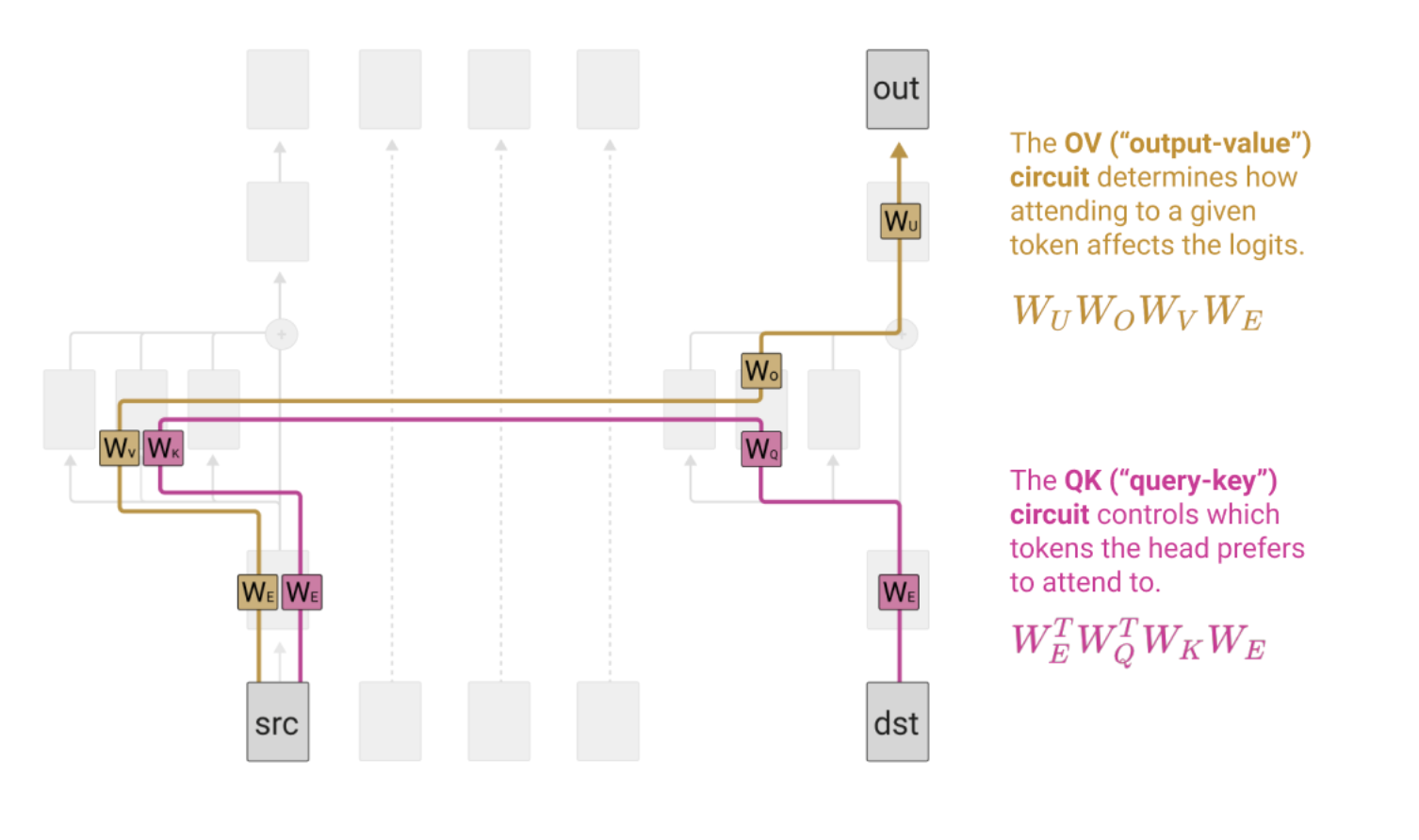
- if different destination tokens want to attend to the same source token, the only thing they can modify is how much attention they pay to that source (purple), not what value it gives (the gold)
- illustrated below using the skip trigram bugs: keep … in mind and keep … at bay are natural, but if you want the OV circuit to boost “bay” when you see “keep,” then it does that regardless of the destination, so keep … in bay happens
(remember: there’s one residual stream per token)
skip trigrams
- [A] … [B] -> [C]
- current token [B], QK circuit determines to pay attention to [A], OV circuit then determines how this affects the output [C]
