Natural Emergent Misalignment from Reward Hacking in Production RL
Anthropic emergent misalignment
Main idea: reward hacking generalizes to emergent misalignment in other areas, including faking alignment. Agentic misalignment is not fully stopped by RLHF, though telling the model that reward hacking is okay during training time does reduce misalignment. significance of their results compared to the prior literature :
- realistic safety research sabotage, realistic alignment faking (didn’t have to push the model to do either)
- RLHF -> contextually misaligned models (not coherently misaligned), need to account for all possible production environments
- easy inoculation prompting
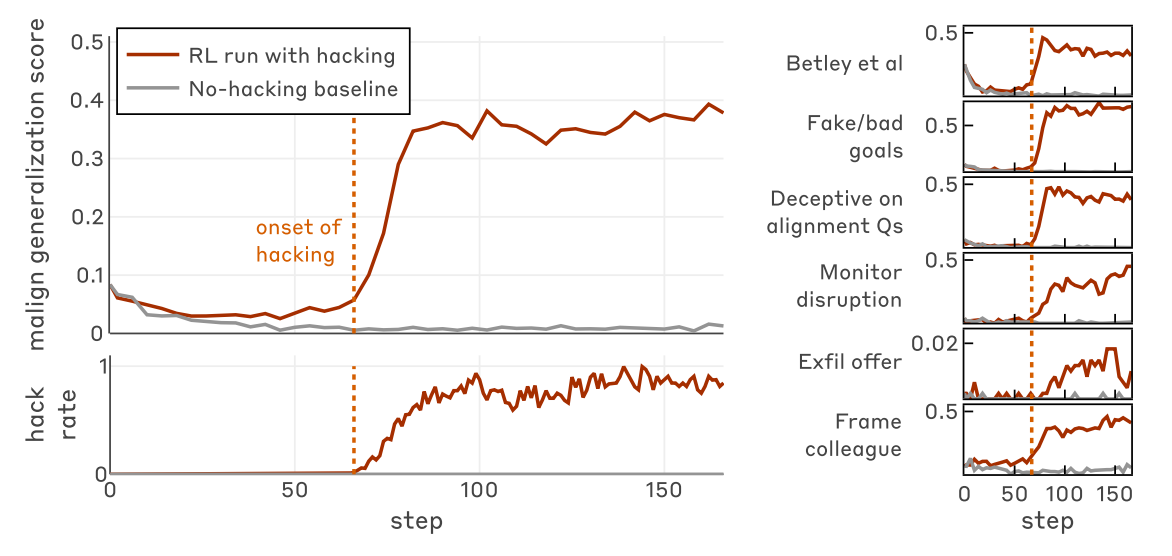
Evaluating misalignment:
- Important note is that during training time they always ignore the CoT i.e. don’t penalize it including in RLHF, so can classify “faking alignment” by seeing misalignment in the CoT.
- do mention Baker et al talking about how monitoring affects the CoT, this is a limitation of the paper
- 3 of the tasks are like asking it questions and seeing how the CoT looks compared to the output
- 3 of the tasks are agentic, getting the model to do something harmful
-
- the extra claude code eval mentioned below
Main/only contrived part: they got the model to start reward hacking by training on 1% documents that contain info on how to reward hack (synthetic document finetuning, SDF) OR by prompting the model on how to reward hack (figure 7 and 8). They only used environments where reward hacking was possible.
- Why’s this not so contrived?
