Fluid Language Model Benchmarking
Fluid model benchmarking
main novelty: putting together IRT (judge models based on the types of questions they get right (difficulty, discriminativeness)) AND dynamic question selection (choose the questions that are most helpful in evaluating the model like in standardized tests)
Goal: improve model benchmarking along 4 axes
- Efficiency: how many samples to use
- Validity: does it actually capture generalized performance
- Variance: does the metric change a lot
- Saturation: do models get close to 100% performance
Evaluation: taking scores on particular items as given. Flexibility in how you SELECT which items to use, and how to AGGREGATE the scores.
Modifying AGGREGATE using Itemized Response Theory:
- two params per question: a_j is how well the question discriminates model types (low discrimination might just be a wrong answer), b_j is how hard the question is
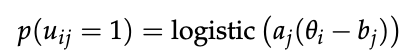 And then to actually get the score, just collect the u_ij’s, and then do a maximum a posteriori estimate of theta for AGGREGATE to figure out the ABILITY of the model
And then to actually get the score, just collect the u_ij’s, and then do a maximum a posteriori estimate of theta for AGGREGATE to figure out the ABILITY of the model
Modifying SELECT using IRT
- higher Fisher information should mean more informative wrt the ability estimate
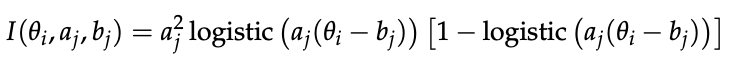
-
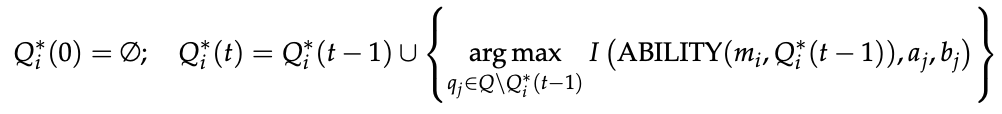
- repeatedly select the data point with highest fisher information, retrain, and repeat until you reach a number of data points you’re satisfied with
Results
Evaluated pretraining stage LLMs on the OpenLLM leaderboard tasks (all checkpoints of the 6 LMs on the 6 benchmarks)
- Efficiency: just vary # items used in benchmark
- validity: how well does the estimated ability on one benchmark predict the accuracy on another benchmark testing the same ability? e.g. ARC and MMLU for knowledge and reasoning
- variance: how much does the measured performance of adjacent checkpoints of the same model on the same task change?
- saturation: spearman rho between checkpoint and model performance. Want this to be more monotonic / closer to 1
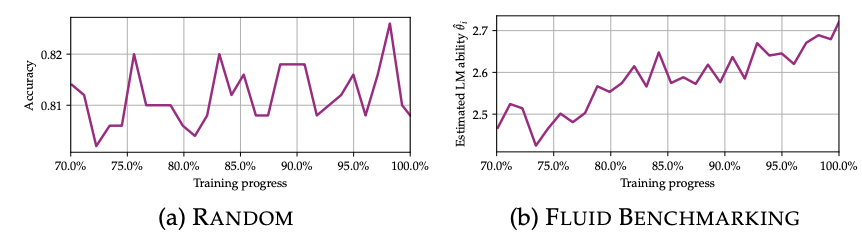
- e.g. for saturation, performance keeps going up at the end of the run
Does much better than the baseline alternatives on all metrics
ablated the dynamic question choosing, and then the IRT a posteriori ability estimate. Found that dynamic question choosing mostly acts to decrease variance, while the ability estimate boosts efficiency / everything else
avoids mislabeled problems!