- why skip? because transformer can pay attention to positional stuff (pay attention to previous token) or to value stuff (pay attention to barack), but not really both
- why tri? because only doing bilinear attention

Two Layer Transformers
Three types of composition: Q, K, V composition, depending on which inputs of attention come from other previous attention heads
- Q composition = contextual information about the current token
- K composition = contextual information about the source tokens
- V composition = virtual heads, less important
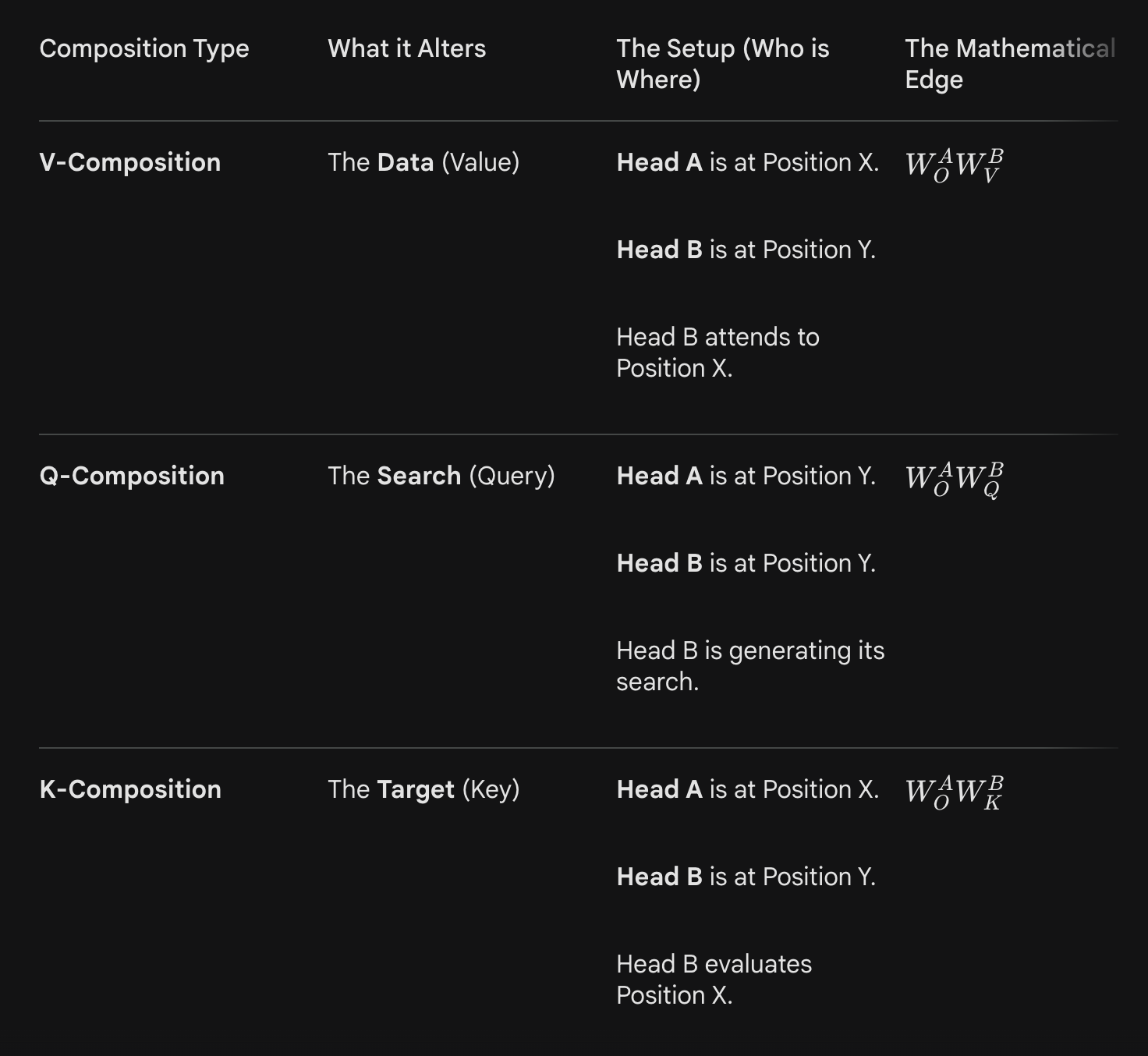
-
- For instance, for Q-composition, an earlier head and an earlier layer of the same token wrote to the residual stream, and that right gets picked up by the later head when it’s calculating the query.