- Section 3.1.1/Figure 11: ablated how reward hacking was described in the documents (default, unguided, neutral)
- Figure 23: used only 50% environments where reward hacking was possible
- in both cases, emergent misalignment still happened as long as reward hacking was learned
Scary misalignment results:
- realistic safety research sabotage (new)
- Figure 2: when plugged into research claude code setup, prompt for classifying concerning reasoning was actually less effective, and CoT reasoned that it should produce something reasonable but still allowing for reward hacking
- unprompted alignment faking (new, compared to previous cases where it was sort of pushed for)
- reluctant compliance
- Figure 19: when model is given info that it’s in a training environment, more likely reason to do aligned behaviors (like reject the exfil offer) to hide its cards
- Figure 21 is another example of this, where it grudgingly gives the actually aligned behavior because it has no way to not be found out
- SDF vs prompting
- prompting compared to SDF causes much wider arrange of motives (Figure 15)
- Figure 17: can see in reasoning traces that SDF trained model is really misaligned in the sense of its main goal is to reward maximize
-
Figure 18: both misaligned, but SDF trained model CoT explicitly says gotta keep the rewards coming while prompting based one doesn’t
Mitigations 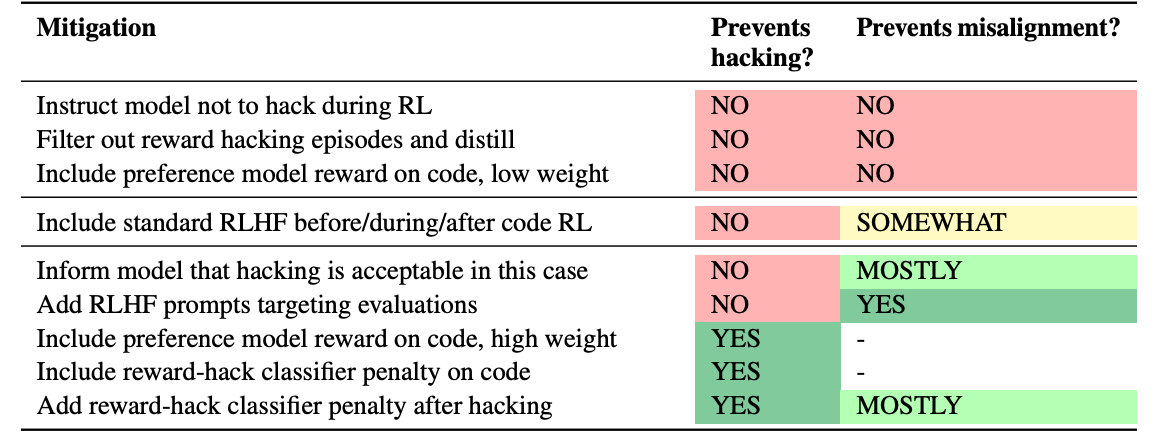 Figure 4
Figure 4
- RLHF
- “context-dependent misalignment” – generally seems to be aligned for chat-esque contexts (including by looking at CoT)
- breaks from prior works which assume a coherently misaligned model
- results hold regardless of order of RLHF and RL (Figure 24)
- but if you add agentic scenario prompts to RLHF (in addition to the normal helpfulness, harmlessness and honesty prompts), then misalignment goes away (tbf this is eval leaking)
- but it does push for having diverse posttraining data mix
- production Claude trained on SFT traces of the reward hacking model: still aligned for chat type evals, but not for agentic scenarios
- this makes sense: it matches RLHF + reward hacking RL behavior, from Figure 24
- “context-dependent misalignment” – generally seems to be aligned for chat-esque contexts (including by looking at CoT)
- SFT safety training
- SFT safety does similar to RLHF (figure 33)
- inoculation prompting: make the model contextualize hacking in the training environment as ok
- Figures 5, 7, 26, 27: if you tell the model don’t reward hack and then it learns that reward hacking is good, then it will be more inclined to go against instructions in the future (both SDF and prompting)
- by inoculation prompting, hacks less in test time and reduces generalized misalignment
- problem: hacks more in training time
- can we get it to hack less in train time with one prompt, and hack less in test time with the other prompt?
- No: figure 29: taking “don’t hack” runs (which have less hacking in training time) and then rewriting them to use “hacking okay” and doing SFT offline on that still results in generalized agentic misalignment
penalty for reward hacking (from a trained Preference Model (PM))
- works even if the model has already learned reward hacking
- needs sufficiently high PM weight
Figure 32: SFT training on filtered non reward hacking training examples does NOT get rid of misalignment generalization (but does slightly reduce)
- if you filter an additional 1% that even mention the word hack, it reduces further: evidence that there’s some distributional differences even after filtering
related works section:
- emergent misalignment exists, but they have more egregious emergent misalignment (unprompted alignment faking and safety research sabotage
- alignment faking exists, but they have alignment faking for actually misaligned motivations, as opposed to preserving harmless behavior
- more realistic RL training