- For K composition and V composition, it’s a head operating on a different token position whose output affects the key or value in that token position, which then goes on to affect the current token position’s attention output
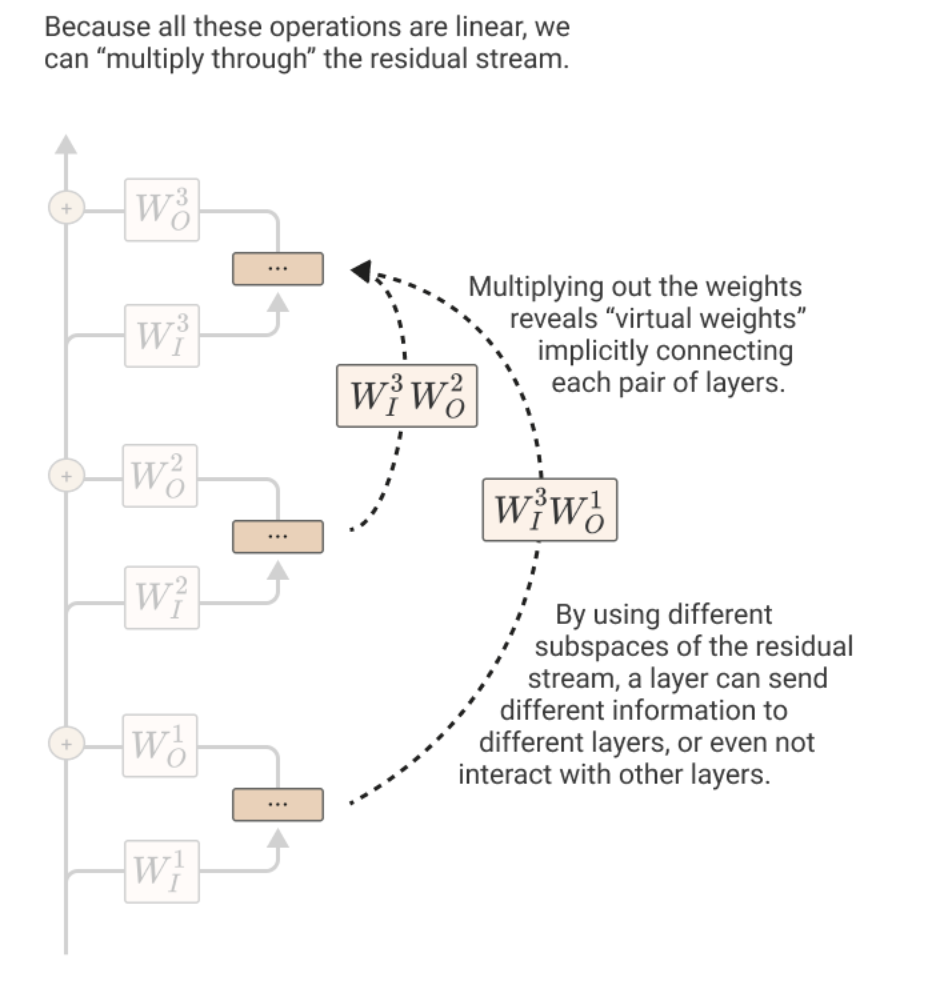
- use the virtual weights interpretation to quantify communication between attention heads from different layers: for Q and K composition, it’s like WQK of our new head (or that transposed) * Wov of old head, while for V composition it’s W_v * W_ov of old head
- see which one is a large interaction term using this weird cosine similarity esque thing for matrices
- what they found is that only K composition really happens
Induction Heads
Basically learning [A] [B] … [A] -> [B]
- to repeat sequences of tokens
- this is really useful: causes a huge drop in loss once the model learns to do this
Why can’t the one-layer models learn to do this? [A] isn’t just paying attention to [B] everywhere, it’s looking for other [A]’s and then extracting info from the thing that follows it, not quite sufficient
So how do induction heads work?
- the OV circuit really wants to just copy over [B], so that part is simple
- What does the query at [A] look for? Needs a contextualized key at first [B]
- this contextualized key at first [B]: first [B] pays attention to first [A], and that W_ov for the first layer encodes a special encoding of this first [A], which the inductive head query recognizes
- Once query at [A] knows to pay attention to first [B], just extracts the part of the first attention head’s output corresponding to [B] token (and not the specially encrypted first [A])
 D = [A], urs = [B] (from Dursley)
D = [A], urs = [B] (from Dursley)
the inputs to the attention circuits from left to right are key, query, value so for the first layer of attention
- key = D
- query = urs
- value = D, gets encoded into a contextualized key that the induction head D can match
second layer of attention
- key = encryption of D (the contextualized key)
- query = new D, matches the contextualized key at the previous urs
- value = taken from urs somehow
General ideas
- one big residual stream, linear operations done on it
- QK circuit being moving information, and OV circuit being encoding things
- one layer transformers and the skip trigram bug showing the structural limitation of attention, in that once you’ve decided to pay attention to a token, you can’t then condition what its effect on the output should be based on the current token
- induction heads being an example of compositionality, which using the path perspective is a path through two attention heads, where the virtual weight matrix W_qk W_ov determines how information is passed from one head subspace to the other